Exploiting Commutativity For Practical Fast Replication
0x00 引言
这篇Paper是NSDI ’19最有意思的一篇文章之一。以Paxos为代表的分布式一致性的算法,很大的一部分就是要处理网络的丢包和乱序的问题。而在对这样的算法优化的方向,有对算法工作流程进行优化的,比如Fast Paxos。另外就是从另外的方面着手,但是直接对网络丢包改进的几乎没有,一般都不能加上网络是可靠的。而多从顺序这里出发,比如NOPaxos,利用网络来对发出的消息进行定序。而这篇Paper中提出的思路是开发操作之间的可交换性,比如对于以Key-Value Store来说,如果一组的更新Key的操作,如果操作的都是不同的Key,那么只要这要操作最终都被执行了,系统最终的状态是和操作的顺序是没有关系的。通过让操作“乱序执行”,去除了1个RTT,提高系统的性能,
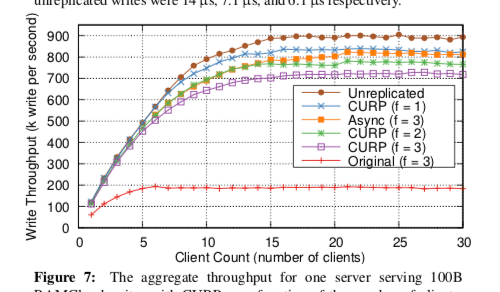
In RAMCloud, CURP improved write latency by ∼2x (14 μs → 7.1 μs) and write throughput by 4x. Compared to unreplicated RAMCloud, CURP’s latency overhead for 3-way replication is just 1 μs (6.1 μs vs 7.1 μs). CURP transformed a non-durable Redis cache into a consistent and durable storage system with only a small performance overhead.
0x01 持久化和顺序分离
复制协议一般都要保证两个性质来保证系统的正确性,1. 一致的顺序,如果一个副本在操作b之前完成了操作a,没有客户端可以在看到了b操作的效果但是没有看到操作a的效果。2. 一旦一个操作向外表示操作以及完成,那么操作在crash之后也必须还是存在的。常见的方法比如有strong leader角色的协议,比如Multi-Paxos和Raft协议,客户端通过请求Leader然后Leader给这些操作来安排一个统一的顺序,然后将这些信息复制到其它的副本。这里样的至少需要2RTT来完成这些操作,第一个就是客户端请求Leader/Master,另外一个就是Master/Leader将这些信息复制到其它的副本。Fast Paxos 和 Generalized Paxos优化点就是采用之一种乐观的复制方法,不过这里最终还是要Leader/Master来处理,
Fast Paxos and Generalized Paxos reduced the latency of replicated updates from 2 RTTs to 1.5 RTT by allowing clients to optimistically replicate requests with presumed ordering. ... leaders must still wait for a majority of replicas to durably agree on the ordering of the requests before executing them. This extra waiting adds 0.5 RTT overhead.
另外的Network-Ordered Paxos则要依赖于特殊的硬件来实现1RTT。而这里CURP则将顺序和持久化分开。顺序和持久化分开的思路在之前SOSP ‘13上面发表的OptFS文章也是类似的思路,提出dsync和osync来分开处理持久化和顺序。为了实现1RTT的操作,CURP中的客户端直接将它们的数据保存到称之为Witness的节点之中,这里只会持久化保存信息,而不是保存操作之间的顺序关系。而在Master上面保存的操作是包含了顺序信息的,这些信息会被异步地复制到Backup节点上面。这样客户端就不需要等待Master做额外的操作,只需要Master处理请求完成就可以直接返回给客户端,从而实现1RTT。
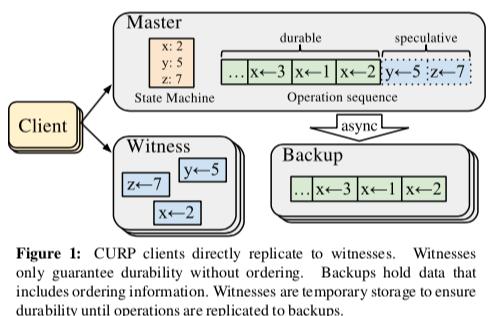
这样的处理方式也到来了另外的两个问题,第一个就是顺序,比如在Master崩溃之后,操作之间的顺序关系会被丢失,第一个就是重复。所以在提出了上面的CURP的基本思路之后,CURP协议在很大的一部分内容就是处理这两个问题。对于顺序的问题,第一个处理的方法就是commutativity,及操作之间的可交换性。对于那些称之为unsynced的请求,即那些客户端认为操作已经完成,但是还没有被复制到backup节点上面的请求。对于这些请求,在CURP中的限制就是这些请求必须满足可交换性。特别地,对于Witness节点来说,它们只会接受只会接受和保存和目前保存在此节点上面的请求满足交换性的请求,比如在KVS中,更新Key的操作都是操作不同的Key。而如果不满足这些请求,必须执行sync的操作,
... a master will only execute client operations speculatively (by responding before replication is complete), if that operation is commutative with every other unsynced operation. If either a witness or master finds that a new operation is not commutative, the client must ask the master to sync with backups. This adds an extra RTT of latency, but it flushes all of the speculative operations.
