Zephyr: Live Migration in Shared Nothing Databases for Elastic Cloud Platforms
0x00 引言
Zephyr是数据库Live Migration的一个经典的设计。Zephyr的基本思路就是从集合on-demand主动拉取数据和异步数据推送相结合的方式来实现Live Migration。Zephyr在实现数据Live迁移的同时,降低事务abort的概率,最小化数据迁移的负载,同时保证数库ACID的要求,
... We outline a prototype implementation .. . Zephyr’s efficiency is evident from the few tens of failed operations, 10-20% change in average transaction latency, minimal messaging, and no overhead during normal operation when migrating a live database.
0x01 基本思路
Zephyr面向的数据库架构为标准的Shared Nothing架构,使用两阶段锁协议,使用B+ Tree之类的基于Page的索引结构。客户端与query routers链接,这个query router隐藏了数据库的物理位置,方便后面的数据迁移以及实现其它的功能。Zephyr这里讨论了其它的两种方法,1. Stop and copy,这种的方法最简单,给系统带来的影响也最大。它的做法就是停止整个系统的运行,然后执行迁移,在迁移完成之后重新开始运行,2. Iterative State Replication,对系统先做一个checkpoint,将在这个checkpoint之内的数据迁移。在这个过程中,源服务器继续处理请求。在Checkpoint里面的数据都同步过来之后,这里就需要暂停一下服务了,将迁移checkpoint期间产生的delta数据迁移过来,之后迁移基本就完成了。这里也和一些虚拟机live迁移的方式类似。
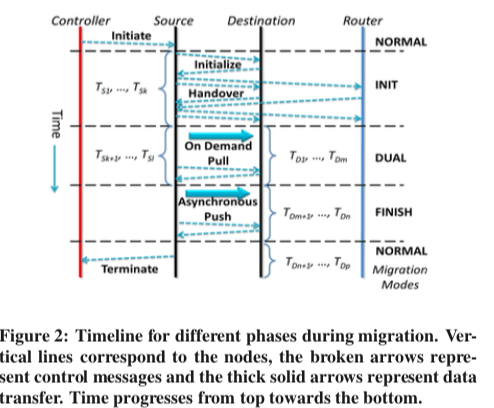
在Zephyr中定义的一些符号表示如下,
D-M: The tenant database being migrated
N-S: Source node for D-M
N-D: Destination node for D-M
T-Si,T-Di Transaction executing at nodes N-S and N-D respectively
P-k Database page k
Zephyr中的数据迁移分为INIT、DUAL、FINISH和NORMAL几个状态,
- INIT Mode,在这一步,N-S通过向N-D发送wireframe信息来启动N-D。这里的wireframe主要包含了Schema和数据定义、索引结以及用户和权限等信息。在这里,N-S依然负责处理所有的数据请求。在N-S收到了这些信息之后,基本的元数据N-S都以及知道了,但是这个时候数据都还在原来的节点上面。在迁移的时候,数据页的迁移时逐渐进行的,所以N-S和N-S都维持了一个所有权在自己的数据页的一个链表。在N-D准备完成的时候,它会通知N-S,然后N-S就会执行一Atomic Handover协议,来通知query routers将对应的请求发送到新的节点。
- Dual Mode,这里的时候,N-S和N-D同时执行事务。在N-S上面会执行在这个模式开始的时候出于active状态的事务,在N-S上面执行事务的时候,在遇到已经迁移到N-D的数据页之前,它会按照正常的方式执行。在遇到了一句迁移的数据之后,这个数据访问会失败,这个事务被abort。在N-D上面执行事务的时候,如果遇到一个没有迁移的数据页的时候,它会去请求N-S,将数据页拉取过来。这个时候如果这个数据页被锁住了,这个拉取钱去必须达到锁被释放,如何才能继续进行迁移。一个数据页迁移之后,两个节点都要更新它们的所有权的信息。只有在这种情况下,两个节点才会同步。在执行了这个Model开始阶段还处于active状态的事务之后,N-S,N-D交换信息进行下一个阶段。
- Finish Mode,在这个节点,对应的请求只会在N-D上面执行。但是不一定所有的数据Pages都以及迁移过来了。N-S会主动将还没有迁移过来的数据页推送给N-D。同样地,在需要的时候还是需要主动pull拉取数据页。
- Normal Mode,在上一步完成之后,迁移完成,加入正常执行的状态。
0x02 正确性 和 容错
Zephyr在Paper中提出了几条Lemma来说明来Zephyr的正确性,Lemma的具体证明可以参看[1],
- Phantom的问题,在内部索引节点使用Local predicate锁和在外部的数据页使用排他的Page级别的锁就能够保证不会出现Phantom的问题。
- Serializability,一个节点内执行的事务不会出现环形冲突(have a cycle in the conflict graph),这里主要由2PL来保证。
- N-S和N-S两个节点上面分别实现的事务不会出现T-Di → T-Sj这样的conflict dependency。??
- 在Dual Mode的时候也不会出现环形冲突have a cycle in the conflict graph of transactions executing)
在容错方面,这里包含了比较多的很细节问题。故障之后的恢复主要包含了两个方面的内容,一个是事务状态的恢复,一个是迁移状态的恢复,
-
事务状态的恢复页主要依赖于数据库中常用的WAL。处理WAL之外,这里还要处理另外的问题,在Dual Mode下面,事务的日志会分散保存在N-S和N-D上面。两个不同的事务访问同一个数据Page的时候,就需要进行同步操作,如前面所言。在迁移的时候,每一个事务在提交的时候会被赋予一个CSN,即Commit Sequence Number。CSN单调递增。在N-D请求一个页的时候,N-S会捎带上CSN(TS),在收到了一个数据页的时候,N-D会将自己的CSN设置为本地的CSN和带过来的CSN中的较大的值。这样就设置了一个访问一个数据页的全局的顺序,在此CSN之前为N-S上面记录的顺序,而后面就是N-D上面记录的顺序,
We formally state this property as Theorem 6: THEOREM 6. The transaction recovery and the conflict ordering protocol ensures that for every database page, conflicting transactions are replayed in the same order in which they committed.
