Megastore: Providing Scalable, Highly Available Storage for Interactive Services
引言
Megastore就是为了解决Bigtable存在的一些问题而产生的,也是基于Megastore而设计的。Megastore在NoSQL的可拓展性上面的实现了传统的RDMS的可用性。当然在Spanner出现后,Megastore被吐槽延时太高等的缺点。这篇Paper还是值的一看的。
高可用性和可拓展性
分区和局部性
为了支持分区,Megastore引入了Entity Group的概念,每一个Group都是独立地跨区域的同步复制。低层的数据保存在NoSQL中,实际使用的就是Bigtable。在一个entity group里面的entity单步骤的事务就可以处理,相关的提交的理解通过Paxos来进行复制。当操作需要跨越Entity Group是就需要2PC来完成事务的操作。
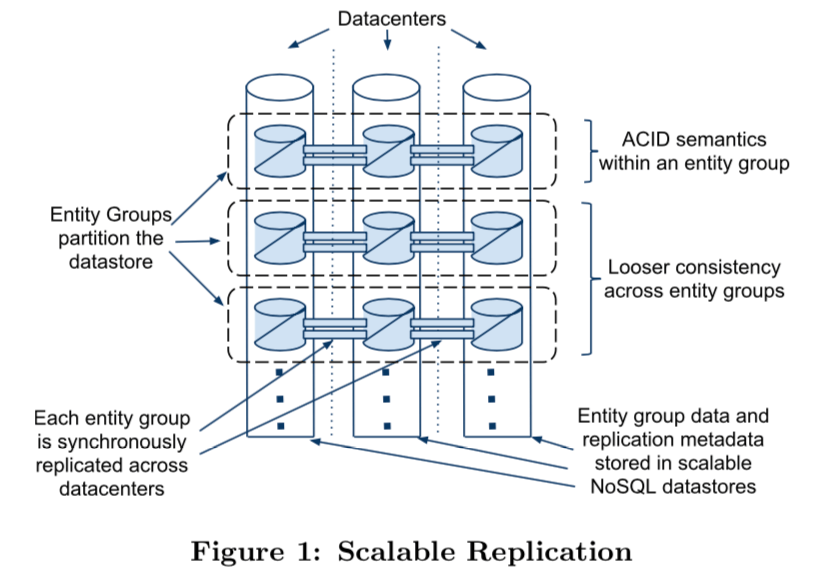
为了优化2PC的操作,Megastore使用异步消息的方式来处理,这些消息通过队列来完成。下面的图就表示了这种方式。这里要注意的是使用异步消息的两者之间的距离是逻辑上的,而不是物理上面的距离,也就是这里的其实就是在一个数据中心里面的,而在不同数据中的操作都是通过同步的复制来完成的。一个Entity Group里面的索引(Local Index,下面的图中有表现)服从ACID语义,而跨越Entity Group的Index一致性是一种弱的一致性。
Note that we use asynchronous messaging between logically distant entity groups, not physically distant replicas. All network traffic between datacenters is from replicated operations, which are synchronous and consistent.
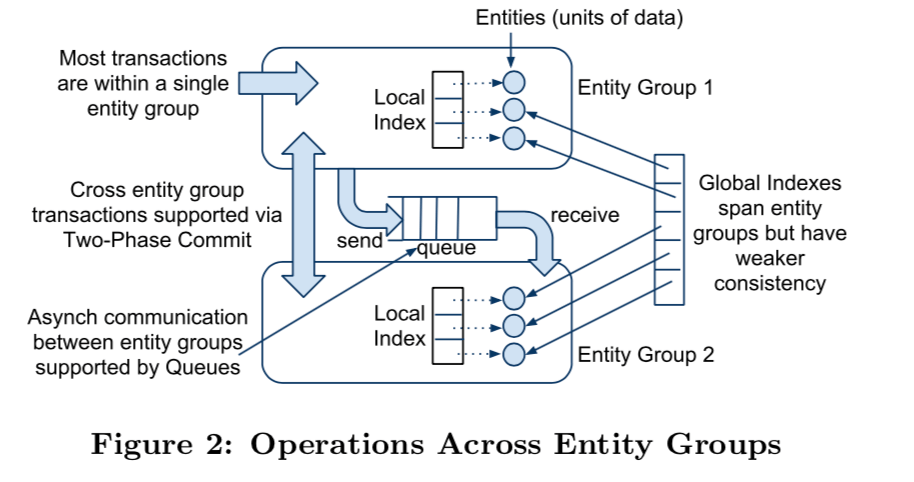
复制
这里主要就是基于Paxos协议的复制。在基本的Paxos上面,Megastore在这里做了很多的优化,
- Fast Reads,这个优化就是使得读取可以读取任何一个副本,因为在大部分的情况下,副本之间的数据是一致的。但是,副本之间不一致得情况也是难免得,Megastore就使用了一个Coordinator保存了目前应用了全部的写入的副本的信息,通过这些信息来决定是否可以Fast Reads。
- Fast Writes,使用基于类似master来实现单roundtrip的写入。Megastore这里实际使用的叫做Leader而是Master,它们之间的区别在与Megastore中的leader更加灵活,Megastore会为每个log position设置独立的Paxos状态机,它们的Leader不一定相同。Megastore会选择例客户端最近的副本做为leader,来提高性能。
- Replica Types,Megastore讲副本类型分为为Full、Witness和Read-Only几种。Full可参与正常的操作,而Witness只用来保存预写的日志,Read-Only的顾名思义就是只用来读取的。
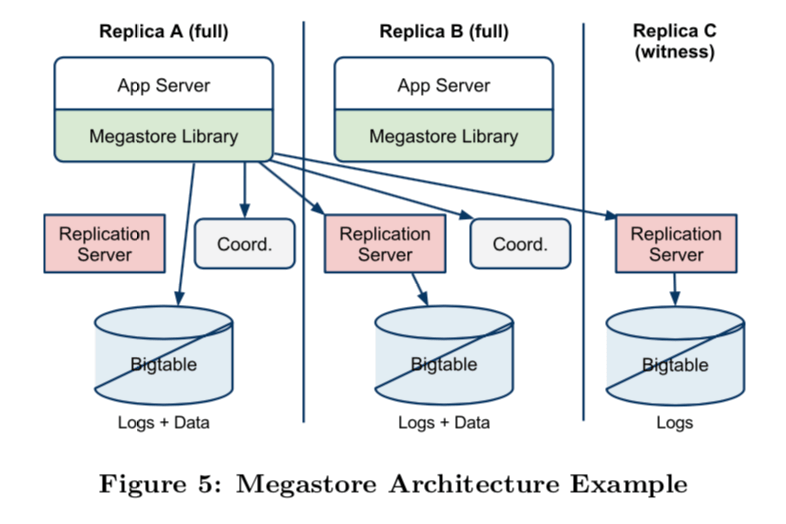
概览
#### API设计的哲学
API设计的哲学直讲影响到了Megastore的设计。这里总结几点如下:1. Megastore强调const透明的API,也就是说API的const要符合开发者的直觉;2. 传统的关系型数据库都很依赖于join操作,这个操作在Megastore上面是不合适的。Join在Megastore这样的基于NoSQL实现的分布式的数据库中实现存在比较多的问题,所以这里是尽量避免使用join操作。为了更好地实现操作不依赖于join,Megastore提供了能更加好控制物理布局、层级layout和声明式的非正规的存储的数据模型和模式语言。 对于必须使用join的情况,Megastore提供一种针对Megastore优化的mege join的join算法。主要的优化是在merge的阶段,这里的优化应该就是在处理多个查询的时候Entity的顺序的问题,
