LogStore: A Cloud-Native and Multi-Tenant Log Database
0x00 基本内容
这篇Paper是将要发布在SIGMOD ‘21上面一排关于Log存储的一篇。LogStore像是一种特别类型的AP系统,其的基本架构如下图,其架构称之为cloud native的,很多基础的组件依赖于云厂商自己的一些系统。LogStore为一个shared data和shared nothing结合的一个设计,且计算和存储分离。主要的存储使用了对象存储服务。LogStore写入的数据实时可见,因为它将最近写入的数据保存到本地的磁盘上,然后通过Raft来复制多个副本。随着数据的持续写入,本地磁盘上面的数据会最终被上传到对象存储OSS上。
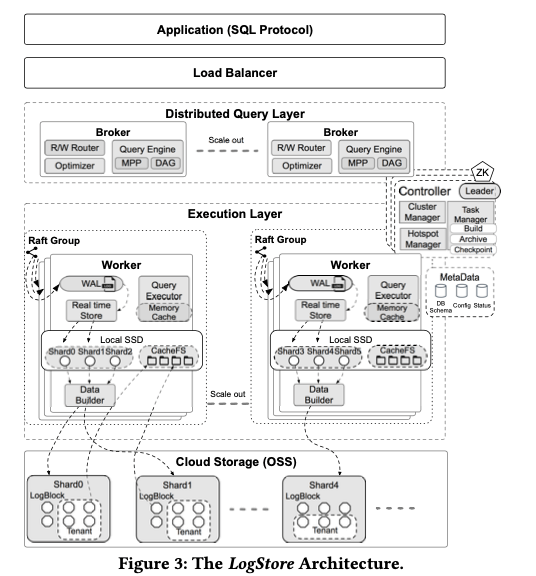
数据保存到本地磁盘上面的时候会以write-optimized row-oriented的存储格式保存,不会建立上面索引之类的。在数据写入OSS之前,LogStore会对其进行重新组织,组织为一种 read-optimized column-oriented indexed的格式,称之为LogBlock,并压缩。这个LogBlock根据不同租户和日志产生时间戳来划分。在主要的组件上,Controller来负责整个集群的管理;Query Layer会根据用户的查询请求生成directed acyclic graph (DAG)模式的一个执行计划。这个查询计划会被划分为sub-queries方法到后面的Execution Layer;Execution Layer要处理最近数据的写入,以及将增长了的本地数据转存到OSS上。查询的时候要负责执行计划的具体执行。后面的存储层直接使用已有的对象存储服务OSS。
0x01 Multi-Tenant
这篇Paper中,从标题和内容都强调了其Multi-Tenant的一些特性。在cloud的环境中,不同的tenant之间的workload差异是很大的,比如大部分的tenant都是较少活动,而少数的tenants贡献了大部分的数据;比如流量的不均衡性特别突出等。因为这样,Paper中中也较多地描述了LogStore在load balance方面的一些设计。因为不均衡的特点突出,LogStore使用根据运行时候的情况来动态负载均衡。负责均衡上关于global traffic control,LogStore使用的方式示意如下图。其会将系统抽象为一个single source/single sink flow network G(V , E),这个network中节点表示某种角色,边表示流量。抽象之后,将load balancing变成了一个最优化的问题,其的目标是最大化从源到目的T的流量,满足的限制条件主要有要最小化请求/流量routes,另外要满足一些容量限制,比如一个节点上的资源利用率不能太高等。
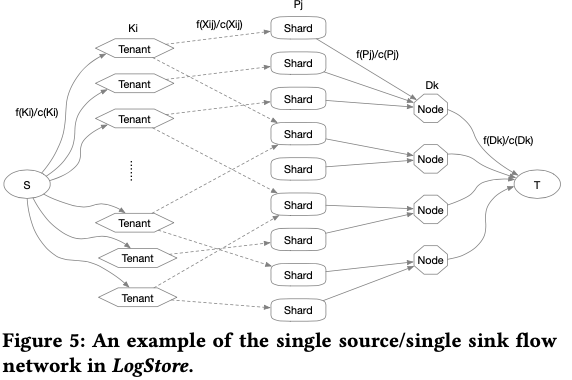
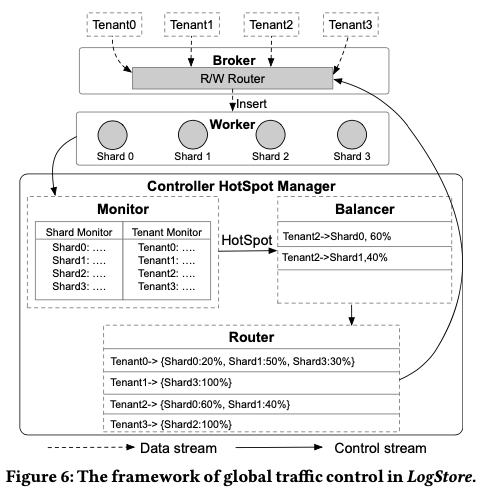
LogStore是根据前面的建模,然后根据其traffic control的算法来算出Router的table,Broker在方法任务到Worker的时候,根据这个table来作出方法任务到哪里的决策。其global traffic control的framework表示如下图。下图的HotSpot Manager实现在Controller这个组件中。其运行的时候,首先是要一个Monitor来获取运行时的一些信息,比如一个tenant的流量f (Ki ),shard的负载 f (Pj ),一个worker节点的负载 f (Dk )。其它的一些信息比如shared和worker的能力/capacity是根据系统配置而来的相对固定的数据。工具运行时的检测,发现了一些不平衡/HotSpot之后,使用一些算法来重新生成Router表中的信息,重新调度流量:一种贪心方式为检测一个节点上面流量最大的一些tenants,然后将这些tenant的流量重新调度;使用Max-Flow的算法可以理论上可以生成更好的调度决策。
在优化流量route之外,LogStore还使用Backpressure,背压的方式来给发送端一个消息,来通知其系统目前的处理能力达到了一个限制,这里将其称之为backpressure flow control (BFC) 。在LogStore的执行节点上面,会使用buffer queue来接受收到的数据,已经从buffer queue中获取数据来进行处理。通过这些buffer queues来做一个异步处理过程中数据一个中转的地方。BFC通过监控这些buffer queues长度的情况来作出决策,如果超过了一定的阈值,BFC会做出一些拒绝继续写入的决策。拒绝是逐步的增加的,比如突然由不拒绝到拒绝。另外BFC也被加入到Raft之中,在Raft运行过程中leader同步数据到follwers和各个节点写WAL都可能被block,这里也加入了两个queues,sync_queue和apply_queue,在必要的时候给一个信息使得请求端降低速率。
0x02 存储 与 查询
