PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers
0x00 引言
这篇paper也是即将发表在SIGMOD ‘21上面的一篇Paper,关于数据库disaggregation的一个设计。Disaggregation是最近系统方向的一个热点的研究方向,其核心思路是可以理解为各类资源,比如CPU、Memory以及Storage Resource等,分离并独立管理,实现按需分配。在PolarDB这样的cloud native,其本来是一个存储、计算分离的涉及,但是计算节点上面CPU和Memory还是在一起的,进一步Disaggregation的设计就是如何将这个CPU和Memory的资源也分离。这样带来的好处就是资源更新方便贡献,按需调度,可以实现更快的failover(achieves better dynamic resource provisioning capabilities and 5.3 times faster failure recovery speed),同时实现和只存储计算分离方式差不多的信念。但是性能还是有下降的,根据在ChinaSys上的Presentation,基准测试中性能下降在百分之十几。其基本架构的示意如下图所示。
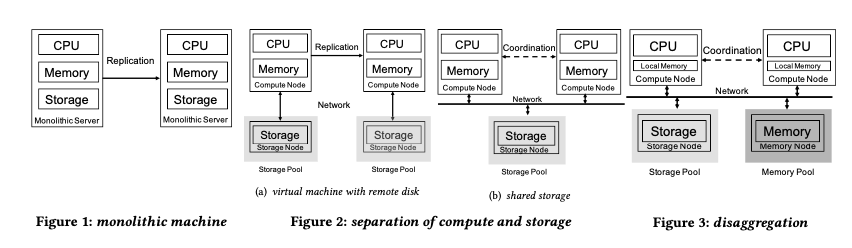
PolarDB的基本架构如下图,其是一个模仿Aurora的设计,但是存在一些不同。其核心是将MySQL写本地的磁盘改成写一个专门开发的分布式文件系统PolarFS。系统运行事务的时候:1. 写入/RW节点只有一个,写操作操作flush redolog到下层的fs之后,事务即可以commit;之后异步将redolog最新的LSN信息广播给其它的read-only/RO的节点;RO节点在收到这个信息之后,从fs拉取新的redo log来在本地重放来实现对本地buffer pool中的数据进行更新;RO也需要将自己目前redolog消费到哪里的信息提供给RW节点,这样RO节点都消费了的redolog就可以安全地删除(要dirty pages被flush到下层的fs)。这个存储层的交互和Aurora存在比较大的差别。一个RO节点如果是snapshot读取一个较老的版本,可以直接读fs中的pages。可见RO节点消费redolog的速度太慢会影响到RW节点。
0x01 基本设计
将CPU和Memory分离,PolarDB Serverless的做法是将将远程的内存作为一个remote memory pool。带来资源利用率提高的同时也带来了几个问题:一个是remote memory还是比不上本地的,这样就需要一种分层的内存设计和预取的机制;另外一个是不同节点可能访问同样的内存资源,就需要一种互斥的机制;还有一个是page数据的加大了网络流量,这里优化为其它类似系统在存储层将redo log异步转化为pages的功能。这里提出来的是一组remote memory access的接口,如下所示:
// increases the page’s reference count by one. If the page does not exist,
// this function allocates space for the page in the remote memory pool,
// otherwise, the page is copied to the caller’s local cache.
int page_register(PageID page_id, const Address local_addr,
Address& remote_addr, Address& pl_addr, bool& exists);
// decreases the page reference count by one. When the page reference count reaches 0,
// the page can be deleted from the remote memory pool
int page_unregister(PageID page_id);
// page_read fetches a page from the remote memory pool to the local cache using one-sided RDMA read.
int page_read(const Address local_addr, const Address remote_addr);
// page_write writes a page from the local cache to the remote memory pool using one-sided RDMA write
int page_write(const Address local_addr, const Address remote_addr);
// page_invalidate is called by RW to invalidate all copies of a given page in RO nodes’ local cache.