We provide an implementation of the merge phase of the merge join algorithm, in which the user provides multiple queries that return primary keys for the same table in the same order; we then return the intersection of keys for all the provided queries.
另外一种在查找一个初始的结果之后根据这个结果来进行index查找的情况,Megastore实现了一种可并行查询的outer join的算法,优化了初始查询的结果集比较小而次级索引可以并行的情况很有利于提高性能。
数据模型
Megastore的数据模型于SQL的模型很相似,都也不完全相同。这里的数据类型带有很强烈的protobuffer的味道,这可以就是因为Megastore于其它应用交互使用的数据格式就是protobuffer的原因。
CREATE SCHEMA PhotoApp;
CREATE TABLE User {
required int64 user_id;
required string name;
} PRIMARY KEY(user_id), ENTITY GROUP ROOT;
CREATE TABLE Photo {
required int64 user_id;
required int32 photo_id;
required int64 time;
required string full_url;
optional string thumbnail_url;
repeated string tag;
} PRIMARY KEY(user_id, photo_id),
IN TABLE User,
ENTITY GROUP KEY(user_id) REFERENCES User;
CREATE LOCAL INDEX PhotosByTime
ON Photo(user_id, time);
CREATE GLOBAL INDEX PhotosByTag
ON Photo(tag) STORING (thumbnail_url);
因为Megastore架构的特点和实际上它的数据就是保存在Bigtable上面的,Megastore的表中的一个特点就是IN TABLE的语句,这个的目的就是讲Photo的table和User的Table保存到一个Bigtable之中,这个对于提高实际的性能很有好处。这里也可以发现后面的Spanner也继承类似的方式,简而言之就是讲关系比较密切的数据将可能的保存在靠近的地方。Table中的一条记录会对应Bigtable中的一行,Row Key就是这个Table的主键,Table的字段对应的Bigtable中的列。
The IN TABLE User directive instructs Megastore to colocate these two tables into the same Bigtable, and the key ordering ensures that Photo entities are stored adjacent to the corresponding User. This mechanism can be applied recursively to speed queries along arbitrary join depths. Thus, users can force hierarchical layout by manipulating the key order.
