Omid, Reloaded: Scalable and Highly-Available Transaction Processing
0x00 引言
Omid是yahoo开发的基于Hbase设计的支持跨行设计的系统,有点像Goole的Percolator。出现的时间晚了不少,架构的设计上也有很多不同的地方。
Omid can serve hundreds of thousands of transactions per second on standard mid-range hardware, while incurring minimal impact on the speed of data access in the underlying key-value store. Additionally, as expected from always-on production services, Omid is highly available.
0x01 基本架构
Omid和Percolator的设计上存在很大的区别,在Percolator中,是没有中心的类似控制器的东西的(control plane),而在Omid中,它的组件主要分为了data plane和control plane两个部分,前者就是Hbase,保存了所有的数据,后者叫做TM(transaction manager),它是一个中心化的结点。
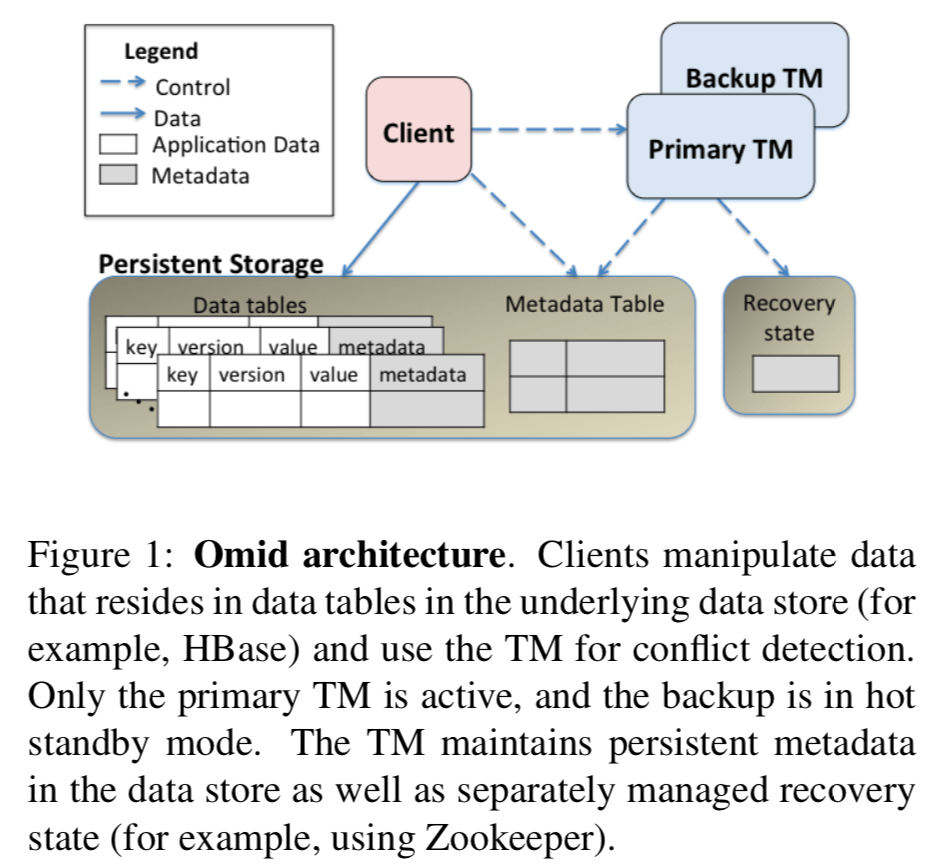
几个特点:
-
通过WAL实习persistence,通过分片实现可拓展性,通过副本实现高可用性;
-
TM在同一时刻是唯一的,但存在副本,数据和元数据都保存在HBase里面;
-
Omid实现的是SI级别的隔离,支持明确地操作某一个版本的数据,例如put(key, val,ver),putIfAbsent(key, val, ver) 和get(key, ver),这些操作都是原子的,
It supports atomic put(key, val, ver) and putIfAbsent(key, val, ver) operations for updating or inserting a new item with a specific version, and an atomic get(key, ver) operation for retrieving the item’s value with highest version not exceeding ver. Specifically, when the item associated with an existing key is overwritten, the new version (holding the key, its new value, and a new version number) is created, while the previous version persists.
- TM扮演者三个角色:1. 版本分配,这里就是时间戳分配,可以理解为这里它将类似Percolator中的Oracle集成在了TM之中;2. 冲突检测,决定那一个事务提交;3. 持久化commits的log。TM使用备份的方式来实现高可用,这种方式很常见了,类似于GFS的方式。TM的存储与计算是分离的,元数据本身是保存在HBase里面的。此外,这里为了解决TM由于长时间的GC导致的假故障,使用了租约的机制,这里依赖于Zookeeper实现。
0x02 Transaction Processing
Omid的使用的并发控制是一种OCC的机制,在提交的时候解决冲突。SI都一般的保持了2个时间戳,一个是开始读时的时候的read timestamp(ts-r),一个提交时候的时间戳commit timestamp(ts-c),这里Omid也不例外,也是使用了这两个时间戳(虽然在不同的地方这两个时间戳的名字有点不同,本质上都是同一个东西),都是TM维持的logical time。
这里Omid将已经提交的事务的信息保存在一个HBas的table里面,叫做Commit Table (CT),在下面的图中有表示。为了快速知道Data Table中的某一个数据已经被提交,表中会有一个Commit Field(cf)字段,如果这个数据已经提交了,那么这里面保存的就是提交的时间戳,如果没有提交(tentative状态),那么就是nil。在提交的时候,事务会将这个字段写入提交的时间戳,然后删除CT里面的对应的数据,到这里这个事务才算执行完成了。注意这里可能出现的故障。这里如果在修改了Data Table的时候崩溃了,一部分数据已经提交(or全部),只要没有成功移除CT对应的记录,就不能算完成,这种情况下会有一个后台的任务帮助这些任务完成提交的操作。

