NVWAL: Exploiting NVRAM in Write-Ahead Logging
0x00 引言
这篇Paper讲的是在SQLite的WAL在NVRAM下面的一个优化。这篇Paper讲的核心的优化点可以总结为四点,
- Byte-granularity differential logging,之前常见的日志是以Page写为单位的,这里的differential类型的日志只会每次记录B-treePage的改变,而不是整个Page。这里利用的是NVRAM可字节寻址的特性;
- Transaction-aware memory persistency guarantee,优化NVRAM中使用Cacline Flush;
- User-level NVRAM management for WAL,直接在用户空间管理NVRAM空间;
- Effect of NVRAM latency on application performance,
0x01 基本思路
NVMAL优化对象是SQLite,这里主要讨论的是它的WAL的优化,
-
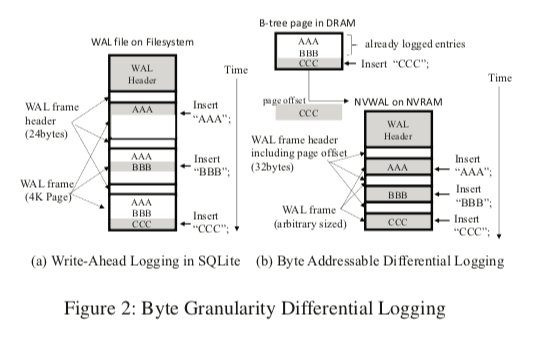
字节粒度的differential logging,这个优化是很有意思的一个优化。不过利用NVRAM的可字节寻址的特性来优化WAL之前的研究也不少,differential logging式的日志页游研究,总的思想来也没有很多特别的地方。如下图所示,图a中几次对一个page的操作造成了一个Btree Page被写入多次,这个也是在这样的环境中常见的写入放大的问题。而图b的思路就只会记录Page变化的信息。它的基本结构也是一个WAL Frame拖部分组成,后面的payload则和前面的方式不同,它的大小是不确定的。Payload就是记录变化的信息,header里面会记录一些元数据和next_frame,即执行下一个WAL-Frame的指针。
-
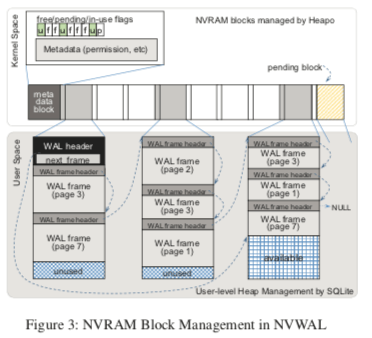
用户空间的NVRAM Headp管理。这里NVRAM资源管理利用前面的一篇Paper,Heapo。这里是一个类似二维数字的结构。可以理解为这里会一次性分配一个比较大的块。这些块用另外的一个数字来管理。分配的块中会写入多个WAL Frame,不同的WAL Frame中会通过指针相互连接,这个就是前面提到的WAL Header中存在的next frame指针。这个block会存在三种状态,free, in-use, 和 pending。Free表示一个block为空闲的block,可以以后被使用,pedding的还有就是这个内存块中的空间已经被使用,in-use即使目前被使用的block。这里又有一些slab的意思,不过这里保存的对象会是不定长的。
Transaction-Aware Memory Persistency Guarantee
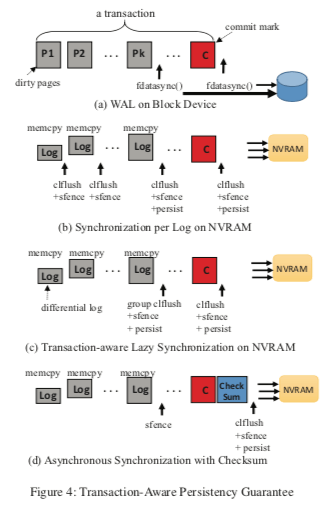
这部分应该是这篇Paper最有意思的一部分了,前面的部分没有太大的意思。在传统的块设置中,保存写入的数据已经持久化的方式是利用fysnc 或者是 fdatasync。而在NVRAM中,作为字节寻址的设备使用的时候,写入的数据保存已经持久化常用的方式是刷CacheLine。在下面的图中,图a是块设备常用的方式。而图b中,利用clflush和fence等的操作是常见的方式。而在这篇Paper中认为,使用这类操作来保存持久化和顺序性对性能的影响太大了。后面的两个是这里提出的两种优化的方式,
- transaction-aware memory persistency guarantee,一般的一个日志提交操作包含了两个阶段,一个是顺序写入日志数据,第二步就是提交标示,表示这个日志是合法的一句提交的日志。这里必须利用clflush, sfence, 和 persist barrier之类的操作来保存正确性。而这里NVWAL讲这两部分的操作分开。提实录memcpy在NVRAM中写入数据和利用一个cache_line_flush (p)来同步。如下面的图C表示。这里的思路简单的就是lazy同步,将同步推迟到事务提交的时候。这个就是Transaction-Aware的意思?从下图c来看,其sfence和persist操作会被图b的“更晚”一些。这里整体的思路就是只会保证两个阶段的顺序,而不会保存不同log写入的顺序。
