E-Store: Fine-Grained Elastic Partitioning for Distributed Transaction Processing Systems
0x00 引言
这几篇的Paper主要讲的是一个Partition数据库中如何做Partition的一个问题,都是在H-Store这样的一个系统下面的一个研究。H-Store是一个Partition的内存数据库。Partition可以是以一定的规则来讲数据划分到不同的Partition,而E-Store这里关注的是热点数据的问题。这个问题在很多OLTP的场景中存在。而E-Store解决这个问题的基本思路是采用一种two-tier的分区方式。E-Store会从一个初试的分区方式开始,数据项会被划分为大小为B的Blocks(E-Store选择B = 100, 000)。在系统运行的过程中,E-Store会选择访问频率最好的K个Keys(比如前1%)来单独处理,决定它们存放的位置,
0x01 基本思路
常见的分区方式比如基于Hash 或者 范围的方式都是一种单层的分区。而E-Store采用的是一种“双层”分区的策略,兼而有之就是对于一般的数据就使用常见的策略,而一个小范围的热点的数据则采用单独分配的方式,分配到一个单独的节点。E-Store的基本架构如下图,
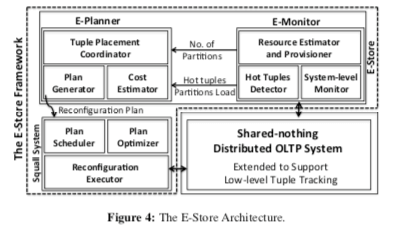
E-Store要解决的问题可以分为三个主要的部分:1. 如何发现负载的不均衡,需要进行数据迁移,2. 如何选择迁移的数据,以及迁移到哪里,3. 如何执行数据迁移的操作。这三个部分对应到上面架构图中的的就是:E-Monitor负责收集数据库系统执行过程中的一些统计信息,比如资源的使用率和数据项的服务情况。这些这些会交给E-Planer作出决策的依据,E-Planer产出迁移哪些数据,迁移到哪里的决定。另外实际去迁移数据的就是Squall,也就是下面的一篇Paper。Squall的Paper虽然发表在E-Store之后,不过Paper中提到,E-Store还是基于更新版本的Squall。
Monitoring
E-Store这里使用了一种自适应的统计信息收集方式。开始的时候E-Store使用一个DBMS之外的进程来收集一些OS层面的统计信息,这里应该就是这个节点资源利用率的一些信息,在这个统计数据中的一些数据指标达到一个阈值之后,会出发DBMS中元组基本的信息统计,这部分只能在DBMS内部进行。这样做的一个好处就是可以降低在正常情况下的一个访问信息统计造成的开销。
- 在OS层面,E-Store会对一项资源设置两个threshold,分别为高水位和低水位。超出这个水位的范围之后会触发元组基本的信息统计。
- 触发了元组层面的统计之后,DBMS中的每个分区都会统计一个时间窗口内的一个Top-K的一个信息。经过了这个时间窗口之后,每个分区的信息会被放松到E-Monitor。E-Monitor会根据这个信息得出一个Top-K的列表
Planer
在获取到了Top-K的列表之后。E-Planer会首先尝试移动热点数据来使得集群的负载达到一个均衡的状态。如何只靠处理热点的数据无法使其达到,则会考虑移动一些“冷”些的Block。热点数据数量比较少,能够在较短的时间内完成使用的网络带宽也小得多。如何整个集群的资源利用率都大于高水位的阈值,在一定条件下,E-Store就会将集群的机器数量扩大。当整个集群的资源利用率小于低水位时,则会考虑将集群的规模缩小。在决定将数据放置到哪里的问题上面,E-Store这里使用一种理想的策略和一种近似的策略,
-
Optimal,理想策略的一个目标就是每个节点的负载在靠近集群平均负载epsilon的一个范围之内。每一个热点数据和一个冷的Block都只会被分配到一个Partition,x(i, j)为1表示第i个热点数据分配给了第j的Partition,同理y(i,j)表示冷的数据块 \(\\ 则有L(p_j) = \sum_{i=1}^{n}(x_{i,j}) * L(r_i) + \sum_{k=1}^{d}(y_{k,j}) * L(b_k)) \ge A - \epsilon \\ 同样有 L(p_j) \le A + \epsilon的约束\) 这里还要考虑网络传输带来的开销,这里的开销也有一个sum式表示。目标就是最小化这个式子的值, \(\sum_{i=1}^n\sum_{j=1}^c(x_{i,j} * t_{i,j}) + \sum_{k-1}^d\sum_{j-1}^c(y_{k,j} * t_{k,j} * B)\)
-
Approximate,上面的算法虽然能够在E-Store的模型下面获到最好的效果,但是算法本身的开销也很大。这里E-Store还使用了一个近似的算法。
- 贪心,就是遍历热点数据的列表,将负载目前最高的一个节点的热点数据移动到负载最低的节点上。
- 贪心优化,这里不仅仅考虑了热点数据。在热点数据移动之后如果还是不均衡,则会考虑移动冷数据的Block。
- First Fit,从0 partition开始,重新分配数据到这个节点上吗,直到它的负载达到目标。如何依次处理后面的Partition。
