Chubby and Zookeeper
引言
这篇两篇论文也是一个重量级的论文,对现在的很多的系统的设计产生了很大的影响。 Chubby是Google基于Paxos的分布式锁服务,Zookeeper是雅虎在基于Chubby论文开发的一个开源版本,两者的论文都是讲的是系统的一些东西,比如接口抽象、事件、API和锁之类的东西,咸鱼觉得这个的重点在与它们使用的distributed consensus protocol(分布式共识协议)以及这个protocol的实现(chubby使用的就是Multi-Paxos,而Zookeeper使用了一个变体Zab),在此基础上的抽象反而是次要的。本来这篇总结是关于Chubby论文的,回来发现论文里面没啥有意思的,就把Zookeeper加进来对比一下。这里就基本总结一下它们提供了怎么样的抽象。并对比一下,关于分布式共识协议在之后的总结中。对于Chubby。Chubby的两个关键的设计决定是:
- 将Chubby设计为一个锁服务,而不是一个库或者是一个共识服务;
- 使用一种文件的方式;
Chubby倾向于只提供粗粒度的锁服务。回来的Zookeeper也基本沿用了Chubby的思路。一些决定Chubby设计的因素,这些因素由Google期望如何使用Chuuby以及Google的环境决定的:
• A service advertising its primary via a Chubby file may have thousands of clients. Therefore, we must allow thousands of clients to observe this file, prefer- ably without needing many servers.
• Clients and replicas of a replicated service may wish to know when the service’s primary changes. This suggests that an event notification mechanism would be useful to avoid polling.
• Even if clients need not poll files periodically, many will; this is a consequence of supporting many developers. Thus, caching of files is desirable.
• Our developers are confused by non-intuitive caching semantics, so we prefer consistent caching.
• To avoid both financial loss and jail time, we provide security mechanisms, including access control.
而对于Zookeeper总体上还是沿用了Chubby的抽象方式。虽然它们干的事情很类似,不过它们的设计目的上还是存在一些区别的,Chubby的核心设计目标是(强调的是锁服务):
We describe our experiences with the Chubby lock service, which is intended to provide coarse-grained locking as well as reliable (though low-volume) storage for a loosely-coupled distributed system. Chubby provides an interface much like a distributed file system with advisory locks, but the design emphasis is on availability and reliability, as opposed to high performance.
而Zookeeper的则是(强调的是一个“kernel”,可以理解为zookeeper提供的是一些基本的“原语”,用户在这些原语的基础上实现其它的东西,比如锁服务,配置中心):
ZooKeeper, a service for coordinating processes of distributed applications. Since ZooKeeper is part of critical infrastructure, ZooKeeper aims to provide a simple and high performance kernel for building more complex coordination primitives at the client. It incorporates elements from group messaging, shared registers, and distributed lock services in a replicated, centralized service.
基本架构
Chubby大体的架构看上去比较简单(实际上一点都不简单):
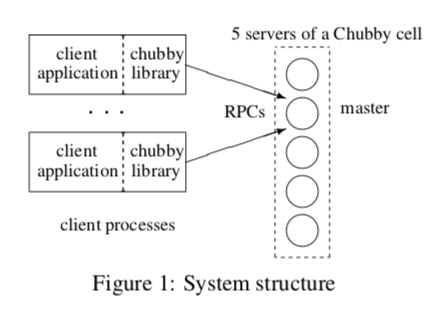
Chubby主要由两部分组成,一个是客户端使用的库,一部分就是Chubby Cell。还有就是一个可选的代理服务。在这个图上没有表现出来。这里的库没有什么好说的,之间忽略。一个Chubby Cell通常由5个服务器组成,着5个副本由 分布式共识协议来选举出一个Master,其它副本都都复制了一份Master上的数据,但是只有Master处理读写请求。客户端通过发送请求给这些副本,它们会返回Master的信息。这里Zookeeper的基本架构师几乎是一样的,然后优点组件的名字叫法不一样。不一样的地方在与能够读的结点,在Zookeeper中,它特别强调了为读的优化,所以Zookeeper的所有结点都是可以读的,这样就获得很好的读的性能:
Read requests are handled locally at each server. Each read request is processed and tagged with a zxid that corresponds to the last transaction seen by the server. This zxid defines the partial order of the read requests with respect to the write requests. By processing reads locally, we obtain excellent read performance because it is just an in-memory operation on the local server, and there is no disk activity or agreement protocol to run. This design choice is key to achieving our goal of excellent performance with read-dominant workloads.