- Asynchronous Commit,即图d的表示,其区别是更少的persist操作。这里引入了另外的一个数据就是checksum。图b中的做法是在logging阶段和提交阶段不使用barrier。这里使用checksum,NVAMAL异步写入日志数据、cmmit mark和checksum,而不会执行cache line flush的操作。在系统commit mark一句写入导致日志却没有写入的情况下系统crash的话就可以通过checksum来发现,从而确定这些相关的事务没有提交,而丢弃这部分的数据。这里在两个阶段之间省掉了clflush的操作,不过这里还是得保存事务提交的时候数据一句完全持久化了。
0x02 评估
这里的详细信息可以参看[1],
Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using Cross-Referencing Logs
0x10 引言
前面的NVWAL的Paper重点是优化关系型数据库WAL在NVRAM下面的性能表现。这篇Paper则是在Key-Value Store下面Log的优化。索然 persistent memory (PM)这类的存储设备性能比一般的块存储设备性能通过了很多,但是和DRAM相比,它的性能还是差了一些。而这篇Paper就是提出在PM这类存储设备下面的优化。这里主要的优化思路是利用叫做cross-referencing logs (CRLs)的方法,即一种保持,
For pathological write-heavy workloads, Bullet’s throughput is comparable to or better than that of HiKV and its operations’ latency is approximately 25 − 50% lower. Relative to a volatile K-V store, Bullet’s latency and throughput degrade by approximately 50% under write-heavy workloads.
0x11 基本思路
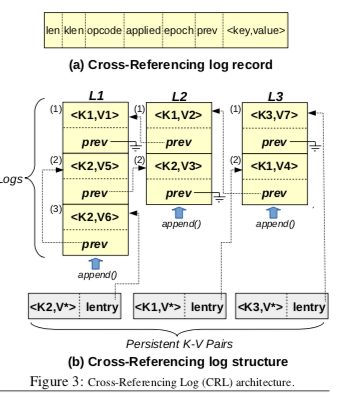
Bullet的基本思路如下,整个的结构范围Frontend和Backend部分,前者位于内存之中,后者保存在PM追中。由于Bullet是一个持久化的key-value store。所以这里使用了log的方式来保证一个数据持久化了。内存中的主要数据结构就是一个hash table,这个和一般的KVS差不多。在下面图中,不仅仅在内存中存在一个hash table。而且在Backend中,也存在一个一样的hash table。这个表示处理Bullet的基本工作方式:Bullet在工作的时候,先将数据写入到log之中,改写内存中Hash Table中的数据。Frontend中写日志的线程称之为log writer。而在backend中,一些log gleaners线程会钱Frontend写入的log消化,将这些log重放到PM上面的hash table。而这篇Paper的核心内容Cross-Referencing Logs就是如何优化这个写log的过程。
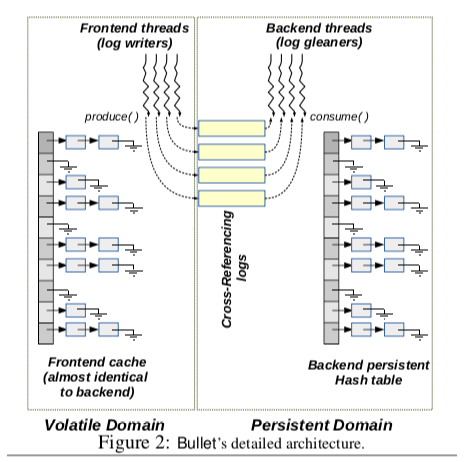
