The Google File System
引言
GFS(or其后继者)是Google诸多系统依赖的基础,包括Mapreduce、Bigtable已经Spanner等。不同于单机上面的文件系统,GFS专门为分布式环境下存储只追加不修改的大文件设计的。另外,了解GFS的设计这些设计目标or设计假设是了解GFS的前提:
- 系统中的组件出现故障时常态,所以系统必须自己能够处理这些情况;
- GFS主要就是大文件设计的,一般都在100M以上,GB级别的文件很常见,虽然系统要支持小文件,但是不做优化;
- 系统的操作主要有大的连续读和小的随机读构成;
- 负载中有大量的顺序的追加的写操作。文件一旦写入,就很少修改。小的在任意位置的写入也被支持,但是效率可能很低;
- 系统必须提供良好的语义支持多个客户端的部分追加操作。这里实现同步开销小的原子性追加支持很重要;
- 包吞吐的优先级放在延时之前,也就是说一实现高的吞吐为目标;
基本架构
GFS的架构影响了很面很多类似系统的设计,主题部分有一个单一的Master和多个Chunkserver组成,此外还包括了一个客户端:
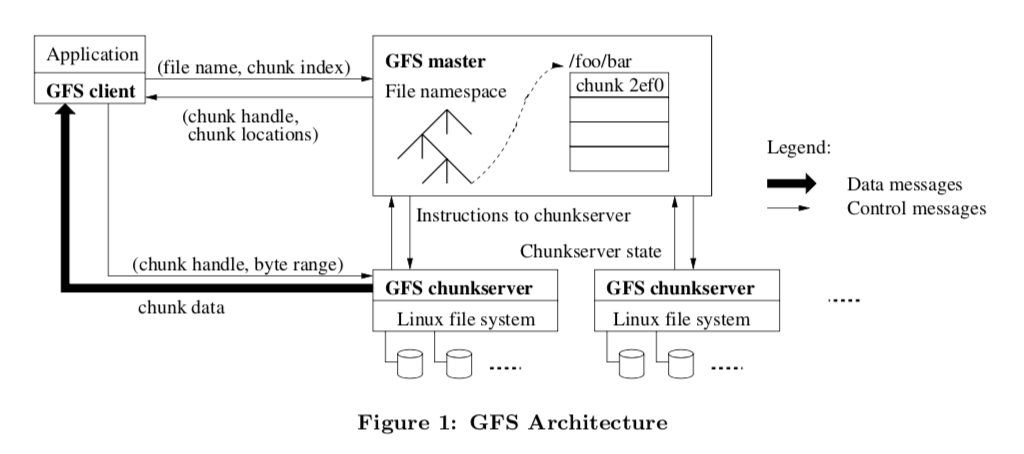
在GFS中,文件被分为固定大小的chunks,每一个chunk有会有一个全局唯一的不可变的64bit的id标示,在这个chunk被创建时赋予。Chunkserver就负责保存这些chunk。未来可靠性,这里一般把chunk复制3份保存。Master则是用来保存元数据的,它包含了namespace,访问控制信息,文件到chunk的映射关系以及现在这些chunk的位置。此外,Master管理chunk租约,孤儿chunk垃圾回收以及chunk在chunkserver之间的迁移。Master和Chunkserver之间通过定时的HeartBeat信息交互。客户端通过GFS的库对GFS进行操作,读写文件时,要先从Master回去文件的元数据信息,然后去Chunkserver进行实际的读写操作。GFS不提供POSIX语义的文件操作接口,也没有什么Cache:
Neither the client nor the chunkserver caches file data. Client caches offer little benefit because most applications stream through huge files or have working sets too large to be cached. Not having them simplifies the client and the overall system by eliminating cache coherence issues. (Clients do cache metadata, however.) Chunkservers need not cache file data because chunks are stored as local files and so Linux’s buffer cache already keeps frequently accessed data in memory.
