Bigtable: A Distributed Storage System for Structured Data
引言
这篇是一篇对后面的系统产生重大影响的论文,Bigtable是Google的分布式结构化的存储系统。
数据模型
不提供关系模型,在Bigtable中,数据的组织像是一张巨大的表格(Bigtable名字的由来),表格一般都是由行和列确定的,这个表格在Bigtable中叫做table,在Bigtable中的数据模型是:
(row:string, column:string, time:int64) → string
论文中的描述是一张table在Bigtable中是一个洗漱的、分布式的、持久化的、多维的排序好的图(map)。row + column可以理解为就是确定了这张巨大表格中的一个格子,在Bigtable中也把它叫做Cell。除了row和column之外,Bigtable还加入了额外的一个时间维度,它是一个64bit的时间戳。这样,Bigtable更加像一个三维的表格。这个格子对应的数据是一个字符串或者是由时间戳区分的多个版本的字符串。
-
Rows,Bigtable使用row keys来排序,row key实际上就是一个字符串。这里Bigtable的一个特点是能够保证一个row 可以上面的读写操作都是serializable,而且无论多少columns参与到这次操作之中。这也就是为什么说Bigtable只支持单行事务的原因。Bigtable不支持跨行的事务,这也是Google后面一些系统出现的原因,主要就是为了解决这个问题,后面会有这个方面的总结。
-
Columns,Bigtable会将columns分组为列族,访问控制在列族上组织。一个列族下面的列同时有相同的类型。列族是必须被显示的创建的,在创建之后就可以在其中添加列。列的key是
family:qualifier这样的格式,Column family names must be printable, but qualifiers may be arbitrary strings. An example column family for Webtable is language, which stores the language in which a web page was written. We use only one column key with an empty qualifier in the language family to store each web page’s language ID. -
Timestamps,Bigtable中允许每个cell里面保存多个版本的数据,使用时间戳来区分版本。
Applications that need to avoid collisions must generate unique timestamps themselves. Different versions of a cell are stored in decreasing timestamp order, so that the most recent versions can be read first.在Bigtable中,应用可以选择只保留最新的版本,也可以选保留最近的N个版本。Bigtable基本的API示例:

基本架构
Bigtable依赖于Google的很多基础设施的服务,比如GFS和Chubby。它的基本架构如下:
Bigtable的基本的组成部分和GFS的很相似,主要的部分也是两个:一个Master Serber,和一些tablet servers,另外还包括一个客户端使用的库。tablet server是可以动态添加 or 移除的。同Master在GFS的作用类似,Bigtable中Master的作用也是管理的作用,虽然具体的合作有所不同。Bigtable中Master负责讲tabllet分配给tablet servers,探测添加 or 过期的tablet server,对tablet server进行负载均衡,还有就是对垃圾文件进行回收处理。此外,它还负责处理schema的变化,如添加or删除table、列族等。每一个tablet server负责管理一组的tablets, 处理在这些tablets上面的读写请求,在tablet过大的时候对其进行切分。 一个Bigtable的集群会保存若干数量的table,而每一个table由一组的tablets组成。一个tablet上面保存了一个范围内的row key以及对应的数据。tablet是自动随着数据的增长而分裂逐渐增多的,初始的时候每个table都只有一个tablet。默认情况下,一个tablet的大小为1GB。
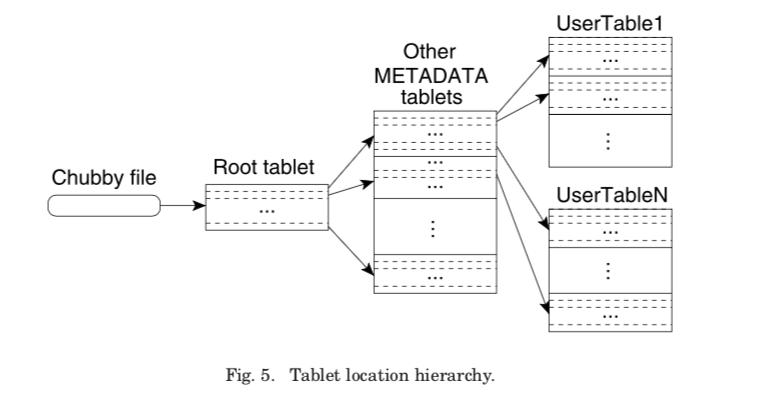
tablet的位置
如上面的基本架构的图所示,tablet的位置信息被组织在一个3层的结构里面。第一层是保存在Chubby中的root tablet,这个root tablet保存了一个特殊的METADATA table的tablets的位置信息。然后,每一个METADATA table的tablet保存了一组用户的tablets的位置信息。root tablet保存在Chubby中,从来不会被分裂。METADATA table中的row key是用户tablet的table的标识符+它的end row 组成。客户端通过这些信息确定tablet的位置(客户端也可以缓存tablet的位置信息):
The client library traverses the location hierarchy to locate tablets, and caches the locations that it finds. If the client does not know the location of a tablet, or if it discovers that cached location information is incorrect, then it recursively moves up the tablet location hierarchy. If the client’s cache is empty, the location algorithm requires three network round-trips, including one read from Chubby. If the client’s cache is stale, the location algorithm could take up to six round-trips, because stale cache entries are only discovered upon misses (which we expect to be infrequent because METADATA tablets should not move very frequently).
