F1 Query: Declarative Querying at Scale
0x00 引言
F1 Query是Google开发的F1的后续系统,可能是因为Spanner发展挤占了之前F1负责的工作。F1 Query就得想办法就拓展F1的功能。不过F1 Query和F1实际的差别还是非常大的,可以是不同的两个系统。F1 Query在这篇Paper中描述的是非常nubility的一个系统,既可以支持OLTP,又可以是指OLAP,还可以执行一些ETL之类的工作。另外在数据源方面,可以支持各种类型的存储系统,比如Bigtable, Spanner, Google Spreadsheets 等等。对不同workload类型,以及众多种类异构数据源的支持,所以Paper中说F1 Query可以支持所有数据处理的要求!
0x01 基本架构
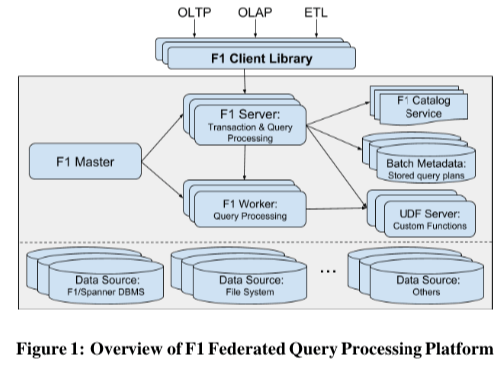
F1 Query的基本架构如下图所示,F1 Query有点类似于给众多数据源提供统一SQL的前端。用户通过Client和F1 Server进行交互。F1 Master作为一个中性化的节点,负责处理监控查询的运行以及管理其它的组件。F1 Server负责处理事务和查询处理。对于较小的查询,直接就可以在F1 Sevrer中处理,对于较大的查询,会讲查询请求发送到多台的F1 Worker中进行处理,然后在F1 Sevrer中进行汇总。Server和Worker都是无状态的,方便容错和拓展。另外的几个组件事F1 Catalog Service,这个就是保存了下面的异构数据源的一些元数据,Batch Meta则似乎查询计划的一些信息,另外的UDF Server负责处理user defined scalar functions (UDFs)的一些工作。基本浴血工作流程,
- 客户端的请求会被发送到其中的一台F1 Sever的时候,F1 Sevrer会解析出里面涉及到的数据源。如果数据源不再本数据中心中,则返回给客户端可以数据所在数据中心的列表。这样客户端就可以通过这些信息重新发送请求,
-
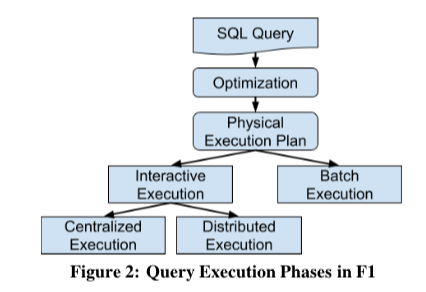
查询会在F1 Query中被解析为一个DAG表示的一个执行计划。根据客户端不同的请求,F1 Query会选择事交互式的查询执行模式,还是批处理的执行模式。对于交互式的模式,查询优化器会根据一个启发式的算法选择事单机执行还是分布式执行。单机的情况下,F1 Sever自己就解析计划并直接执行,如果是分布式的执行,则将工作发送给若干的F1 Worker,F1 Server作为一个协调者和数据汇总处理者的角色。对于批处理的模式,还是基于Mapreduce的框架。
-
F1 Query支持的数据源保护了Google常用存储系统,比如Bigtable、Spanner等。另外还可以直接支持在一些文件上面的查询,比如CSV 、ColumnIO 文件等。F1 Query在这些异构的数据元素构建出一个统一的数据抽象。这个数据抽象还是基于SQL的Table结构。这个还涉及到的一个概念就是Data Sinks ,查询的结果如果没有返回给客户端而是保存的到了另外一个地方,这个就叫做是Data Sink。
DEFINE TABLE People( format = ‘csv’, path = ‘/path/to/peoplefile’, columns = ‘name:STRING, DateOfBirth:DATE’); SELECT Name, DateOfBirth FROM People WHERE Name = ‘John Doe’;