在GFS中,Master是单个的,这个设计极大地简化了系统的设计,当然也有一些缺点。论文中说明了这么设计的理由,也解释了单Master存在的缺点在目前(写论文的那个时候)是没有什么问题的。GFS中的Chunk的大小一般为64MB,这个设计就是为大文件设计的。大的chunk尺寸带来的好处就是减少了客户端和Master的交互,操作一个文件时客户端需要从Master获取的数据就少了。大的Chunk尺寸也减少了元数据的大小。GFS的设计中,元数据会保持在内存里面的。当然这个也带了了一些缺点,最明显的一个就是对小文件的支持很不友好,另外还可能造成热点的问题,但是在实际中又好像问题不大:
A small file consists of a small number of chunks, perhaps just one. The chunkservers storing those chunks may become hot spots if many clients are accessing the same file. In practice, hot spots have not been a major issue because our applications mostly read large multi-chunk files sequentially.
元数据
系统的元数据主要包含了以下三类:
- 文件和chunk的namespace;
- 文件到chunk的映射;
- 以及chunk的位置信息。
这些数据都保保存在Master的内存之中。此外,前面2种类型的元数据还会被Master使用operation log的方式持久化到硬盘上面,然后会被复制到其它的机器之上,
Using a log allows us to update the master state simply, reliably, and without risking inconsistencies in the event of a master crash.
Master不需要持久化chunk位置信息的原因是这些信息一旦由于故障之类的问题丢失了也可以重新从Chunkserver上面获取。
-
In-Memory Data Structures,Master讲元数据保存在内存里面的设计使得Master的操作可以非常快,同时也使得定期扫描整个系统的状态变得更加简单,
This periodic scanning is used to implement chunk garbage collection, re-replication in the presence of chunkserver failures, and chunk migration to balance load and disk space usage across chunkservers.关于Master的内存中能够容纳多少元数据的问题,在论文中说每一个chunk的元数据一般小于64bytes,所以这个在面前的应用中不是问题(在写这篇论文的时候)。
-
Chunk Locations,前面说过了chunk的位置信息是不被Master持久化的。Master可以通过轮询每一个Chunkserver的方式来获取所有的chunk的位置信息。Google在实际应用中发现了不持久化这些数据是一个更加好的选择:
We initially attempted to keep chunk location information persistently at the master, but we decided that it was much simpler to request the data from chunkservers at startup, and periodically thereafter. This eliminated the problem of keeping the master and chunkservers in sync as chunkservers join and leave the cluster, change names, fail, restart, and so on. In a cluster with hundreds of servers, these events happen all too often. -
Operation Log,这个log包含了GFS的关键的元数据的变化历史记录。Log在这里的作用不仅仅是吃持久化这些元数据,而且还是定义了并发操作的顺序。对于文件、chunk以及它们的版本来说,都是由它们被创建时候的逻辑事件唯一确定的。为了保证这些数据的持久化,GFS只有在讲这些数据保存到磁盘上并且复制到其它一些机器上之后才会给客户端返回信息。此外,为了减少log的数量,这里也使用了checkpoint的机制,故障恢复的时候利用checkpoint可以有效减少恢复消耗的时间,
Recovery needs only the latest complete checkpoint and subsequent log files. Older checkpoints and log files can be freely deleted, though we keep a few around to guard against catastrophes. A failure during checkpointing does not affect correctness because the recovery code detects and skips incomplete checkpoints.
