LLAMA: A Cache/Storage Subsystem for Modern Hardware
0x00 引言
˙这篇Paper是微软发布的一系列Paper的一部分。这些Paper主要涉及到为新型硬件(SSD)设计的数据结构BwTree,以及这里的 Cache/Storage Subsystem,还有就是下面的事务子系统。LLAMA还是一个基于Page的系统,主要是两个部分,Cache Layer主要负责管理在内存中的操作,而Storage Layer则负责处理在磁盘上面的数据和结构。两者都是以Page为单位对数据进行操作管理,而且两层都是使用同一个Mapping Table,这个Mapping Table和BwTree中的Mapping Table设计对应。
0x01 基本架构
LLAMA的基本架构入下图所示。LLAMA提高的是基于Page的操作结构,Page即可能保存在内存中,也可能保存在磁盘上面。而都是用同一个Mapping Table指向。用指针的最高的一个bit来表示这个Page在内存中还是在磁盘上面。在LLAMA中,如果一个Page的位置发生变化,这里通过一个8byte的CAS操作就可以更新Mapping Table中保存的位置信息。LLAMA提供的Page核心的操作结构也和BwTree中的一些设计,其更新操作分为 1. Update-D(PID, in-ptr, out-ptr, data),delta更新,2. Update-R(PID, in-ptr, out-ptr, data),replacement更新。读取操作Read(PID, out-ptr)可能改变一个page的位置,并更新mapping table。
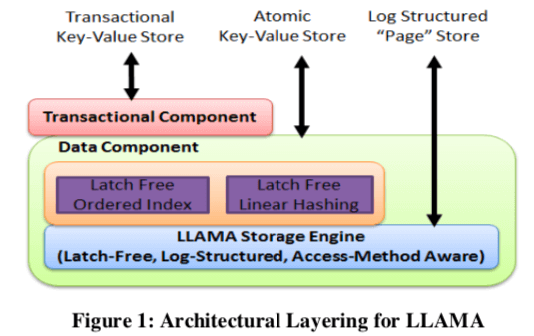
Cache Layer
在LLAMA执行更新操作的时候,通过CAS更改Mapping Table对应PID的page state pointer完成,添加的可能是delta chain的一个节点,也可能就是一个新的Page。基本的思路如下图。在持久化一个Page的时候,由于Delta Chain和Page是分离的,一个Page State可以有几个不连续的部分组成。其中可能一部分以及存在磁盘上面了,比如下面的page可能只有Delta Chain没有持久化,而Page P部分已经在内存中来,这要只要保存Delta Chain部分持久化就可以了,减少了一些的数据写入量。新写入的部分会保存前面的部分的位置信息。这样的缺点就是可能造成一个Page的数据在LSS上面由好几个分离的部分组成,这里可以选择在合适的情况下将一个Page一次写到一起,虽然可能造成一些额外的写入。为了解决在flush操作的时候其它的操作不去更新这个page,最简单的方式就是加锁,但是这里追求的是latch-free。
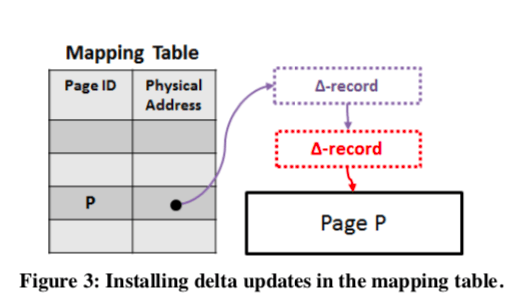
如果不加锁而使用CAS的方式。一个方法就是使用CAS的方式更新Mappint Table的内容。如果在Flush之中这个值发生了变化,这个Flush操作就是失败的。这里就是要满足下面的要求,
A page that is flushed successfully to LSS is immediately seen in the cache as having been flushed and the flushed state of the page must indeed be in the LSS I/O buffer ahead of the flushes of all later states. A page whose flush has failed should not be seen as flushed in the cache and it should be clear when looking at LSS that the flush did not succeed.