这里以一个简单的事务来说明Omid的事务执行的过程,下面的过程是在客户端操作的,伪代码如下面的图:
-
客户端请求TM,获取一个读区的时间戳ts-r,这个也就是这个事务的事务id(txid),这个时间戳由TM保证它是单调递增额度。
-
put一个key-value时,就是保存为一个待添加到的对象(即这个时候cf字段为nil),同时在write-set里面添加这个key的hash值。使用hash值可以减少数据保存的大小。
-
一个get操作时,这里要分两种情况处理,第一个就是cf字段不为nil,这个时候如何这个提交的时间戳小于自己的ts-r,就可以返回,如果不小于就表明这个数据对于我这个事务来说太新了,不能读取。第二个情况就是即使这个commit字段为nil,它还是可能是被一个提交的事务写入的,只是在改写这个字段的时候没有完成就崩溃了。这个时候就需要去查看CT表,如果在表中发现了提交的记录,那么就将Data Table的这条记录置为已经提交,但是要返回的数据还是要满足时间戳的条件。如果不存在这个提交的记录的话,那么这里还有一个问题要处理。这里存在一种微妙的情况,在下面的伪代码的第23行,重新读区了data store里面的数据,满足要求就返回数据,这里是因为这里没有在CT表里面读出数据的原因是执行写入操作的事务将其移出了。这个时候data store里面的数据就一定会是已经提交的状态,这里重新读取就一定能读出数据。
-
提交,这里要先获取一个提交时间戳ts-c(调用TM的Commut的接口发挥,在这个借口中,TM会检查冲突,具体方法后面说明)。这里体现了Omid的OCC的特点,在提交的时候,使用之前put中添加的write-set里面的hash值来检测释放存在,
The client requests commit(txid, write-set) from the TM. The TM assigns it a commit timestamp tsc and checks for conflicts. If there are none, it commits the transaction by writing (txid,tsc) to the CT and returns a response. Following a successful commit, the client writes tsc to the commit fields of all the data items it wrote to (indicating that they are no longer tentative), and finally deletes its record from the CT.

接下来分析TM的操作:
-
BEGIN(),会分配一个递增的时间戳作为读区时间戳,这个时间戳会返回给客户端,这里需要等待使用的提交时间戳小于这个新分配的时间戳完成操作,即往CT里面写入一条数据,或者是这个事务abort了。
-
后面的一步在TM操作就是提交的操作了,这里也是先分配一个时间戳作为提交时间戳,之后进入冲突检测的阶段(这里需要锁)。使用的就是之前put操作的时候保存到write-set的key的hash值。这里分为几种情况:1. 如果发现了一个更加大的txid对这个hash值代表的key进行了操作,那么只能abort;2. 如果是一个更加小的txid,那么表明这个事务更新,这个时候覆盖之前的数据;3. 上面的情况都没有发生的话,添加新的ts-c。4. 这里第62行处理的问题是,Omid为了限制这个检查冲突的hash table的大小。这里的bucket的大小是固定的,这里就存在之前的信息被覆盖了,这里存在可能的冲突也要abort。这里的操作方式可能造成一些假的冲突,Omid认为这个概率很小,对系统的影响不大。
for each key in the write-set, we lock the corresponding bucket (line 52), check for conflicts in that bucket (line 54), and if none are found, optimistically add the key with the new tsc to the bucket (lines 56–61). The latter might prove redundant in case the transaction ends up aborting due to a conflict it discovers later. However, since our abort rates are low, such spurious additions rarely induce additional aborts. ... Each bucket holds a fixed array of the most recent (key, t-sc) pairs. In order to account for potential conflicts with older transactions, a transaction also aborts in case the minimal tsc in the bucket exceeds its txid (line 62). In other words, a trans- action expects to find, in every bucket it checks, at least one commit timestamp older than its start time or one empty slot, and if it does not, it aborts. -
这里还要处理的一个问题就是CT表里面垃圾回收的问题。这里由后台的进程回收不需要的数据,比如太老版本的数据,abort事务的垃圾数据等。

0x03 High Availability
这里数据的可用性有HBase来保证,TM的可用性由副本来保证。这里还剩要处理的问题就是:1. 在TM故障切换的问题,2. TM的副本误认为现在的TM故障的问题。未来解决这些问题,这里要保证一下的属性:
P1. all timestamps assigned by T M2 exceed all those assigned by TM1;
P2. after a transaction tx2 with read timestamp ts2-r begins, no transaction tx1 that will end up with a commit timestamp ts1-c < ts2-r can update any additional data items (though it may still commit); and
P3. when a transaction reads a tentative update,it can determine whether this update will be committed with a timestamp smaller than its read timestamp or not.
未来满足这些特性的同时实现更加好的性能,这里使用的一些优化方式:
-
引入epoch概念,这里就是一次性分配一个范围内的时间戳,这个方法更常用,在Percolor中也使用了;
-
使用租约的机制解决确认TM故障的问题,备份的TM要等到上一个TM的lease到期之后才能称为新的TM。这里依赖于Zookeeper。
Second, to reduce cost (iii) of checking for invalidations, it uses locally-checkable leases, which are essentially locks that live for a limited time. As with locks, at most one TM may hold the lease at a given time (this requires the TMs’ clocks to advance roughly at the same rate). Omid manages epochs and leases as shared objects in Zookeeper, and accesses them infrequently.
这里还有更加多的细节,可以参考论文6.2 6.3节。HA算法的伪代码描述:

0x04 评估
这里的详细数据参考论文[1].
参考
- Omid, Reloaded: Scalable and Highly-Available Transaction Processing, FAST’17.