索引
前面就提到了Megastore的索引有Local索引和Global的索引。前者是一个Group里面局部的消息,而且它能保证ACID的语义。Global索引的一致性是弱的,但是是跨越Group的消息。索引也是保存为Bigtable中的表,Row Key为有这个索引相关的字段组织得到的一个值,而Value就是主键。
事务和并发控制
和一般的数据系统一样,Megastore也使用WAL,做为保证ACID特性的一个手段。和Percolator一样,Megastore也充分利用了Bigtable提供的支持储存多版本的功能,在此的基础之上实现了MVCC。在隔离的级别上面,Megastore提供current, snapshot, 和 inconsistent的读区。一个concurrent的read能够保证在这个read前面提交的写入都已经被应用了,也就是说这个read能够读取到最新的已经提交的数据。对于snapshot read,系统选择一个已经知道的最后的一个被提交了的时间戳做为读取的时间戳。inconsistent reads则直接读取最新的数据,忽略目前的情况。对于一个写入的操作来时,它总是以一个current read开始,来决定目前可以写入的位置,这里也会保证一个事务提交之前,它的变动会被写入到log之中。Log会使用Paxos来复制。一个完整的事务周期:
1. Read: Obtain the timestamp and log position of the last committed transaction.
2. Application logic: Read from Bigtable and gather writes into a log entry.
3. Commit: Use Paxos to achieve consensus for append- ing that entry to the log.
4. Apply: Write mutations to the entities and indexes in Bigtable.
5. Clean up: Delete data that is no longer required.
Megastore可以使用Queue和2PC来实现跨Entity Group的事务,两者各有特点。Megastore是提倡使用Queue的方式,2PC可以在一些情况下简化使用。
Queues provide transactional messaging between entity groups. They can be used for cross-group operations, to batch multiple updates into a single transaction, or to defer work. A transaction on an entity group can atomically send or receive multiple messages in addition to updating its entities. Each message has a single sending and receiving entity group; if they differ, delivery is asynchronous.
更多的复制的内容
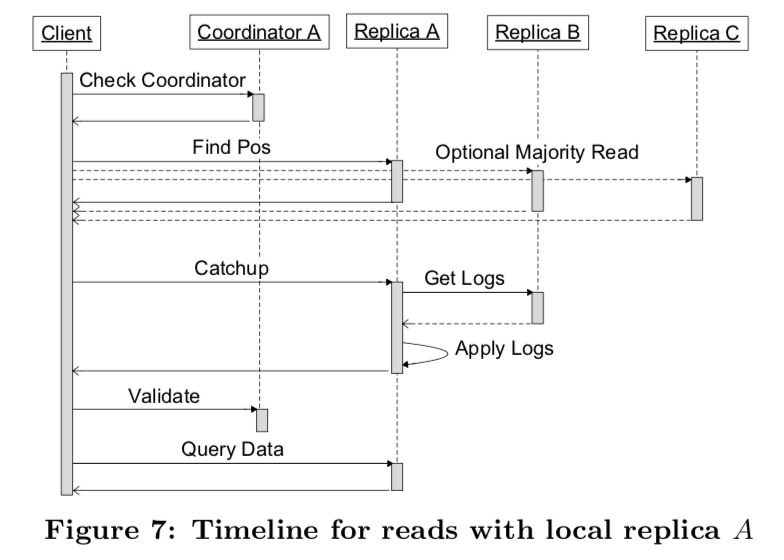
Megastore是乱序提交的,这样也就可能存在某些日志中是存在空洞的。这样Megastore必须处理这类情况。对于一个读取来说,必须有一个副本是“赶上”了最新的数据。缺失的就必须“追赶”上来。流程:
-
Query Local,根据前面提到的coordinator来查看这个副本的数据是否是最新的;