int page_invalidate(PageID page_id);
从这些接口的设计来看,感觉PolarDB Serverless将remote memory当做是storage之外的一种类似的存储资源,而不想是当做是一种shared memory。其访问的接口都是要先copy到本地,更新之后从本地copy到remote memory。而为了处理可能同时保存一个local copy,增加了page_invalidate来使得其它RO节点上面保存的失效的接口,这样也主要是优化其面提到的一些问题,比如访问速度比local memory慢。在remote memory管理上,先将其划分为1GB大小的slab。Slab实现的是Page Array (PA),为一些连续的16KB的pages,这些内存启动的时候就会被注册到 RDMA NIC,这样就可以直接通过RDMA访问。其所在的节点称之为slab node,每个数据库实例的slab内存资源被分布到多个slab nodes上。另外还会安排一个home node,记录了一些额外的metadata(The slab node where the first slab is located is assigned as the home node. ):
-
其它一些结构:Page Address Table (PAT) ,PolarDB Serverless使用一个hash table,PAT,来保存location(slab node id 和 physical memory address)到ref count的映射。使用一个bitmap,Page Invalidation Bitmap (PIB),来记录对应pages的invalidation bit,为0表示memory pool中的为最后的版本,为1时表示RW节点已将其更新但是还没有写回到remote memory pool。RO节点本地也会有一个local PIB,记录local cache中page是否是最新的;使用Page Reference Directory (PRD) 来记录page到那些nodes通过page_register获取了这个page的引用。Page Latch Table (PLT) 保存PAT中每个entry对用的一个page latch (PL) ,其作为一个 global physical lock,
PLT manages a page latch (PL) for each entry in the PAT table. PL is a global physical lock protecting and synchronizing read and write on pages between different database nodes. Especially it is used to protect the B+ Tree’s structural integrity when multiple database nodes access the same index concurrently -
数据库节点通过
page_register分配page的时候,是通过home node来处理。在不存在的情况下,home node会从最空闲的节点中分配一个page,砸了slab没有空闲空间的情况下,会以LRU的方式驱逐refcount为0的pages。Page在驱逐的时候为dirty page也是ok的,因为存储层支持从redo log中构建。分配之后,home node会在PAT中记录,然后返回地址和page latch的数据给caller。Home node管理的空间可以很方便支持动态的扩缩容。
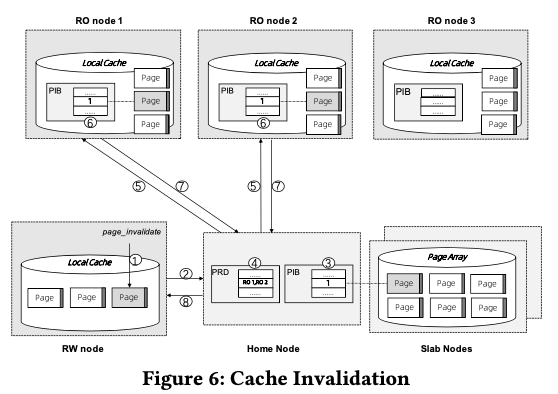
Remote memory和local memory速度的差异造成来直接修改数据是一个比较慢操作。这里的作为是引入Local Cache,这样修改page的操作就是在本地进行,然后在合适的时候写入会remote memory pool。Local Cache的大小是一个根据经验的设计,设置为min{1/8 * sizeof remote_memory,128GB},后面也可以工具hit ratio来动态调整大小。page_register在数据不存在memory pool的时候,会从存储层读取page然后写入到memory pool。Local cache也同样使用LRU的方式来管理,clean page释放的时候为直接free掉,dirty pages需要写回到remote memory pool,然后调用page_unregister。这样的设计首先要处理的就是Cache Coherency,RW节点在更新了一个memory pool 中的节点之后,需要通过cache invalidation的机制来通知RO节点page已经被更新。Cache invalidation基本操作过程如上图所示,RW节点调用page_invalidate经过home node来处理。
0x02 几个问题
引入了多个节点可能同时访问remote memory pool的pages之后,要处理的一个问题就是读写时间并发访问的时候,访问到一个一致的B+ tree结构的问题。由于一个时刻只会有一个节点,不同节点并发更改一个节点的情况不会有。这里要处理的一个问题是B+ tree的结构更新操作(SMO),比如page分裂操作,会涉及到多个page。RO节点就可以看到一个SMO操作过程中的一个中间状态,为此增加了一种 global physical latch,PL,来同步这样的更新操作。PL有S、X两种模式。SMO相关的pages会被加锁X类型的PL锁,读取一个page的时候需要加锁S类型的PL锁。这个PL锁不替代原来的锁,加锁的方式采用lock coupling的方式。而RW节点访问时候,一般情况下不需要进行SMO的操作,所以初次访问的时候都假设不会有SMO的操作,就不会去尝试加PL锁,只会加本地的latch。如果需要进行SMO的操作,则重试一次B+tree 查找的操作,并在相关的pages上加上加锁X类型的PL latchs。加锁的方式是使用fast path + negotiation两种方式结合的方法。
To speed up the PL-acquisition operation, we first try to use RDMA CAS operation to acquire the lock. If the fast path fails, for example, trying X-lock a PL that has been S-locked, which may occur when splitting the root node, then get the lock through negotiation among the home node and database nodes. The caller requesting the lock needs to wait for the negotiation to complete.