这里的另外一个问题就是duplication,这里使用的方法就是另外的一篇Paper中的方法[3].
0x02 CURP协议
CURP的架构如下,其中的Witness和Backup的角色可以实际上就是同一个节点。分为已经确定了顺序的部分,另外的一部分就是没有对顺序达成一致的部分。CURP本质上是一种Primary-Backup的协议,在这里一般为f+1的模型,1即为Master。在正常的情况下,CURP的操作操作都比较简明,
-
正常情况下,客户端就是直接使用RPC请求这些Master和Wirness节点。请求Master和Witness都是并发进行的,在下面的图中,客户端请求Master的请求称之为execute,而请求Witness的操作我record。客户端只有在所有的f个Witness都符合可以且从Master请求返回的情况下,才能认为操作完成并且已经持久化。如果Mitness返回不能处理,则需要项Master请求一个sync请求。这样就导致了坏的情况下需要2RTT或者是3RTT才能完成操作。如果在这里无法接受到sync请求的返回,客户端重启整个过程,重新操作。这个时候可能Master除了故障。
-
Witness的角色在这里处理record的RPC请求,它这里在返回一个record的请求是,必须保存请求已经被持久化了。不同的Witness之间为独立操作。这里Witness还要处理的问题就是它目前记录的这些请求之间的可交换性。如何确定这些操作的可交换性在一些情况下比较容易处理,比如早Key-Value的存储中。在另外的一些环境下,处理起啦就比较困难,比如如下的SQL语句,
... it is impossible to determine the commutativity of “UPDATE T SET rate = 40 WHERE level = 3” and “UPDATE T SET rate = rate + 10 WHERE dept = SDE” just from the requests themselves. To determine the commutativity of the two updates, we must run them with real data.Witness的数据不必要一直保存,Master会通过GC的RPC请求来释放Witness中不会在被使用的数据。这些数据一般都是那些已经同步到了Backups上面的数据。
-
Master在CURP中角色和常见的Primary-Backup系统中的角色类似。Master接受来自客户端的RPC请求,给这些请求安排一个统一的顺序,然后执行这些请求。Master异步地将这些信息同步到Backup节点上面。Master在知道一些没有同步到Backup节点上面的操作无法满足可交换性的情况,必须执行sync操作来同步操作的顺序关系,避免可能出现的不一致的情况。
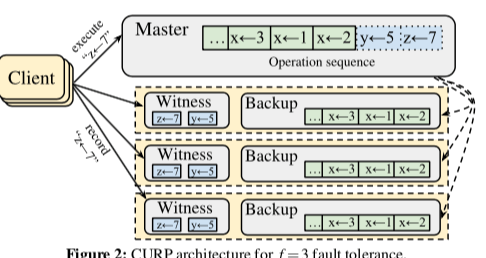
恢复操作
CURP中从Master故障中恢复主要分为两个阶段,1. 利用副本恢复,2. 还要重放witness中的数据。第一步是新的Master从原来的副本中取回全部的数据(这里新的Master也应该一般来自于原来的副本)。如果所有的Backup对于新的Master都是不可达的,那么新的Master必须等待。新的Master可以选择任意的Witness来重放数据,这里得益于操作之间的可交换性。在Master选择了其中的一个Witness来恢复之后,Master会让这个Witness停止处理新的请求,这样是为了避免在一些情况下客户端错误地完成了一些操作。上面的操作完成之后,将数据同步到Backups,设置新的Witness,之后新的Master就可以处理新的请求了。处理数据重复依赖于一种精确投递一次的语义。这里主要还是利用[3]中的方法。
Reconfigurations
CURP协议还包含了处理集群变更的问题,
-
CURP在处理Backup故障的方式上,就可以使用一般的Primar-Backup协议使用的方式,这里实际上和CURP协议没有很大的关系,不是CURP协议中新的内容。
-
对于Witness故障 或者是 没有反应时,System Configuration Manager会将这个可能存在问题的Witness排除出去,然后指定一个新的Witness。这里必须要通知Master,然后让Master将还没有同步到Backups的数据同步到Backups上面去。另外,客户端缓存了Witness的信息,它缓存的可能是过期的信息。这里解决这个问题的方式也是引入了一种版本的方式。在CURP中,维持了一个单调递增的版本号WitnessListVersion。客户端在请求Witness信息的时候,会随着返回这个版本号的信息。客户端在请求的时候,也会带上这个版本号的信息,这样Master就可以探知客户端使用的信息是否是过期的,
On all update requests, clients include the WitnessListVersion, so that masters can detect and return errors if the clients used wrong witnesses; if they receive errors, the clients fetch new witness lists and retry the updates. -
为了处理负载均衡的问题,Master可以将数据分区。另外还引入了分区迁移的机制,
Migrations usually happen in two steps: a prepare step of copying data while servicing requests and a final step which stops servicing (to ensure that all recent operations are copied) and changes configuration.
