Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age
0x00 引言
这篇Paper讲的是Hyper内存数据库的查询框架。它主要就是要解决两个问题,一个是如何利用好现在的多核的架构,另外一个就是实现正确的数据统计以便于平均将将任务分配到各个线程(核心)上面。Morsel的英文意思是少量。Morsel-Driven的执行方式就是将任务的数据拆分为大小合适、可动态调整的段,然后按照流水线的方式执行操作。另外,一个DIspatcher负责根据任务执行的一些状态、硬件NUMA的一些解决来合分发任务。还有就是一些优化的Hash Join、分区和排序等的算法,
... Our evaluation on the TPC-H and SSB benchmarks shows extremely high absolute performance and an average speedup of over 30 with 32 cores.
0x01 Morsel-Driven执行方式
Morsel的执行方式是之前每次处理一条记录(数据)的一种优化,能够更好地利用好现在的硬件,比如多核、SIMD等。HyPer内存数据库会将SQL使用JIT的方式转化为机器码执行的方式。在HyPer使用流水线执行的方式,这个流水线的一段会被编译为一段机器代码。Morsel-Driven中,代数的计划执行被称为QEPobject的对象控制,它会将执行的流水线信息传输给Dispatcher。一个操作(比如3个表的Join)会规划为若干的流水线执行,QEPobject会变为每条流水线开辟一些临时存储区域,用于保存其的结果,这里存储区域的分配会考虑到NUMA。 Paper中举例了一个3个表R、S、T 连接的例子,加上T、S表被优化器选择构建Hash Table,而使用R中符合条件的记录去“试探”这个两个Hash Table。
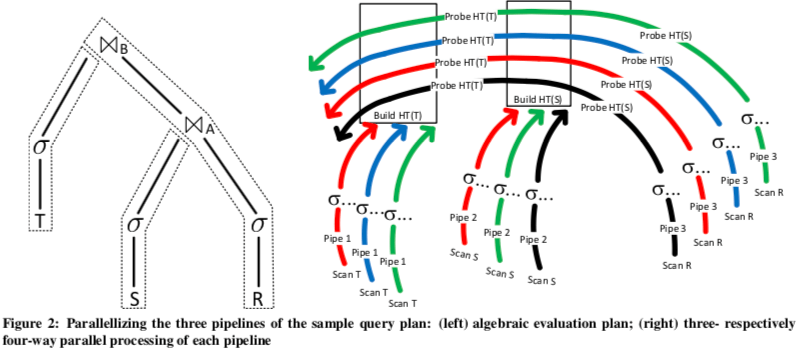
上面的图中左边是执行计划的示意,右边则是执行流水线的示意。这个执行的时候被分为3条流水线,构建两个Hash Table为两条流水线。使用表R“试探”这两个Hash Table又是一条流实现。QEPobject会探知这些操作的依赖关系,这里明显就是Pipe 3依赖于Pipe 1、2的操作。这些操作都是并行的,这里每一个执行的工作线程按照Morsel大小来一块块处理数据,
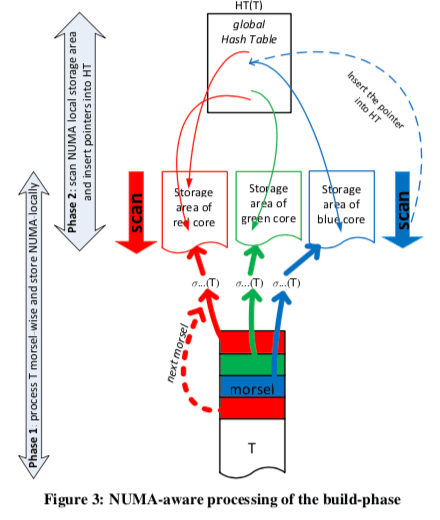
上图即为构建Hash Table的过程。这里的实例操作为3个线程并行操作,每个线程每次处理一个Morsel。基本的表T会以Morsel的方式(Morsel-Wise)储存,这里存储的时候会根据NUMA适当分配保存。一个调度器会将可能地让一个线程处理在同一个Socket的内存的Morsel,尽量避免远程读取内存。
0x02 Dispatcher
Dispatcher控制分配计算资源给流水线。HyPer会为一个硬件线程预先创建一个工作线程,并会设置CPU的亲和性。因此,一个查找任务的并行度由Dispatcher怎么样分配任务个这些工作线程决定(Dispatcher通过分配任务的方式来分配计算资源),一个任务由一个流水线作业和要处理的Morsel组成,在HyPer的测试中,这个Morsel的尺寸一般选择100,000个元组比较合适(在这篇Paper测试的环境和任务下面)。任务的分配主要要优化三个目标:1. NUMA意识,尽量都在一个Socket上面处理,2. 查询的并行性的弹性,3. 负载均衡。下面的图是一个示例,Dispatcher会维持一个待做的流水线作业的列表,这个列表只会包含已经解决了依赖问题的流水线任务。
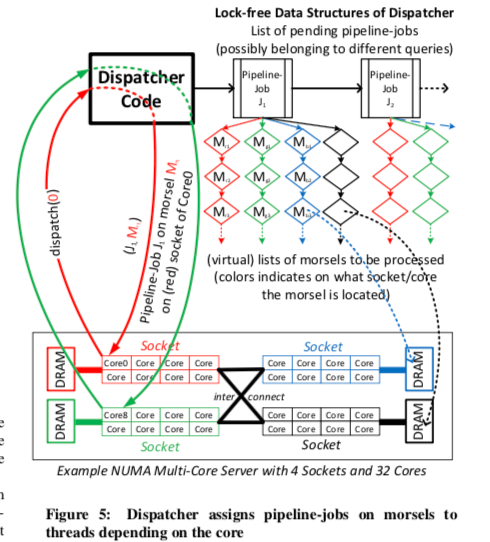