-
Find Position,获取目前的最新的log position,根据这些信息选取合适的副本。如果一个本地的副本就是最新的,那么可以直接从本地的副本中读取最新的log position和timestamp。如果不是,那么就要使用P从超过一半的结点读取的方法。
-
Catchup,数据追赶就是要补齐一个副本缺失的数据。对于选中的副本中不知道一致性值的log position,需要查询其它的副本来获取这个值。对于一个不知道是否提交了的log position,使用一个Paxos的no-op写入的提议来获取,
For any log positions without a known-committed value available, invoke Paxos to propose a no-op write. Paxos will drive a majority of replicas to converge on a single value—either the no-op or a previously proposed write.然后就是应用这些操作是数据追赶上来。
-
Validate,验证。一个被选中的本地的副本如果不是最新的,它就要去查询coordinator,查看对于一个entity group(要读取的group),在这个副本上面是否是最新的。
-
Query Data,使用获取到的timestamp来读取数据,如果这个过程中选中的副本变得不可用的。那么就要换一个重新之下上面的过程。
这里比较(´・_・`),这里主要考虑的就是判断选中副本的数据完整性以及在不完整的情况下如何数据追赶。在正常的情况下,也就是副本数据完整的情况下,操作还是比较简单的。下面是读取的过程图,结合这个图理解更加好,
对于写入来说,前面提到了写操作的前面会是一个current read的读取操作。在读取操作完成之后,它基于可以知道这样的一些信息:1. 下一个没有使用的log position,2. 最后一个写入的时间戳,3. 下一次写入的leader副本。流程:
- Accept Leader,请求Leader去接受提交的值,如果成功了,直接转到Accept步骤,如果没有转至下一步;
- Prepare,这里就是Paxos中的步骤,目的就是让多数的结点得到对于一个值的共识;
- Accept,让剩余的副本接受提交的值,如果失败了,那么在一个随机后退回到Prepare步骤;
- Invalidate,如果一个Group中的一个副本没有接受这个提交的值,那么就要将这个副本从coordinator移除,避免快速读取的时候出错;
- Apply,将改动应用到就可能多的副本上面。如果选定的值和最初提交的值不同,那么像对应的客户端发挥冲突错误;
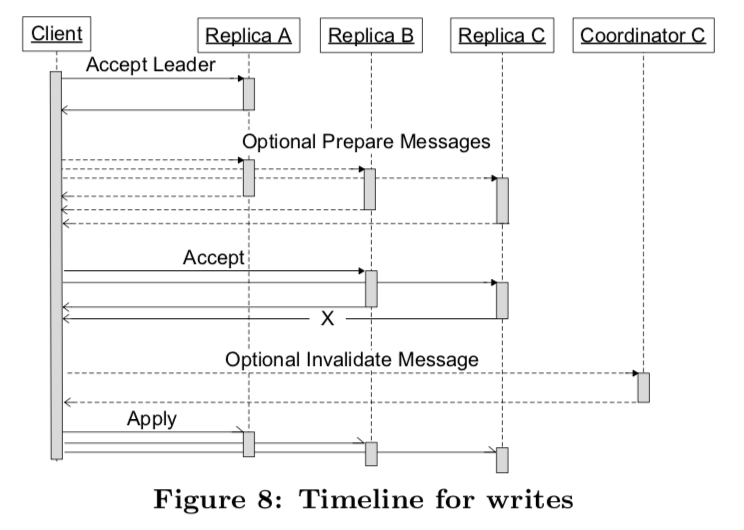
如前文所言,Coordinators会保存数据都是最新的Group,如果没有保持最新,那么就要将其从中移除。为了保证这里写入的正确性,在提交之前必须满足下面两个条件中的一个:1. 这个写入操作被使用的副本接受了;2. 没有接受最新数据得Group从Coordinators中被移除了。 Coordinators是一个机遇Chubby的实现。这里关于Coordinators可以参考[1].
评估
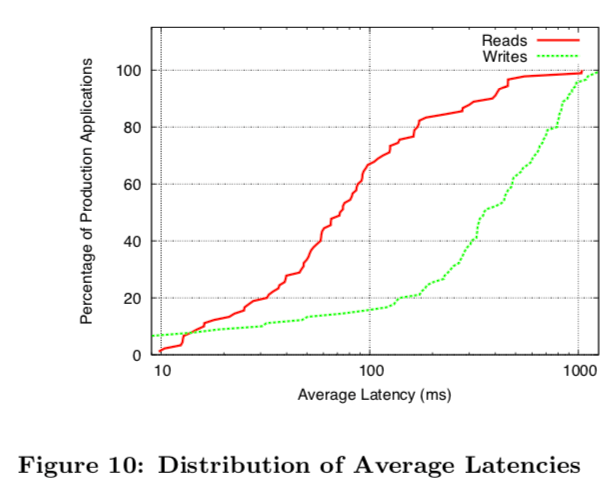
这里的具体信息可以参考[1],从下面的图和Spanner的论文中吐槽Megastore来看,它的latency还是比较大的:
参考
- Megastore: Providing Scalable, Highly Available Storage for Interactive Services, CIDR ’11.