0x02 评估
这里的详细信息可以参考[1]。
Squall: Fine-Grained Live Reconfiguration for Partitioned Main Memory Databases
0x10 引言
和E-Store一样,Squall也是在H-Store下面的一个研究。E-Store要解决的是分区成什么样的问题,而这里的Squall则要解决的是怎么样去分区的问题。总体来说,Squall还是采用了一种类似Zephyr方式的迁移方式,即采用被动和主动相结合的方式。
0x11 基本思路
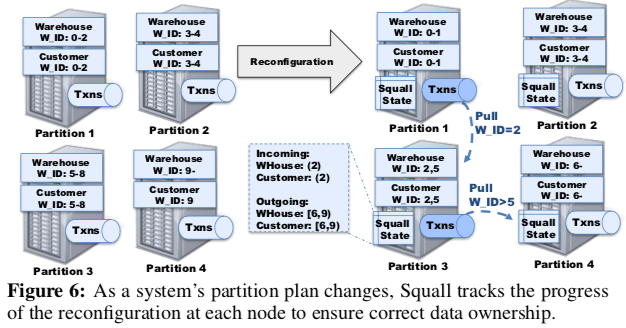
Squall的迁移从一个新的分区的方式开始,这里方式的产生可以参看前后两篇Paper。Squall使用 (WAREHOUSE, W_ID = [2, 3), 1 → 3) 这样一种方式表示一个新配置的分区,即 Table Name,加上用于分区的属性,一个左闭右开的区间,加上一个旧和新的分区ID。在数据迁移的时候,Squall会将要迁移的数据分区分为3个基本的状态:1. 没有开始,这种情况下,一个要迁移的分区待在原来的节点上面,2. 部分迁移,这个时候数据依据部分迁移到了新的节点上面,3. 完成,即全面的数据都已经迁移到了新的节点上。在1、3状态下吗,数据的位置是确定的,这样这个时间段内来的数据看操作会被直接发送到对应的分区。在状态2的时候,这个分区内的某个数据的位置是不确定的,这个时候就会将其发送到目标节点。如果在不确定数据位置的时候一个事务已经启动,Squall会将这个事务挂起,从迁移的目的节点上面重新启动。这样的工作方式就带来了类似Zephyr的迁移方式,
- 在目的节点上面执行操作的时候,数据可能还在原来的节点上面。这个时候Squall会Block这个操作,主动向源节点去拉去数据。注意这个会Block在这个节点上全部的食物,而不是只是要去拉去数据的事务,这样可以避免一些数据一致性的问题。Squall通过向源节点发送一个Pull请求来获取数据,这个请求就就像一个事务操作,会要求在源节点和目的节点两个加排他锁。Pull请求这样的工作方式会影响到数据库的性能,所以这里Squall会将这类请求作为高优先级的任务来处理。这个使用优先级的方式来处理不同类型的迁移请求也在[5]中使用了类似的思路。这里操作的死锁检测依赖于数据库中实现。
- 如果解决依赖于Pull拉取数据的lazy是的做法,可能会对一些事务执行的性能造成比较大的影响。Suqall在上面所说的reactive migration之外,还使用了asynchronous migration的方式。即在后台异步拉取数据,这里可以看作是一个主动获取数据的方式。源节点收到目的节点这样的请求之后,会将对应分区的状态标记为部分迁移,同时将数据划分为固定大小的Chunk。这里Suqall只会在同一个时间启动一个异步拉取的请求,而且在启动的时候,会检查数据是否已经都被被动拉取的方式拉取过来了。
0x12 优化和容错
在迁移的时候,Squall还使用了一些优化的方式啦降低数据迁移给系统运行带来的影响,比如,
-
Range分割。在上面的数据迁移的时候,Squall将一个要迁移分区内数据划为为一个个的Chunk,一Chunk为迁移的单位。而在第一个Chunk被迁移的时,就会将这个Range标记为PARTIAL,即部分迁移的状态,相关的数据库操作会被发送到目的分区,而这个时候其实大部分的数据还是没有迁移过来的。如何这个要迁移的分区比较大,就可以造成比较大的影响。这个Squall的优化方式是将Range迁移的Plan划为为更小的Sub-plan,来缓解这个问题。
-
Range合并,这个优化的方式和上面的方式相反。Squall会将小的、不连续的Range合成一个Range来迁移,减少迁移请求的次数。这个在一个要迁移的Range小于Chunk一半的时候有比较好的效果。
-
在Squall中,在一次reactive的拉取请求的时候,如果满足以下的一些条件,Squall会一次性拉取整个Range:(1) partitioned on a unique column, (2) has fixed-size tuples (e.g., no varchar fields), 和 (3) has split reconfiguration ranges。这个在Squall中被称之为预取。
-
在一个节点为源节点,另外的多个节点为目的节点的情况下,不同目的节点直接操作的竞争也会影响到系统的性能。这里Squall同样采取了拆分的策略,
Squall first identifies the ranges of keys that need to move in order to transition to the new partition plan. It then splits these ranges into a fixed number of sub-plans where each partition is a source for at most one destination partition in each sub-plan.