0x02 查询模式
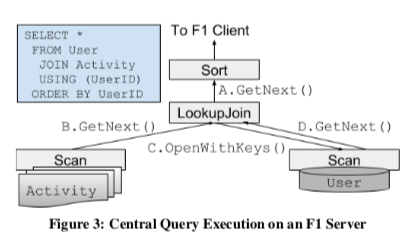
F1 Query中的查询计划执行是经典的火山模型,使用一种pull的模式执行,每个DAG中的节点的核心接口是GetNext。单机模式下面,可以看作就是火山模型的存储计算分离的实现。很多基本算子的实现在单机的模式下面也是很常规的实现。
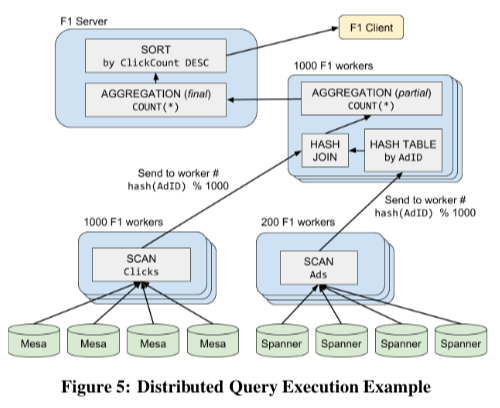
分布式执行模式下面当然要复制一些,算子实现也会更加麻烦。分布式数据处理必须要处理的一个问题就是数据分区的问题,F1 Query这里会讲查询计划划分为Fragment,F1 Sverer讲Fragment的执行任务分发给F1 Worker。下图是一个执行计划在分布式执行模式下面的策略,每个基本的算子可以划为为不同数量的Fragment,即不同的并行度来执行。这里F1 Query会有一些数据分区的策略,比如hash join中使用相关字段的hash值来进行分区。数据分区在不同的执行阶段会有不同分区,所以这里使用了exchange operator来执行重新分区的操作。数据发送方会使用一个partitioning function来决定下一个阶段中数据被分布到那一个Fragment,这里的通信使用Google自己的RPC框架。下面就是一个分布式执行的例子,对应到下面的SQL语句。执行主要分为几个阶段,
SELECT Clicks.Region, COUNT(*) ClickCount
FROM Ads JOIN Clicks USING (AdId)
WHERE Ads.StartDate > '2018-05-14' AND
Clicks.OS = ‘Chrome OS’
GROUP BY Clicks.Region
ORDER BY ClickCount DESC;
Scan阶段,涉及到的两个表使用不同的并行度来进行并行Scan。由于下一步的worker数量为1000,这里Scan出来的数据会根据hash值除1000取余来讲数据发送到对应的worker。HashJoin阶段,优化器选择在AdID表数据上构建HashTable,每个worker都进行这样的HashJin操作,得到的数据进入下一步的Aggregation操作,由于这里是每个worker进行的Aggregation操作,所以Aggregation是Partial的。结构汇聚阶段,Final Aggregation讲各个worker的结果进行汇聚,并根据SQL的要求进行排序,向Client返回结果。这里的操作都是在内存中进行,如果执行过程中出现了机器故障,想要进行重试操作。Paper中提到一些数据访问倾斜会对性能有比较大的影响,F1 Query提出了一些如 dynamic range reparti tioning的方式来处理这样的问题。
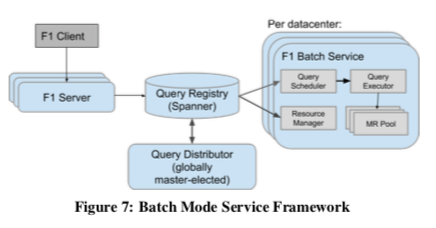
批模式与交互式的一个大的不同是批模式下面,会处理机器故障的问题。批模式还是基于Mapreduce框架。Client输入的还是SQL,F1 Query会将其翻译为Mapreduce的表示。SQL的执行的不同阶段对应到不同Mapreduce Stage。不同Stage的中间结果会保存到Colossus分布式文件系统中。这样容错性会比交互式的模式好上很多,基本的原理还是Mapredce。批模式的基本框架如下,一个F1 Sevrer在接受到Client的请求之后,将客户端的SQL翻译为执行计划,保存到一个全局的Spanner数据库中。即相当于Query Registry组件中注册了这个执行计划。Query Distributor将一个Query工作分发到一个数据中心处理,这里数据中心的选择会考虑负载均衡、数据源是否availability等的因素。每个数据中心内,会有一个Query Scheduler定期地从Query Registry 中拿到任务,分配给Query Executor来执行。Scheduler会构建不同Job之间依赖关系的DAG图,追踪任务的完成情况,并在后面的任务运行的条件满足之后执行这个任务。