LogStore使用LogBlock作为基本的存储单位,一个LogBlock为自描述、高度压缩的列存格式数据。LogBlock的格式中包含header, column meta, index, column block header 和 column block这样的几个部分。header记录一些table shema的信息,以及记录数量、column元数据位置等的信息;column meta部分记录column部分使用什么样的压缩方式,以及Small Materialized Aggregates (SMA) ,即一些统计信息,比如最大值最小值之类的,还有column index的位置信息等以及column block headers的位置信息等;column block headers中则记录行数量、block的SMA数据已经column data的位置等的信息;column data则是数据本身。LogStore会为每个column家建立一个index,目前支持 inverted index 和 BKD tree index,前者用于string类型,后者用于numerical类型,另外整体的LogBlock会记录下一些SMA的数据,其中的每个block也会记录block内的一些SMA数据。这种类型的数据是一种AP类型的数据,计算又和存储分离,为例提高查询的性能,LogStore主要是使用一些data skipping策略来过滤掉不符合条件的数据,以及multi-level data cache的方式,还有 parallel prefetch 等:
-
Data Skipping的策略尝试从多个level来跳过不会包含预期数据的数据。一如下的查询为例:skip掉LogBlocks的方式,可通过一个LogBlock map。这个map会以tenant id,最小时间戳,最大时间戳最为key,LogBlock的位置作为value。下面where条件中的前面3个条件可以使用这个map来跳过不需要获取的LogBlocks。
SELECT log FROM request_log WHERE tenant_id = 12276 AND ts >= '2020-11-11 00:00:00' AND ts <= '2020-11-11 01:00:00' AND ip = '192.168.0.1' AND latency >= 100 AND fail = 'false'在一个LogBlock之内,根据每个column的条件,比如latency >= 100,然后根据每个column对应SMA的信息来跳过是否整个column都不满足条件。一个column里面存在满足条件的在根据这个column 的column block找到符合条件的block等。
The entire column can be filtered using the <min,max> statistics of each column (fail in this example). For column blocks that cannot be filtered by the predicate on the columns, the rowid of all rows that meet the predicate will be collected by fetching and looking up the index. For columns that have not been indexed, the entire column block can be filtered using the column block’s <min,max> statistics, -
LogStore使用了multl level的cache策略,基本方式示意如下图。OSS中保存的文件会包含多个的LogBlocks,为的是避免创建了数据过多的objects,而为了读OSS数据的时候读不相关的时候,每个LogBlock可以单独读取,可以利用其Range Get的功能,HTTP Range。从OSS中读取的数据会先保存到内存中的一个block cache,这个cache的容量超过了一个阈值之后,会淘汰一部分数据到本地SSD上的block cache上。在Block Cache的上层为Object Cache,这个可以缓存一些最近频繁访问的object,避免频繁实例化对象带来的开销(prevent frequent object allocations, which greatly increases the frequency of JVM GC),这个可以看出LogStore应该是Java开发的。
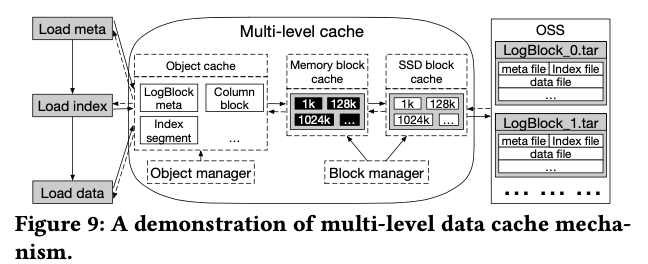
另外的一个部分为prefetch的策略,工具保存在OSS中文件的元数据,来并发地获取数据( Before parallel loading, the file to be prefetched should be divided into data blocks according to the metadata, and repeated data block read IO requests will be merged to avoid repeated loading).
0x03 评估
这里可以参看[1]来看看其的一些特点。
参考
- LogStore: A Cloud-Native and Multi-Tenant Log Database, SIGMOD ‘21.