容错
H-Store使用Master-Slave副本的方式来提供容错。在reconfiguration的时候,主副本会依旧保持同步。这个reconfiguration的操作会同样的在一个主的从节点中进行。在Pull请求的时候,主节点会等待从节点都拉取成功,以保证主从之间的数据一致性。Squall这里主要要处理3中错误,故障的节点会在reconfiguration完成的时候才能:the reconfiguration leader failing,这里Leader的数据会同步到其它的它的副本上面,Leader故障的时候会使用其一个副本作为新的Leader。并且会将这个消息通过其它的节点。a node with a source partition failing 和 a node with destination partition failing,同样适用其它副本代替方式。 H-Store是一个将数据都保存到内存中的数据库,同时会将数据一snapshot的方式保存到磁盘上面。数据库在同数据迁移的时候同样会些Command日志,用于故障情况下的恢复。在reconfiguration的时候,数据库会暂停所有的checkpoint的操作,用于保障节点上面的Checkpoint的消息都是一致的。如果整个系统在一个reconfiguration完成,但是还没有打一个新的快照的时候崩溃了,系统就从上一个Checkpoint开始恢复,并且重新执行数据迁移的操作。
0x13 评估
这里的具体信息可以参看[2].
##Clay: Fine-Grained Adaptive Partitioning for General Database Schemas
0x20 引言
这篇Clay可以看着是E-Store的后续。在E-Store中使用的是两层的一个分区的方式。考虑的出发点是系统中数据访问的不均衡行,讲热点数据单独处理。Clay则从热点数据出发,并将和热点数据有找较强co-accessed特性的数据划分到相同的节点上面,一次来提供相同的性能,
... Clay outperforms another on-line approach based on the Metis graph partitioning algorithm [16] by 1.7–15× in terms of throughput and reduces latency by 41–99%. Overall, the performance of Clay depends on how skewed the workload is: the higher the skew, the better the gain to be expected by using Clay.
0x21 基本思路
如下图,Clay通过基于数据之间的co-accessed的信息,建立一个图。以热点数据存在的Partition为基础,建立clumps。Clay要做的就是Clump的组织以最小化分布式的事务,实现节点之间的负载均衡。Clay前面两篇Paper的继续优化的做法,
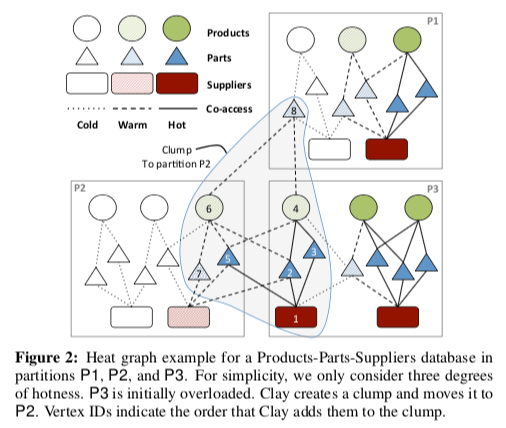
在Clay中,核心的就是clump migration algorithm。此算法的从识别一个overload的分区开始。对于这个Partition,迁移算法会动态定义和迁移Clumps,直到这个Partition的负载达到一个想要的负载的范围中。依次构建的Clump会包含这个Partition中的一些元组,也可能包含来自其它Partition的一些元组。而一个move操作就是将这个clump移动到一个指定的节点上面。算法会从一个空的Clump开始,初始化的时候会加入一个Partition中的最“热点”的数据;初始化之后如果Clump不为空,则之后会根据算法来想其中加入经常一次访问的数据。在有合适目的节点的时候,执行move操作。//…….
0x22 评估
这里的具体信息可以参看[3]。
参考
- E-Store: Fine-Grained Elastic Partitioning for Distributed Transaction Processing Systems, VLDB ‘14.
- Squall: Fine-Grained Live Reconfiguration for Partitioned Main Memory Databases, SIGMOD ’15.
- Clay: Fine-Grained Adaptive Partitioning for General Database Schemas, VLDB ‘16.
- Zephyr: Live Migration in Shared Nothing Databases for Elastic Cloud Platforms, SIGMOD ‘11.
- Rocksteady: Fast Migration for Low-latency In-memory Storage, SOSP ‘17.