一致性模型
一致性模型是GFS中非常重要的一个部分,GFS提供什么样的一致性模型对依赖于GFS的一些系统产生了直接的影响。首先,由于元数据在GFS中由单一的Master管理,所以这里的可以保证操作是原子的。前面提到的Master的operation log定义了这些操作的全局的顺序。文件数据的修改和元数据的修改存在比较大的区别,这里要先弄清楚文件被修改之后可能达到的状态:
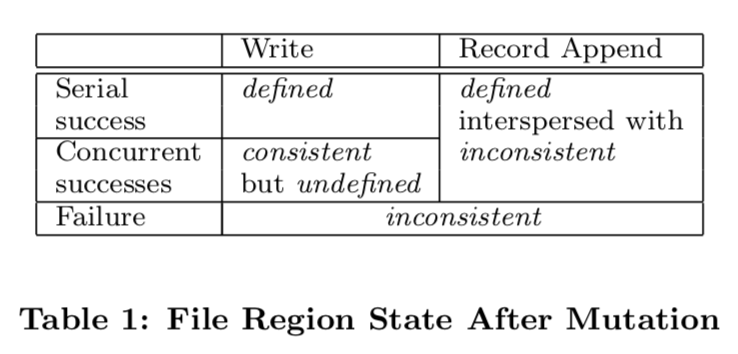
- consistent,当所有的客户端无论读取哪一个副本的数据都看到相同的数据的时候,就说这个数据是consistent的;
- defined,defined首先得是consistent的,然后还要满足客户端能够看到修改操作之后的完整的内容;当一个修改操作成功了而且没有收到其它的并发修改操作的影响,那么这个操作的区域就会是defined的,所有的客户端都会看到相同的修改操作完成之后的数据。一个并发的修改操作可能导致undedined但是是consistent的,也就是说所有的客户端都能看到相同的数据,但是这些数据不能反映任何一个修改操作之后的数据。
- in-consistent,当一个修改操作是失败的时候,它就会使得这个区域的数据进入in-consistent状态。不同的客户端在不同的时候看到的是不同的数据。
上面说到的修改的操作可以是写or追加操作。这里的写操作是指在文件指定偏移的位置写入数据,GFS对这个操作支持很不好,GFS不推荐使用这种方式。这个操作在GFS中没有serializable保证的,这个操作可能导致这个区别里面的数据是不同客户端的数据碎片组成的:
GFS provides an atomic append operation called record append. In a traditional write, the client specifies the offset at which data is to be written. Concurrent writes to the same region are not serializable: the region may end up containing data fragments from multiple clients. In a record append, however, the client specifies only the data.
另外,一个很重要的特点就是GFS对追加的操作,保证的是atomically at least once的,也就是说这里是存在被GFS加入padding数据 or 重复的数据的可能的,不过在论文中这个数据的量非常小,这一段很重要,待会在后面会解释为什么会出现padding or 重复的数据。
A record append causes data (the “record”) to be appended atomically at least once even in the presence of concurrent mutations, but at an offset of GFS’s choosing. The offset is returned to the client and marks the beginning of a defined region that contains the record. In addition, GFS may insert padding or record duplicates in between. They occupy regions considered to be inconsistent and are typically dwarfed by the amount of user data.
GFS的这个特点使得有时候需要客户端由相关的处理机制。由于客户端存在Cache,当这些数据没有刷新的时候,使用客户端可能从一个就的副本中读到数据。可能产生这个现象的时间的窗口有Cache的过期时间决定和下一次的打开文件的操作。这里由于大部分的修改操作都是添加,所以这里更加可能的是文件提前结束,而不是读取了旧的数据。一个副本出现故障之后可能对数据造成损坏or丢失。GFS通过Master和Chunkserber之间的类型心跳的机制探测服务器的状态。对于读取的数据,会计算校验和。对于有问题的数据,会加快的从正常的副本中恢复。
GFS identifies failed chunkservers by regular handshakes between master and all chunkservers and detects data corruption by checksumming. Once a problem surfaces, the data is restored from valid replicas as soon as possible. A chunk is lost irreversibly only if all its replicas are lost before GFS can react, typically within minutes. Even in this case, it be- comes unavailable, not corrupted: applications receive clear errors rather than corrupt data.
GFS的一致性的特点对使用GFS的应用来讲,最好就是使用追加的操作,并且使用校验和。在需要的时候可以使用唯一的标志符来避免重复数据的影响。
If it cannot tolerate the occasional duplicates (e.g., if they would trigger non-idempotent operations), it can filter them out using unique identifiers in the records, which are often needed anyway to name corresponding application entities such as web documents.