Paper中讨论了两种方式,1. 一种是先进行CAS操作更新page state信息。然后执行flush操作。这样的话会导致的一个问题是后面进行flush操作可能在前面的flush操作完成之前就完成了,导致系统在crash recovery的时候不能正确进行。2. 如果先进行flush操作然后进行CAS更新page state操作。这样会导致的一个问题是LSS中写入了一段信息,但是无法确认这个数据是成功写入还是失败的写入。也就是说这里需要的两步操作无论是哪一步先进行都会导致问题。Paper中给出的操作方式是,
- 先标记这个page的状态为准备进行flsuh操作;
- 在LSS Buffer中分配一个可以写入这些数据的空间;
- 执行CAS操作,决定这个操作是否能够成功;
- 如果第3步成功,将需要写入的数据写入LSS;
- 如果第3步失败,在第二步中预留的空间中写入失败的信息。
在进行page swap 操作的时候,一个Page最新的数据可能已经完整地持久化,也可能支持一部分被持久化。对于部分持久化的Page,最delta chain通过cas插入一个“partial swap” delta record,其中记录了delta已经被持久化部分的信息。而后面没有记录在这个之中的就是新添加的,没有被持久化。在添加了这个“partial swap” delta record记录知乎,以及持久化的数据在内存中的副本就可以通过LLAMA的内存回收机制进行回收操作了。这里LLAMA使用的内存回收机制基于Epoch机制,相关的思路可以在BwTree的论文中了解。
Storage Layer
由于SSD中Block、Page的分配,回收机制,使用LogStructured的写入方式是更加适合的。其中的数据在LSS中组织如下。数据可能为一个Page,也可能为Delta记录其中Delta记录会记录上一个Delta记录 or Base Page的指针,方便从LSS中恢复出完整Page的数据。这样的设计在从LSS中读取一个Page的时候,可能对应到的是多个实际的读取操作。所以,将Delta记录、Base Page尽可能连续存放能够提高性能。在进行flsuhing操作的时候也是latch-free,并且是异步的。LLAMA没有选择指定一个线程进行flushing操作的方式,认为这样的方式的缺点是很难保证线程之间负载的均衡。一般的flush操作都是先将要flush的数据拷贝到一个buffer中,然后将这个buffer写入磁盘,很多的数据都是这样实现的。这里的一个研究的问题如何实现这里为latch-free的。LLAMA这里的做法是:每个Buffer用一个起始地址Base和一个大小值Bsize组成。在进行预留buffer空间操作的时候,先计算目前的写入的tail的Offset和要写入的Size,只有在没有超过的Bsize的时候预留操作才能成功,否则只能分配另外一个Buffer。
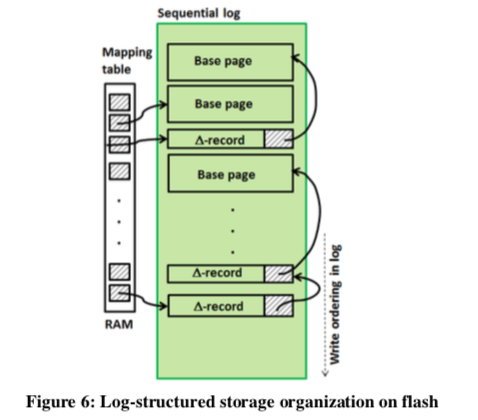
这样的思路下面预留操作时简单的,另外的一个问题是如何知道Buffer里面的空洞信息,因为后面预留操作然后写入数据比前面的操作先要完成,这样此时这个Buffer的tail之前是存在空洞的。在一个Buffer无法在分配预留空间的时候,这个Buffer被sealed,之后这个Buffer就不能接受新的更新操作。但是不能保证之前的操作就已经完成了。这里用一个Active字段记录进行中的操作,类似于一个引用计数的方式。在LSS的空间回收上面,LLAMA采用将SSD空间视为“circular buffer”的方式,在重新写到轮回的时候进行回收操作。
0x02 其它
事务
这部分感觉比较模糊。事务相关的这里并不是LLAMA提供的,而是下面的Deuteronomy。有些操作,比如Bwtree中的structure modifications operations (SMOs) 操作,还是需要LLAMA有相关的接口支持,在LLAMA中可以用如下的思路支持SMO操作。在系统中也会和一般的数据库系统中维护一个active transaction table,ATT。记录目前活动的事务的信息。

这里的事务commit和abort主要考虑的是如果将在一个事务中被修改的page的习惯信息在一个提交中一起被持久化,从而到达原子性、持久性的效果。这里使用atomic flush来实现将相关更改一次持久化的效果。基本方式和单个刚刚是一样的,不过这里都是要考虑到对个Page的更新。比如LSS Buffer分配的为所有的改动分配,