此外,在METADATA table还保存了其它的一些信息,比如:
We also store secondary information in the METADATA table, including a log of all events pertaining to each tablet (such as when a server begins serving it). This information is helpful for debugging and performance analysis.
Tablet 分配
在Bigtable的tablet的分配中,每一个tablet在同一时间最多被分配给一个tablet server。Bigtable分配tablet的方式就是给一个tablet server发送tablet load的请求,这个请求只会在下次Master的故障转移前还没有tablet server接收这个请求才认为这个分配失败了。一旦Master发送了一个load请求,除非在这个server无法工作的情况下或者这个这个tablet server明确返回了这个tablet无法load的信息,否则Master都认为这个tablet以及分配了。这里tablet只分配给了一个tablet server,所以这里的可用性是依赖于GFS的。 关于Bigtable如何追踪tablet servers ,这里Bigtable的工作严重依赖于Chubby的服务。一个tablet servers启动的时,它会在一个特殊的Chubby目录下创建并持有一个互斥锁。Master通过监控这个目录去发现 tablet servers,一个 tablet servers在丢失这把互斥锁的时候,就意味着它停止了由它负责的tablet上面的服务:
for example, a network partition might cause the server to lose its Chubby session. (Chubby provides an efficient mechanism that allows a tablet server to check whether it still holds its lock without incurring network traffic.) A tablet server attempts to reacquire an exclusive lock on its file as long as the file still exists. If its file no longer exists, then the tablet server will never be able to serve again, so it kills itself.
当Master发现一个tablet server停止服务时,它会尽快地重新分配这个tablets。这里处理的方式也是基于Chubby的分布式锁的:Master会尝试去获取这个互斥锁,当它可以获取这个互斥锁时,在获取到之后,它就会把这个锁对应的文件删除,这个时候它就可以顺利地重新分配这些tablets了。此外,为了保证Bigtable集群不易受网络问题的影响,当一个Master自己的Chubby Session过期的时候,它就会结束自己的服务。Master的问题不会导致这个tablet被重新分配。当一个新的Master启动时,它的恢复操作:
- 获取一个关于Master的锁,这个事为了不会同时产生多个Master;
- 新的Master扫描对应的Chubby目录发现存活的tablet servers;
- 然后Master与这些servers通信,获取tablets的分配信息,并表明自己的新Master的身份;
- 然后Master扫描 METADATA table获取tablets的信息,分配没有被分配的tablets。还有一个要处理的问题就是扫描METADATA table必须在这个METADATA table的tablet都已经分配的情况下,所以为了处理这个问题,在第4步之前,Master需要在root tablet上面添加相关数据并处理。
前面说过了新的tablet除了第一个之外都来自其它的tablet的分裂(这里除了分裂之外,可以时减小到一定程度的tablet之间的合并),tablet server通过操作METADATA table的记录这些信息,之后,这个tablet server会通知Master处理这个新的tablet的分配问题。当由于tablet server故障 or Master故障导致这个新的tablet没有分配时:
the master detects the new tablet when it asks a tablet server to load the tablet that has now split. The tablet server will notify the master of the split, because the tablet entry it finds in the METADATA table will specify only a portion of the tablet that the master asked it to load.