处理前面的Consistency为结构上的Consistency,另外一个Consistency是逻辑上的Consistency。PolarDB Serverless使用一个snapshot timestamp来决定一个事务看到的数据库的一个’snapshot‘。在RW节点内,PolarDB Serverless引入了一个centralized timestamp (sequence),称之为 CTS。和很多的MVCC实现的方式一样,一个读写事务在开始的时候获取一个时间戳cts_read,在要commit的时候申请一个cts_commit。在数据库记录和undo log记录中都会有一列,来保存cts_commit,另外数据库记录中还会记录创建这个version的事务的trx_id,这样以便于事务判断自己的修改。
-
这样的方式存在的一个问题是,对于大事务,将其修改的记录都更新上这个事务的cts commit会有太多的写入。所以这个操作最好能够异步进行。异步进行的话需要处理的问题是如果发现一个没有填上cts commit 字段的记录的提交时间戳?为此这里引入了一个CTS Log data,保存在RW节点中,为一个circular array的结构。其保存最近若干事务 (for example, the last 1,000,000)的cts_commit时间戳。如果一个事务还没有commit,则对应的commit时间戳为空,committed的时候就是commit时间戳。数据库节点在访问到一个记录,发现没有cts_commit,则通过访问RW节点上的CTS Log data方式来获取这个commit时间戳。这个CTS Log data结构是就是一个txn id到commit映射的结构/table。在一些分布式事务实现方式中也存在(Commit Table)。这个结构的访问可以通过one-sided RDMA read方式来实现高效率的访问。
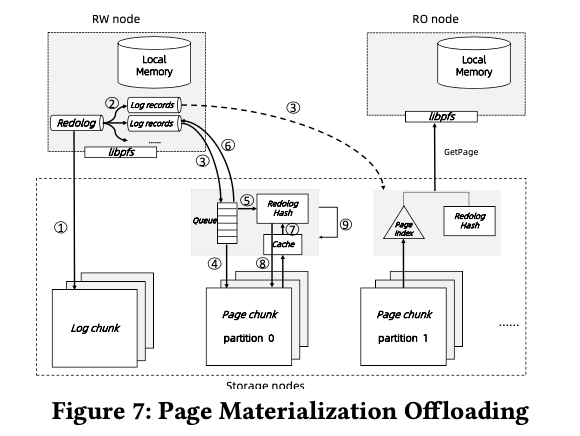
PolarDB Serverless同样引入了在其它类似数据库中,使用redolog在存储层构建出来page的方式,其基本方式如下图所示。RW节点会在事务commit之前flush redolog到log chunks,log复制3副本之后即完成写入也完成了事务的commit。redolog对应的部分会发给对应的page chunk,存储层的page chunk 保存了一个数据库的一个partition,一般partition以10GB为单位。一个page chunk的 leader node收到log之后,同样会持久化这些数据,并将其保存到一个以page id为key的hash table(value应该是一个根据LSN排序的redo log的list),然后恢复RW节点。RW节点收到回复之前不会驱逐对应的dirty pages。后台根据存储的旧版本的page和这个page上的log,来构建出新版本的page,然后被复制到其它的副本。为了支持从某一个时刻恢复(point-in-time recovery),会保存一个page的多个版本。而保存的redolog和旧版本的pages,会通过GC过程在合适的时候回收。对应GetPage请求,可能需要通过获取一个合适版本的page,然后结合对应访问内的redolog,来得到需要版本的page。
对于disaggregation的系统,一个优点是各类资源可以工具需要扩缩容。PolarDB Serverless支持透明,无缝的扩缩容。在这个过程中,或者是升级、迁移之类的事件的情况下。比如RW节点迁移为例,proxy节点在发现这些事件之后,暂停client连接的活动,等上一小段时间。等新RW节点替换了之前的RW节点之后,其重新连接新的RW节点,继续前面连接的活动,包括执行中的事务操作。对于大事务,proxy可以支持追踪一个savepoint(The savepoint indicates the execution progress of the transaction, i.e., the i-th statement since the beginning of the transaction. As a result)。RW切换之后,proxy可以通知新RW节点来从最后一个savepoint重新执行,而不是回滚操作。
0x03 Performance & Reliability
Disaggregation的设计从对性能是不利的。在性能优化这部分,Paper中提到的性能优化主要是两个:Optimistic Locking和Index-Awared Prefetching。
-