不过这样做的缺点就是一个读的操作可能读到旧的值,而由于Chubby读写都是Master处理的,所以Chubby能够保证能够读到最新的值,这个是设计上不同的取舍。Zookeeper为支持某些应用对这个特性的要求,添加一种叫做sync的机制,它可以用来保证读能返回最新的值。在Zookeeper的论文中,表面了它提供了两个基本的顺序保证:1. 所有的写操作都是按顺序完成的,2. 对于一个客户端来说,它的读写请求都是按顺序完成的。这里也就是,一个客户端的读和另外客户端的写是不保证按顺序完成的,这样也就是导致了前面提到的读操作可能返回旧的值的问题。
Linearizable writes: all requests that update the state of ZooKeeper are serializable and respect precedence;
FIFO client order: all requests from a given client are executed in the order that they were sent by the client.
关于共识协议的就不写在这篇总结中了,因为内容比较多。
文件,目录,句柄 和 事件
Chubby和Zookeeper提供的都是类似Unix文件系统的抽象:
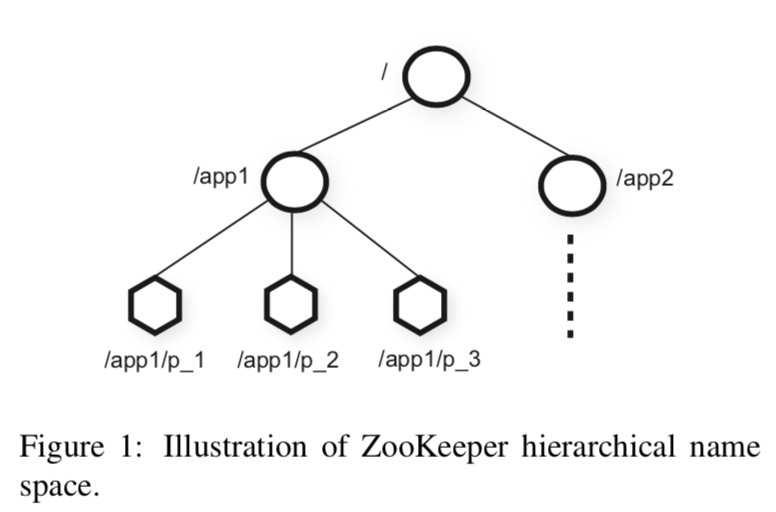
这里两个之间一个不同的地方就是Chubby更加像一个文件系统上面的操作,每次操作文件之前先打开,使用完毕之后要关闭,而Zookeeper都是使用完整的路径直接处理,不用打开关闭之类的操作,Chubby将打开的文件描述叫做据柄(handle),其它的操作都是在这个句柄上面完成的:
Open() opens a named file or directory to produce a handle, analogous to a UNIX file descriptor. Only this call takes a node name; all others operate on handles.
而Zookeeper则简单使用Path处理就行了:
Note that ZooKeeper does not use handles to access znodes. Each request instead includes the full path of the znode being operated on. Not only does this choice simplifies the API (no open() or close() methods), but it also eliminates extra state that the server would need to maintain.
为了通知客户端某些事件的发生,两个都提供了通知的机制,Chubby中叫做Events,Zookeeper中叫做Watcher。 此外关于访问控制,Chubby的论文中明确表示了它使用了ACL,而Zookeeper的论文中没有提及,但是现在它是有ACL机制的。
锁 和 其它API
对于锁,Chubby是直接提供了相关的接口(因为它就是设计一个锁服务),它可以直接使用
Acquire(), TryAcquire(), Release()
来获取和是否一个锁,操作比Zookeeper简单不少。而在Zookeeper中,有与让提供的是基本的API,需要客户在此的基础上实现锁的API,它直接使用的是创建文件的方式。比如:
Lock
1. n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2. C = getChildren(l, false)
3. if n is lowest znode in C, exit
4. p = znode in C ordered just before n
5. if exists(p, true) wait for watch event
6. goto 2
Unlock
1. delete(n)
处理这简单的锁之外,Zookeeper还可以创建读写锁,这里写锁的创建和前面的简单锁是一样的,不同的在读锁的第5 6行的方法中存在些许区别:
Write Lock
1. n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2. C = getChildren(l, false)
3. if n is lowest znode in C, exit
4. p = znode in C ordered just before n
5. if exists(p, true) wait for event
6. goto 2
Read Lock
1. n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2. C = getChildren(l, false)
3. if no write znodes lower than n in C, exit
4. p = write znode in C ordered just before n
5. if exists(p, true) wait for event
6. goto 3
此外,Chubby还直接提供了序列的服务,使用GetSequencer(),SetSequencer() , CheckSequencer()三个接口。
缓存
Chubby的客户端实现了缓存的功能,它会缓存文件数据和元数据。为了满足一致性,这个cache的操作是直接写回的。此外,当文件数据和元数据更改时,Chubby会有相应的机制来对客户端缓存的数据进行更新。这些都是自动完成的,使用Chubby的用户不同担心or处理这些问题。
When file data or meta-data is to be changed, the modification is blocked while the master sends invalidations for the data to every client that may have cached it; this mechanism sits on top of KeepAlive RPCs.