Tablet维护、压缩和 Schema 管理
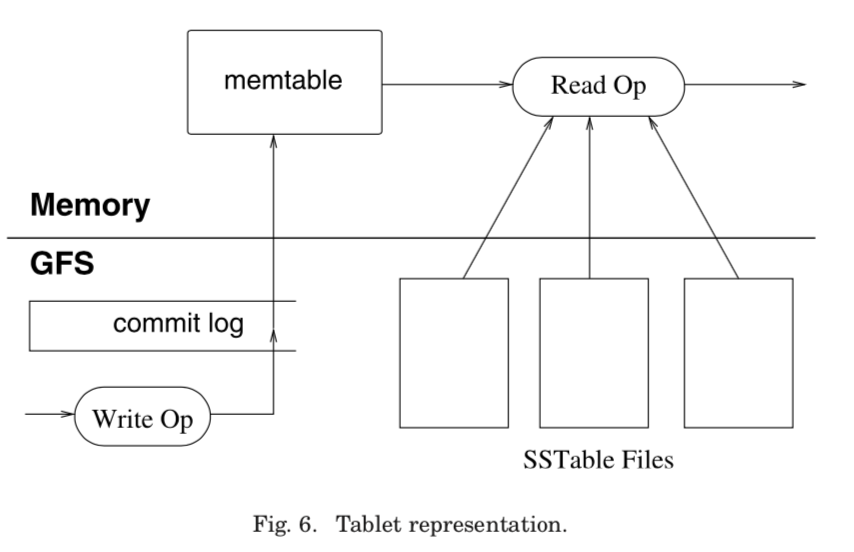
上图标示来一个tablet的组成:一些磁盘上面的SSTable文件,这些文件保存早GFS里面,一个在内存中的memtable以及一个commit log,这个log数据也保存在GFS里面。
Updates are committed to a commit log that stores redo records. The recently committed ones are stored in memory in a sorted buffer called a memtable. A memtable maintains the updates on a row-by-row basis, where each row is copy-on-write to maintain row-level consistency. Older updates are stored in a sequence of SSTables (which are immutable).
为了恢复一个tablet,一个 tablet server从METADATA table 读取这个tablet相关的元数据。这些数据包含来SSTable文件的链表,当然还包含来redo log的信息。tablet server可以通过这些信息来重建这个tablet。 Tablet Server会进行3种类型的compaction:
- minor compaction,当memtable增长到一定程度之后,将其冻结,然后创建一个新的memtable。原来的memtable将会被转变为SSTable文件保存在GFS中;
- merging compaction,merging compaction时讲一些SSTables和memtable合并为一个新的SSTable文件,能够有效的减少SSTable文件的数量;
- major compaction,将若干SSTables文件合并为一个,同时去除里面以及被删除的数据;
此外这些操作还考虑了数据的位置,放到离tablet server更近的地方有利于提高性能:
Bigtable read performance benefits from a locality optimization in GFS. When files are written, GFS attempts to place one replica of the data on the same machine as the writer. When GFS files are read, the reads are served from the nearest available replica. Therefore, in the common case of tablet servers sharing machines with GFS servers, tablet servers will compact data into SSTables that have a replica on local disk, which enables fast access to those SSTables when subsequent read requests are processed.
Bigtable的schemas的数据也是保存在Chubby里面的。
优化
-
Locality Groups,一个列族被赋予一个客户端定义的Locality Group,这样就可以由客户端控制存储布局,SSTable的生成也时每个Locality Group一个文件。讲经常一起使用的列放在一起有利于提高性能;
-
Compression,客户端控制哪一个Locality Group是否压缩。SSTable上面的压缩时以SSTable的block为基础的,这样的话解压缩的时候只需要减压缩一部分;
-
Caching for Read Performance,使用 Scan Cache和Block Cache 两层的Cache,前者缓存key-value对,后者缓存SSTable文件的块;
-
Bloom Filters,LSM-Tree的常见优化,
We reduce the number of accesses by allowing clients to specify that Bloom filters should be created for SSTables in a particular locality group. A Bloom filter allows us to ask whether an SSTable might contain any data for a specified row/column pair. -
Commit-Log Implementation,Tablet Server讲所有的tablet的commit log写在一个文件里面,但是由于tablet可能被重新分配,这里需要使用Master发起对这个log的排序,按照
⟨table, row name, log sequence number⟩这样的元组来排序,这样每个Tablet Server就可以只读区自己的部分; -
Speeding Up Tablet Recovery,在unload一个tablet的时候,先做一次minor compaction,然后停止对这个tablet的服务,然后在做一次 minor compaction。
-
Exploiting Immutability,对SSTable进行垃圾回收,它不变的特性也使得分裂tablet变得简单:
the immutability of SSTables enables us to split tablets quickly. Instead of generating a new set of SSTables for each child tablet, we let the child tablets share the SSTables of the parent tablet.
评估
详细数据可以参考原论文[1].
参考
- Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., Chandra, T., Fikes, A., and Gruber, R. E. 2008. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. 26, 2, Article 4 (June 2008), 26 pages. DOI = 10.1145/1365815.1365816. http://doi.acm.org/10.1145/1365815.1365816.