LSS buffer space is allocated for all pages changed in the transaction. Then the CAS is executed that installs the Update-D delta prepended with a flush delta. If the CAS succeeds, the pages updated in the transaction are written to the LSS flush buffer. Only after the flush of all pages for the transaction is complete does the flush process decrement the number of writers of the flush buffer.
如果这里CAS失败了,flush操作失败。同样地使得以及分配的空间变为无效。在恢复处理的时候,不会理会这些无效的数据。这样可以认为恢复处理是对这些事务无感知的。
故障恢复
LLAMA这里的recovery操作不是指transactional recovery,这里说的checkpoint也不是事务中的checkpoint。因为LLAMA是一个Cache/Storage Subsystem,不负责处理数据中事务相关的一些东西。这几个组件分离的设计也是这一系列论文的特点。这里的恢复是值将LLAMA的状态恢复到crash之前pages个mapping table以及其状态信息。这里也使用了checkpoint的,基本的方式就是异步地将mapping table的信息持久化,可以选择轮回写两个地方的方式。这个策略在LFS中的设计也用到了。每次保存mapping table的时候,还会额外保存recovery start position (RSP) 和 garbage collection offset GC的信息,且这些信息先写入。写mmaping table作为这里checkpoint的一部分,不是简单将mmaping table按byte拷贝一下然后持久化,还需要处理Cached Pages信息和free mapping table entry。恢复操作的时候,先恢复以及持久化的有最高的RSP的信息,然后读取从RDP到LSS末尾的信息,然后,
* Each page flush that is encountered is used to restore the page’s PID in the mapping table to the flash offset for the page.
* When an Allocate operation is encountered, the mapping table entry for the allocated PID is initialized to empty as required by an Allocate operation.
* When a Free operation is encountered, the mapping table entry is set to ZERO.
* The LSS cleaner will resume garbage collecting the log from the GC offset read from the checkpoint.
空闲的mapping table entries也会在这个操作重新组织为free list。
0x03 Deuteronomy
事务子系统Deuteronomy 构建在LLAMA之上。这里的子系统之间的设计划分的比较清晰。
Our new prototype TC combined with the previously re-architected DC scales to effectively use 48 hardware threads on our 4 socket NUMA machine and commits more than 1.5 million transactions per second (6 million total operations per second) for a variety of workloads.