系统交互
在GFS的设计中,一个设计思想就是尽量减少Master的参与。所以系统中的一些交互要考虑到这个设计背景。
Leases and Mutation Order & Data Flow
为了使得修改操作有着一定的顺序,GFS使用租约的方式使得副本中的一个为Primary。这个Primary选择一个顺序应用这些修改。所有的副本都是用Primary决定的这个顺序。这个租约的一般为60s,Primary可以申请续租。当Master和这个Primary失去联系时,可以在它的租约过期后安全安排新的Primary。

关于这里的操作过程和数据流有不少的细节,可以参看原论文。这里写入操作的操作步骤如下:
- 客户端询问Master哪一个Chunkserver拥有租约,即为Primary。。如果这个时候没有Chunkserver为Primary,则Master会在副本中指定一个;
- Master回复客户端Primary和其它的Chunckserver副本的信息。这写数据可以缓存,只有当Masger变得不可用 or 之前的租约失效的时候才会重新请求;
- 客户端会将数据发送到所有的Chunkserber的副本,当然也可以有其它的优化的方式,如上图所示。GFS采用控制流和数据流分开的策略;
- 当所有的副本接受到这些数据的时候,客户端向其中的Primary发送写的请求。Priamry会给它接受到的数据赋予一个编号,这个标号也代表了处理这些数据的顺序;
- 这个写请求会被Primary转发到其它的副本,其它的副本处理这些请求顺序的时候也会按照Primary安排的顺序来处理;
- 副本完成操作之后回复Primary;
- Primary回复客户端。这个过程中发生的错误的信息也会回复给客户端。在方式错误的情况下,操作在Primary和其它任意的副本的子集上面操作成功。这样会导致一些不一致的状态。客户端可能通过重试的方式处理一些错误。
由于在GFS中数据流和控制流是分开的,客户端可以先向Chunck Server提交数据,在向Primary发送请求。上面的图有清晰的表示:控制流有客户端到Primary然后到其它的副本,而数据流可以由客户端提交给离它最近的副本,这个副本收到数据后在转发。
Atomic Record Appends & Snapshot
GFS提供原子的追加操作支持,叫做record append。当这个追加操作在一部分的副本上面失败的时候,客户端会重试这个操作,这样导致的一个结果就是在一部分的副本上面可能存在这个记录的重复的数据。GFS是不保证所有的副本都是完全相同的,它只会保证这个数据被做为一个单元被原子地写入至少一次,
It only guarantees that the data is written at least once as an atomic unit. This property follows readily from the simple observation that for the operation to report success, the data must have been written at the same offset on all replicas of some chunk. Furthermore, after this, all replicas are at least as long as the end of record and therefore any future record will be assigned a higher offset or a different chunk even if a different replica later becomes the primary.