读操作
CURP中读的操作主要要讨论两个问题,第一个就是直接读取Master时候检查操作之间的可交换性的问题,另外的一个就是利用Witness和Backups读取数据来降低Master的压力,
- CURP读操作这里要处理的一个中要的问题还是可交换性的问题。读操作一般都是直接读取Master的数据。在读操作的时候,Master必须检查这个操作是否和现在的unsynced的操作满足可交换性。如果不能满足,则需要Master将这些数据同步到Backups上面才能处理这个读请求,从而保证在Master故障情况下不会出现不一致的可能。
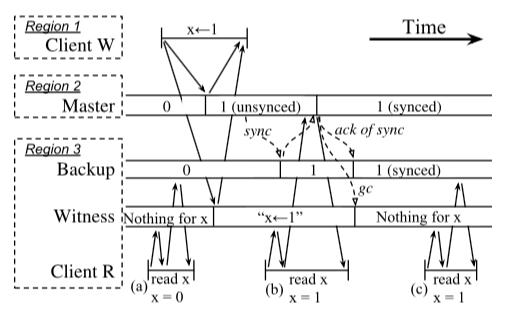
- 从前面的CURP中的工作流程可以看到,一个Witness加上一个Backup是拥有全部的数据的。这里特点也就是为客户端不直接读取Master提供了可能。这里客户端可以直接请求Witness读取,由于它这里是保存的数据中,如果存在,则会是最新版本的数据。如果没有,则可以在去请求Backup。这里如果Witness和Bacup实际上是同一个节点,则更加好用,下图是CURP中一个工作的流程图,体现了CURP中包括这个在哪的工作方式,
0x03 实现
处理CURP协议的基本设计,这篇Paper还说明了在RAMCloud和Redis上实现CURP的内容。讨论了实现CURP的几个具体的方面,
-
Witness,设计到Witness的借口如下,
// CLIENT TO WITNESS: record(masterID, list of keyHash, rpcId, request) → {ACCEPTED or REJECTED} Saves the client request (with rpcId) of an update on keyHashes. Returns whether the witness could accomodate and save the request. // MASTER TO WITNESS: gc(list of {keyHash, rpcId}) → list of request Drops the saved requests with the given keyHashes and rpcIds. Returns stale requests that haven’t been garbage collected for a long time. getRecoveryData() → list of request Returns all requests saved for a particular crashed master. // CLUSTER COORDINATOR TO WITNESS: start(masterId) → {SUCCESS or FAIL} Start a witness instance for the given master, and return SUCCESS. If the server fails to create the instance, FAIL is returned. end() → NULL This witness is decommissioned. Destruct itself. -
Commutativity Checks,
-
Garbage Collection,
-
Recovery Steps,
-
Zombies,这里主要就是处理一个节点的被认为故障,功能被其它节点取代,但是实际上没有故障的节点。
0x04 评估
这里的具体信息可以参看[1],
参考
- Exploiting Commutativity For Practical Fast Replication, NSDI ‘19.
- Optimistic Crash Consistency, SOSP’13.
- Implementing linearizability at large scale and low latency, SOSP ‘15.