从上面的图中可以看出,Bullet写日志的时候使用了多个log。这样做基本的出发点是减少log writers线程之间的竞争,更好利用PM设备的带宽。不过这样做的方式也带来了另外一个棘手的问题,就是如何保存log record之间的顺序关系。在只有一个log写入的情况下,log entry在这个log中的先后顺序就可以表示了其之间的顺序关系。而多个log之间这种方法变得不可用。未来解决这个问题,这里在每个log record中引入了一个prev的指针字段。在下面的图中,一个log record中,包括基本的元数据字段如长度、opcode操作码,epoch之外,prev字段就会保存前一个有依赖关系的log record的指针。这样的设计下面,一些基本操作的逻辑如下,
- Append日志。如下面的图,这里存在三个log,在下面的一句持久化的key-vaue pair中,处理key-value本身的记录,还会包含一个lentry的指针,指向的是最新更新这个pair的log record。写入一个log record会分为好几步操作,1. 根据key的值找到对应的bucket,对其进行加锁处理,占据一个log最后的位置,将这个log的prev字段设置为key-valye pair中的lentry字段的值,2. 持久化这个log record,3. 更新和持久化log tail的索引,4. 更新和持久化key-vaue pair中lentry字段的值,解锁。
- Apply日志,Gleaner threads会周期性地扫描和引用这个log record。对于每个日志中的kv pair,根据key找对持久化了的hash table中,如果hash table中不存在这个key的记录,则添加新的记录。对于已经存在的key,根据lentry取出log record list,反向重复这个log record list中的log records。这里还要设置applied的标志,用于表示这个log record已经被应用了,最后更新kv pair中的数据。注意这里的操作都是在加锁的情况下吗操作的。
- 移除操作,为了避免在删除一个key有重新添加的情况下吗frontend和backend的数据不一致性,这里在frontend也是使用了逻辑删除的标志。
- 日志回收,写入的日志最后还是会被回收的。这里Bullet使用了epoch的方式。由另外一个epoch advancer线程通知gleaners开始apply日志。gleaners线程在接受到这个信息之后开始处理。同样地,epoch advancer线程也会通知这些现场什么时候停止处理,一个开始到停止的过程就是一个epoch,这个信息会被记录到log record中。日志空间回收也就可以直接epoch来回收了。
0x12 评估
这里的具体信息可以参看[3].
Log-Structured Non-Volatile Main Memory
0x20 引言
这篇Paper讨论了在NVMM下面的一个内存分配器的一个设计实现。Log-Structured最早应用在磁盘这样的块存储设置上面,最典型的例子就是1992年方便的Log-Structured File System的论文。之后,Log-Structured最为一种实现DRAM内存分配器的思路被应用到了RAMCloud这个存储系统中。这里是这种思路的继续拓展,这里将这个Log-Structured应用到了NVMM作为Main Memory的环境中。虽然这几个基本的思路都是Log-Structured,都是具体的场景差别很多,使用其设计差别也很大,
...we address a unique challenge of log-structured memory management by designing a tree-based address translation mechanism where access granularities are flexible and different from allocation granularities. Our results show that the new system enjoys up to 89.9% higher transaction throughput and up to 82.8% lower write traffic than a traditional PTM system.