在迁移状态的恢复上面,这里涉及到的细节比事务状态恢复多很多。在Paper中这里讨论了四个细节的问题,
- Transitions of Migration Modes,
- Atomic Handover,
- Recovering Migration Progress,
- Failure and Availability
迁移的Safety 和 Liveness也是Paper中详细讨论的问题,这里Zephyr保证了这样的一些特性,1. 事务持久化,2. 迁移一致性保证,3. 迁移终止保证,4. 不会有饥饿问题来保证了Safety 和 Liveness。这些在Paper中页给出了具体的证明[1]。处理前面讨论的Zephyr的内容,Paper还讨论了Zephyr的优化和拓展的几点,1Tenants复制、Tenants分片以及Dual Mode中的数据共享等。
0x03 评估
这里的具体信息可以参看[1].
“Cut Me Some Slack”: Latency-Aware Live Migration for Databases
0x10 引言
这篇Paper也是关于数据库Live迁移的一个研究,与前面的Zephyr使用的方法不同,这里使用了类似于数据库迁移的方法。另外这篇Paper的一个重点就是在迁移的时候感知数据库目前运行的状态,自动适应以减少数据迁移给系统运行带来的影响,
Using our prototype, we demonstrate that Slacker effectively controls interference during migrations, maintaining latency within 10% of a given latency target, while still performing migrations rapidly and efficiently.
0x11 基本思路
在迁移的方式上面,“Cut Me Some Slack”没有什么特别的地方。这里采用了一些虚拟机迁移使用的方法。首先为迁移初始化阶段,初始化完毕之后,执行一个快照传输,将数据库的一个快照传输到新的节点上面。在这个时候数据库还会继续处理请求。之后进入delta updating,这个时候会同步在传输快照数据时候产生的新的数据,最后的为一个handover的操作,这个时候会冻结源端的操作,通常这个时间会非常短。次方法称之为snapshot-delta-handover。
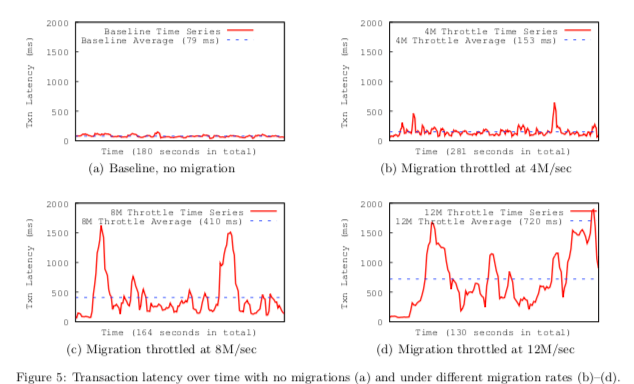
“Cut Me Some Slack”这篇Paper迁移方法之外,还主要讨论了迁移给数据库运行带来的影响。Paper中给出了一些例子,如上面的图所示。在没有数据迁移的时候,事务运行的Latency很小也比较平稳。当进行迁移的时候,随着迁移速度的增大,latency变得更大,而且越来越不平稳。而“Cut Me Some Slack”就是主要来解决这个问题,所以称之为Latency-Aware Live Migration。这里将这个迁移的速来称之为Throttling,“Cut Me Some Slack”使用一个proportional-integral-derivative controller控制器(PID)来动态控制数据迁移的Throttling。
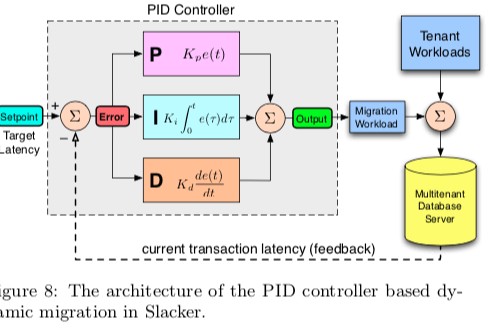
这里使用的PID算法并不是这篇Paper提出的算法,PID基本的工作原理如上图所示。PID实际上就是一个连续的反馈循环。输入反馈信息,输出一个计算结果,这个计算结果中主要包含了3部分的结果, \(\\ out(t) = K_pe(t) + K_i\int_0^t e(\tau)d\tau + K_d\frac{de(t)}{dt}\) P表示比例部分,I表示积分部分,D表示微分部分。代表了不同类型的估计,
... Roughly speaking, P corresponds to the current error, I corresponds to the past error, and D corresponds to the predicted future error. The output of the controller at time t with error e is given by the sum of the three components:
0x12 评估
这里的具体信息可以参看[2].
参考
- Zephyr: Live Migration in Shared Nothing Databases for Elastic Cloud Platforms, SIGMOD ‘11.
- “Cut Me Some Slack”: Latency-Aware Live Migration for Databases, EDBT ‘12.
- Rocksteady: Fast Migration for Low-latency In-memory Storage, SOSP ‘17.
- ProRea: Live Database Migration for Multi-tenant RDBMS with Snapshot Isolation, EDBT/ICDT ’13