前面提到RW节点是一种乐观在PL锁的操作,第一次都是不加的。但是RO节点是每次都会尝试加PL锁,这个操作在使用RDMA支持之后,开销还是不小的。其优化的做法也是引入乐观的操作方式,在root-to-leaf查找的过程中,先假设索引结构没有SMO操作,不去获取PL锁。然后在RW节点维护一个SMO操作计数器,早发生一次SMO操作的时候加1,同时SMO操作时候这个计数值会记录在相关的page中。在查询开始的时候,获取一次这个计数器的值,在查询的过程中,遇到了page上保存的计数值比查询开始时候获取的值更大的,则表明发生了可能导致不一致的SMO操作。
-
数据预取也是一个优化的策略,这里使用的方式称之为Batched Key PrePare,BKP。比如对于select name, address, mail from employee where age > 17这样一个使用二级索引的查询。MySQL中的实现是先查询secondary index,找到符合数据的数据,在根据secondary index中保存了primary index的key来去primary index取回数据,第二步可能有随机查找的操作。根据这里的简短的描述,BKP的基本思路就是给一组的keys,然后进行余个预期的操作,
... the interface of BKP accepts a group of keys to be prefetched. When the interface is called, the engine will start a background prefetching task, retrieves required keys from the target index and fetches corresponding data pages from the remote memory/storage when necessary.这个预取机制同样可以优化分析型的workloads,应该基本是就是scan数据的时候可以提前预取数据。
Reliability
Failover方面,数据库节点处理是比较麻烦的,其它的相对来说简单一些?RO节点故障的时候,一般使用一个替代即可。对于RW节点。 Cluster Manager (CM) 通过心跳的方式发现之后,会通过如下的步骤,来使用一个RO节点来替代故障的RW节点:
- CM先通知所有的内存节点和存储节点不在接受来自原来RW节点的写入。应该是为了处理根据心跳探测做出来错误的决策 或者是 在RW failover过程中恢复的情况。然后选择一个RO提升为新的RW节点, RW’;
- RW‘ 节点通过获取每个page chunk的最新版本(last version, LSN-chunk)。其中最小的作为Checkpoint Version, LSN-cp。RW’ 再去Log Chunk上面持久化的redolog,获取上一个checkpoint到redolog tail的redologs,分发到page chunks,等他们消费redologs完成。前面者几个操作就是REDO的阶段。如何RW ‘节点扫描remote memory pool,将invalid 以及 其版本(LSN-page) 比 LSN-tail更新的,这些pages删除。然后是否其面RW节点获取的PL锁。这
- RW‘ 在通过undo header来恢复在前面RW节点故障时候活跃的事务,恢复这些事务的状态。这个时候就可以通知CM来告诉其处理完成,可以接受写入请求。通过undo logs会滚事务在后面后台的方式进行。
对于计划的节点关闭,主要是增加了主动释放lock,flush dirty pages之类的操作。对于系统里面stateless的节点failover,一般来说就是使用多个,一个故障之后直接替换即可。对于slab node,其上保存的数据是持久化了的,节点故障不用处理数据恢复的问题。在home node上保存了比较多的关于remote memory pool的元数据,比如前面提到的几个tables。这里使用的策略是使用同步的方式复制到一个slave replica(政治不正确的名称(´・_・`))。Home node检查slab node故障之后,故障节点上面被register了的pages可以通过PAT知道,page可以通过从RW节点的local cache恢复,或者是直接通过page_unregister来移除。在所有的home nodes不可用的情况下,通过重启所有的数据库nodes和memory nodes重启系统的方式解决。
0x04 评估
这里具体的内容可以参看[2].
参考
- PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers, SIGMOD ‘21.