MVCC的并发控制机制是目前绝大多数数据库系统使用的并发控制机制。Deuteronomy这里的设计也不例外,使用Timestamp Order MVCC的机制。MVCC实现的事务隔离级别为SI,多数情况下SI的基本都是足够使用了的。如果要在SI的基础之上实现serializability的隔离级别,常用的方式使用validation的机制。这里TC组件使用一个transaction table来追踪事务,这个table中会记录事务的id,状态status,以及这个事务启动的时候分配的时间戳。status记录了一个事务为active、commited or aborted,这个table会根据最老的active的事务定期清理。另外在一个MVCC hash table记录每条记录的版本的学习。
-
为了管理MVCC的数据,这里使用了一个hash table。一个版本的数据会被根据key的hash分配到一个痛里面,这里会记录这个记录key的hash值,指向完整key的指针,最早的地区这条记录的事务的timestamp,以及一个版本信息list。为了优化性能,这里的记录都是定长的,且长度的选择上面针对缓存行的大小进行了优化。并且这里保存了hash值,可以避免很多情况下去读取完整的key。这里的version list用于选择合适的版本去读取。这里记录的read timestamp,称之为last read timestamp。这个timetamp被用于记录最近的数据版本被最近的读取时间,防止比最近读取的事务更老的事务去修改这里的数据。
-
Version List记录多版本的信息,基本的实例如下图所示。一个Version List中的记录会包含这样的一些东西,
-
Version list items are fixed size and contain: (a) the transaction id of the creating transaction; (b) a version offset, used to reference the payload from the version manager; and (c) an “aborted” bit used to signify that this version is garbage and the transaction that created it has aborted – this is used as a fast track for the garbage collection process这里的MVCC hash table的每个bucket核心就是两个list,一个record list,另外一个就是record的version list。全都是latch free的设计。内存回收使用基于epoch的机制。
- 事务提交,事务的提交都是并发控制机制核心的部分之一。这里使用了一些优化机制,1. 当一个事务的的commit record被写入到recovery log buffer的时候,这个事务表现为被提交了。但是由于数据没有被持久化,不能立即回复用户。这里需要得到log buffer持久化之后才通知用户。这种机制在MySQL的一些版本中也被使用。对于只读事务,看上去可以在其发出commit操作的时候就可以提交,因为其没有什么数据需要持久化。但是这里这样做会有一个逻辑上的bug,就是在恢复操作的时候,一个已经完成的只读事务返回的数据被abort。这里只读事务同样会等待它们读取的数据都持久化之后在返回。但是在读严重的workload中这样的操作会浪费不少的性能。这里的优化方式是基于追中记录相关的highest commit log sequence number (LSN)的方式。
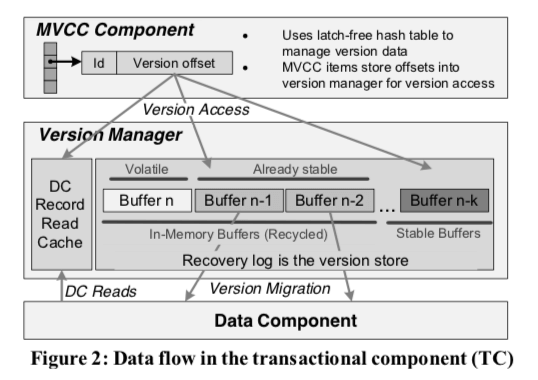
多版本的数据这里Deuteronomy使用了两个主要多版本的数据来源,一个是内存中的recovery log buffers,另外一个是“read cache” ,这些数据已经被持久化到磁盘上面,不保存在recovery log buffers中。第一种称之为Recovery Log Caching,这里将这个Log作为两个用途,即当做一种recovery的方式,当其还保存在内存中是也将其当中最近写入数据的一种cache。这里会用一个hash table来作为这些数据的索引,方便查找。这个hash table就是MVCC hash table。一般的数据库中,log buffer在其数据被持久化之后,就可以被释放了。这里的话还要额外的处理。这里的Log Buffer管理使用了Log-structured的方式。另外的ReadCache,其中保存了从Data Component(DC)中拉取的数据版本。其数据管理的方式也是Log-structured的方式,类似于Recovery Log Caching。关于Deuteronomy,[2]中还有更多的内容。
0x04 评估
这里的具体信息可以参看[1].
参考
- LLAMA: A Cache/Storage Subsystem for Modern Hardware, VLDB ‘13.
- High Performance Transactions in Deuteronomy, CIDR ‘15.