0x03 优化和拓展性
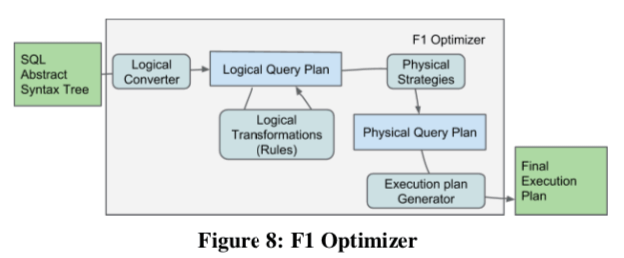
查询优化器是数据库中一个复杂的组件,而且F1 Query有不同的执行的模式,面对各种各样的数据方式。设计一个完美优化器估计会极其困难。F1 Query为了简化优化器的设计,不同的执行模式使用相同的查询逻辑。F1 Query的优化器的基本结构设计如下,是一种 Cascades 风格的优化器的设计。优化主要是基于heuristic规则的策略,估计在F1 Query面临的场景下面估算不同操作的开销也很困难。Paper中还提到了一些实现的细节。
在可拓展性方面,Paper中主要提到F1 Query支持的user defined scalar functions (UDFs), aggregation functions (UDAs), 和 table-valued functions (TVFs)。在前面的架构图中的UDF Server主要与此相关。F1 Query中UDF的一个特点是作为一个分离的服务,但是还是会放到和Worker同一个数据中心中。UDF Server作为一个单独的RPC服务,可以使用不同的编程语言来实现UDF。而UDF Server和F1 Server之间通过统一的RPC接口来进行交互,UDF Servers的地址信息有客户端提供给F1 Sever。除了用UDF Server来实现UDF,还可以直接在SQL中使用SQL语言、Lua来实现简单的UDF,比如下面的一个Lua实现的Scalar Functions UDF的例子,
local function string2unixtime(value)
local y,m,d = match("(%d+)%-(%d+)%-(%d+)")
return os.time({year=y, month=m, day=d})
end
User-Defined Aggregate Functions对应与上面的Scalar Function对应,Scalar Function使用一个输入,输出一个结果,而 Aggregate Function使用一组的输入,输出一个结果,这里要求实现Initialize, Accumulate, 和 Finalize三个方法,和实现一个接口类似。而Table-Valued Functions是输入一个Table,输出另外一个Table。F1还可以通过SQL定义TVF,下面一个通过SQL定义的Table-Valued Function例子,
CREATE TABLE FUNCTION EventsFromPastDays(
num_days INT64, events ANY TABLE) AS
SELECT * FROM events
WHERE date >= DATE_SUB(
CURRENT_DATE(),
INTERVAL num_days DAY)
0x04 评估
这里的具体信息可以参看[1].
参考
- F1 Query: Declarative Querying at Scale, VLDB ‘18.