0x21 基本思路
LSNVMM这里提供的结构和一般的malloc库一样,它提供了两个基本的接口,pmalloc和pfree。LSNVMM依赖于OS Kernel提供了DAX功能来分配大块的NVMM来使用,这里DAX的作为就类似于DRAM分配中的mmap和brk两个系统调用,这两个也是内存库的基本依赖。Log-Structured的思路一般都是Copy-on-Write的方式,这里LSNVMM也不例外,这里将应用使用的地址称之为hone address,而log中使用的地址称之为log address。由于Copy-on-Write的关系,这里home address和log address之间的映射关系会随着数据更新操作不断变换,LSNVMM的一个核心问题就是如何高效维护这个地址映射的关系。
在LSNVMM的基本架构上面,这里使用了两层的映射方式,第一层为一种静态的映射,在第一层,home address被划分为固定大小的partitions,可以做到O(1)复杂度的查询。第一层的映射减小了第二层映射的可以提高查询的速度。第二层使用skipp list维护映射关系。两层的映射在Paper中的测试结果表明可以提高39.6%的性能。每个Parttion会有一个Partition索引结构,用于映射信息的查询,初次之外,每个线程会有一个thread local的cache,这个线程局部cache的优化方式在malloc库中实现很常见,比如jemalloc。
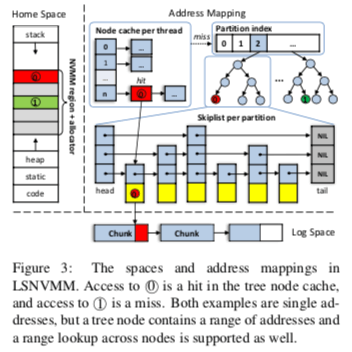
- 在分配上面,这里将每个NVMM区域划分为32KB大小的chunk。由于实际上每次分配的大小都不大,这里采用的chunk的size是一个比较小的值。另外,较小的chunk大小可以更快地执行垃圾回收的操作。为了减少不同的现场之间的竞争,这里维护了一个全局的chunk资源池,以及每一个线程局部的chunk list。以此来避免多个线程都频繁地对全局的chunk资源池进行操作。
- 在一个NVMM的区域中,一个log有一个chunk的list组成。这个和将整个磁盘作为一整个最为一个log不同。在此之中的每一个log entry有两类的元数据信息,一个是更新or映射的一个内存区域的映射关系,另外一个就是一个tombstone标记,用于表明这个memory area的空闲情况。在log entry的基本之上,这里引入了transaction,一个transaction包含了对个log entry的处理,这些处理保证是原子性的操作。log entry包含一个header以及其数据,head中包含一个47bit的home address,一个bit的tombstone标记,一个16bit的大小数据。
- Log Stuctured式的方式一般都要处理的就是垃圾回收的问题。一个log cleaner的工作就是多多个存在垃圾的chunk里面的数据移动到新的chunk里面。这里将一个chunk作为一个垃圾回收的目标是其中存活的数据的一个阈值,这里设置的是20%。此外,LSNVMM还使用了几种的优化策略,1. Fast cleaning,如果一个chunk里面不存在存活的数据,这个chunk就可以直接安全回收,2. Separate logs,基于局部性的一个优化,这里将更新log和分配的log分开,方便使用update log和allocation log处理。3. Parallel cleaning,即使用多线程来处理GC。
0x22 评估
这里的详细信息可以参看[2],
参考
- NVWAL: Exploiting NVRAM in Write-Ahead Logging, ASPLOS ‘16.
- Log-Structured Non-Volatile Main Memory, ATC ‘17.
- Closing the Performance Gap Between Volatile and Persistent Key-Value Stores Using Cross-Referencing Logs, ATC ‘18.