一个分发的任务都是一次处理一个Morsel,这个也是HyPer并行度灵活性的重要的实现方式。对于上时间运行的任务,它可以逐渐增加并行度,另外还可以根据任务不同的优化下决定任务分配的优先程度和并行度。对于每一个流水线作业,Dispatcher都会维持一个待做的Morsel的(虚拟的)列表,而且是根据每一个核心来维持这个列表。当一个核心上面的列表处理完成的时候,它可以处理来自其它核心列表上面的任务,这个也是负载均衡的一种方式。当一个高优先级的任务进入相同时,它可能导致当前的任务的并行度降低,Hyper可以允许在这种情况下重新分配任务。
0x03 并行操作
这里就是针对HyPer的Morsel-Driven执行方式,在一些算法上的优化。
Hash Join
前面举的例子就是Hash Join的例子,其充分利用了Morsel-Driven每次处理一个 Morsel、流水线执行以及多个线程并行执行的方式。在这里Hash Table的构建分为两个步骤:第一个步骤是取出满足条件的元组,保存在线程局部的存储区域中,第二步是在第一步操作完成之后,根据前面获取的数据构建Hash Table,由于这里现在元组的数量是已知的,就可以避免Hash Table的动态增长。另外HyPer还在Hash Table上面做了不少的优化。
NUMA优化的表分区
在NUMA的机器上面,工作现在在绑定的Socket上面运行,这样的话也要去表也应该分区保存在不同Socket节点的内存上面,以便于实现更加好的NUMA局部性。最简单的分配方式就是RR的方式。另外一种方法是根据某些“重要的“字段的Hash值进行分区,在一些场景下面表现更加好。比如使用这个/些重要字段的作为Join Key。
Grouping/Aggregation
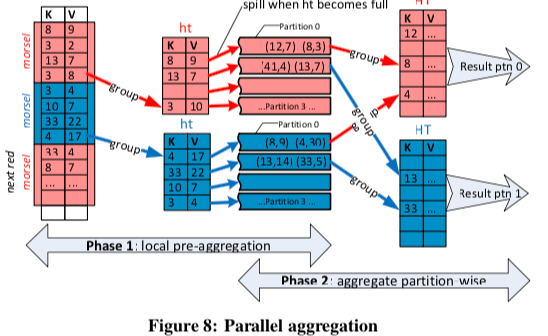
Aggregation的操作在HyPer中也被设计为分阶段执行,一个Pre-Aggregation阶段和一个分区处理的阶段,
In the first phase, thread-local pre-aggregation efficiently aggregates heavy hitters using a thread-local, fixed-sized hash table. When this small pre-aggregation table becomes full, it is flushed to overflow partitions.
The second phase consists of each thread scanning a partition and aggregating it into a thread-local hash table. As there are more partitions than worker threads, this process is repeated until all partitions are finished.
排序
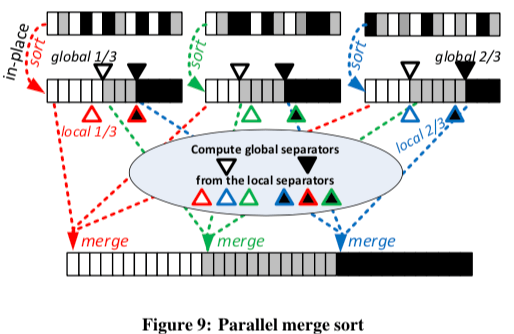
为例实现更好的并行排序,HyPer中使用一种Merge-Sort的变体。首先在线程自己局部的区域排序,然后是一个全局的合并的过程。这里的一个难点就是减少线程间的同步。Hyper使用了分割键的方式(Separator Keys)。在本地排序的时候,工作线程会挑选出合适的分割键,然后把这些具体的分割键合并到一起,计算出全局的分割键。在之后合并的时候根据这些分割键来合并,
After determining the global separator keys, binary (or interpolation) search finds the indexes of them in the data arrays. Using these indexes, the exact layout of the output array can be computed. Finally, the runs can be merged into the output array without any synchronization.
0x04 评估
这里具体的信息可以参看[1],
参考
- Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age, SIGMOD’14.