而对于Zookeeper来说,它就没有提供这类的功能,要使用的话只能由客户端利用Zookeeper提供的API去自己实现。
Sessions 和 KeepAlives
在Zookeeper中,session在客户端连接服务端的时候就会初始化session,这个session会有一个超时的时间。从这里看Zookeeper会定时地和客户端进行信息通信,来确保客户端还是存活的,当然这里用来探测服务端是否存活也是一样的吧?这个session会在客户端显示的关闭or故障的情况下结束。这个session还使得客户端可以更加透明地由一台服务器迁移到另外一台服务器。在Chubby中,这里的处理方式和Zookeeper的很相似,也是使用了session来保存客户端和服务器的连接信息,使用keepalives来探查服务是否正常。
A Chubby session is a relationship between a Chubby cell and a Chubby client; it exists for some interval of time, and is maintained by periodic handshakes called KeepAlives. Unless a Chubby client informs the master otherwise, the client’s handles, locks, and cached data all remain valid provided its session remains valid.
故障切换
关于故障切换的部分在Chubby的论文中是有专门的一节,在Zookeeper的论文中是没有专门去将这个问题,应该它的意思是这个事共识协议处理的吧。下面这幅图显示来Chubby处理Master失败的过程:
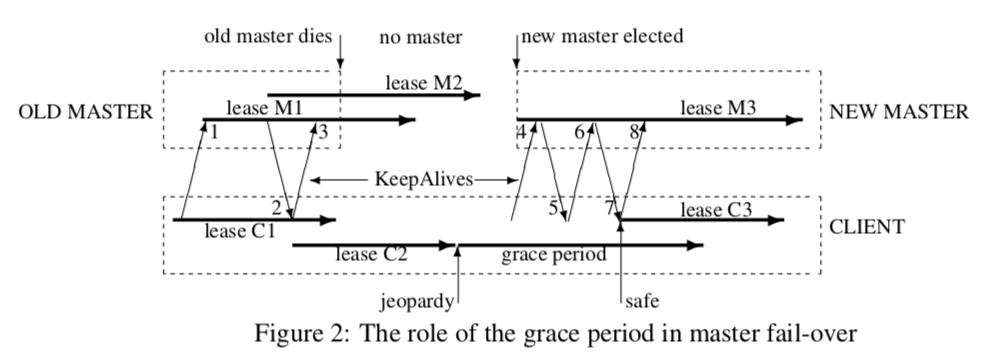
在旧的Master出现故障不能正常服务之后,keepalives的请求将会无法正常完成,这个时候客户端就会发现异常(但是这里要主要keepalives请求无法正常完成并不代表一定是Master故障了,也可能是这个client和Master之间的网络不通了),这个时候client就会进入一个grace period ,这个时候client并不能完全确定它的租约在主机上已经过期了。Client在这里会暂停处理应用的请求,同时会给应用发送一个 jeopardy 事件。这里Chubby处理的整个过程的步骤有9步,很多内容,这里最好参看原论文比较好。
优化
这个部分也只在Chubby的论文中存在,主要讲的事如何使用代理来优化系统的性能:
A proxy can reduce server load by handling both KeepAlive and read requests; it cannot reduce write traffic, which passes through the proxy’s cache. But even with aggressive client caching, write traffic constitutes much less than one percent of Chubby’s normal workload
另外的一个优化方式就是分区,Chubby也使用了常见的利用hash分区的方式,这里还有更多细节的问题,具体可参看原论文.
Chubby’s interface was chosen so that the name space of a cell could be partitioned between servers. Although we have not yet needed it, the code can partition the name space by directory. If enabled, a Chubby cell would be composed of N partitions, each of which has a set of replicas and a master. Every node D/C in directory D would be stored on the partition P(D/C) = hash(D) mod N. Note that the meta-data for D may be stored on a different partition P(D) = hash(D′) mod N, where D′ is the parent of D.
参考
- The Chubby Lock Service for Loosely-coupled Distributed Systems, OSDI 2006.
- ZooKeeper: Wait-free coordination for Internet-scale systems, ATC’10.