GFS还提供快照的支持,使用的方法是类似COW的方法。
Master的操作
GFS的Master负责执行所有的namesapce的操作,以及管理chunk的副本,决定chunk的保存位置,创建新的chunk以及它的副本。处理chunk server的负载均衡的问题。
-
Namespace Management and Locking, 首先虽然GFS也是类似传统文件系统的目录+文件的结构,但是是不支持传统的文件系统的很多操作的,比如它没有一个结构来保存一个目录下面的所有的文件or目录的信息。也不支持hard 后者 symbolic links。其实这里就是这样GFS的目录并不代表来这些文件是以树形的方式组织的。GFS会将完整的路径吗映射为文件的元数据。
为了在操作一个文件时避免受到其它操作的一些影响(比如操作一个文件时它的父目录被删除),比如要操作文件 /d1/d2/…/dn/leaf 时,它要先获取 /d1, /d1/d2, …, /d1/d2/…/dn这些目录的读锁,然后根据类型获取这个文件or目录上的读锁or写锁。为了优化性能这些操作都是lazy的,只有在必要的时候才真正获取。为了避免产生死锁,这里获取锁的顺序根据字典顺序进行。
-
Replica Placement,Chunk副本的位置只要考虑两个目标,一个是最大化可用性和可靠性,一个是最大化工作带宽。GFS会讲这个副本保存在不同的机柜,避免一个机柜的故障对多个副本产生影响,同时读取时可以充分利用网络带宽。缺点及时提高了写的成本。
-
Creation, Re-replication, Rebalancing,当GFS创建一个chunk时,它要考虑这样一些因素:1. 倾向于将chunk放在磁盘利用率更加低的机器上,2. 限制一个chunk server上面的最近创建的chunk的数量,因为新的chunk一般操作比较多,3. 还有就是前面一条,倾向于将副本放在不同的机柜上面。
当发生一些如chunk server不可用的情况时,一些chunk的副本数量就会低于预期的值,这个时候就要重新创建副本,这些重新创建的副本考虑了如下的因素:优先为副本数量更加少的chunk先重新创建,还有就是优先为没有删除的文件重新创建chunk(因为在GFS中一个文件删除之后并不会立即被实际上删除),还有就是优先重新创建哪些可能block用户操作的chunk。 -
Garbage Collection,GFS中一个文件删除之后并不会立即被实际上删除,这个删除的真正的动作在垃圾回收的时候进行。删除立即表现的是一个重命名的工作,重命名之后的名字包含了删除的时间戳,在删除一段时间之后这个文件才会被真正的移除。这种的删除方式存在几点好处,简单的来说就是更加可靠,可以避免误操作,还可以和Master的扫描操作结合批处理提高操作的效率。
-
Stale Replica Detection,当chunk server故障的时候,就可能导致一个chunk的数据是过期的。在GFS中,Master为每一个chunk保存一个chunk version number用来解决这个问题。
容错
容错是GFS中设计中非常核心的一个东西,这个思想贯彻在设计的始终:
we cannot completely trust the machines, nor can we completely trust the disks. Component failures can result in an unavailable system or, worse, corrupted data. We discuss how we meet these challenges and the tools we have built into the system to diagnose problems when they inevitably occur.
高可用
- Fast Recovery,GFS可以做到Master和chunk server的故障在几秒钟内恢复。
- Chunk Replication,这部分的方式在前面一句提过了,基本的方式就是每个chunk默认保存3份,并精心挑选副本保存的位置。在某些副本变得不可用时,Master负责恢复副本的数量。这里论文中还讨论了使用冗余纠错码,这种方式在之后的一些分布式文件系统中被使用了。
- Master Replication,前面说了Master的数据一部分被持久化保存并被复制多份,一部分数据可以从chunk server中恢复。处理这部分,GFS还使用了Shadow Master来提供只读的服务,即使在Master失败之后还是能提供。
Data Integrity,数据完整性
GFS使用校验和来检查数据的完整性,这个工作时每一个chunk server单独完成的。具体来说,一个chunk会被分为64KB大小的block,每一个block都会计算一个32bit的校验和。这些校验和的数据保存在内存里面并持久化到log中,也用户数据时分开的。当chunk server发现数据损坏时,会向有相关操作的客户端返回失败信息,向Master报告情况,Master由其它的副本恢复正确的数据。在空闲的时候,chunserver还会扫描检查数据的完整性。
CFS
GFS的论文一句发表来十多年来,在Google内部也已经由了GFS的继任者,叫做CFS。不过CFS没有相关的论文,能够查到的信息时网上的少量信息。概括一个CFS的(可能的)特点:
- 元数据不在保存到Master的内存里面,而是作为一个table保存到Bigtable里面。使用多级的方式(元数据的元数据的…然后就可以之间保存在Chubby里面了)就完全解决了元数据太多保存不下的问题;
- 使用纠错码减少副本数量;
- 减小chunk的大小,好像只有1MB了,多出来的元数据由前面的方法解决。
参考
- The Google File System,SOSP 2003.
