一个OJ的设计
引言 与 动机
这个是这条咸鱼做的东西。这个部分是OJ系统的核心部分的设计,也就是编译代码,然后运行,对比输出数据,最后返回结果。不包含一般OJ的web的部分。在这里的设计中,web部分和核心的判题的部分是分离的,运行在不同的机器之上。OJ作为一个要运行用户提高的代码的系统,本身就是存在很高的风险的,所以安全的问题是这个OJ要解决的最重要的问题。在这个系统的设计过程中,找出来多种攻击这类OJ系统的方式,其中一些在现在的一些在使用的系统中都存在,严重的可以getshell,控制机器,轻一点的存在泄漏数据的可能(熟读网络安全法,这里的测试均在自己搭建的系统的机器上测试,也不会公开具体的攻击方式)。
现在的一些OJ的另外的一个问题就是拓展性的问题。一般而言,OJ上面一个题的运行时间是1秒到几秒不等,而且会有多组的测试数据,这个时间是不可能优化的,而且是由用户的代码和题本身的特点决定,需要这么多的时间就是必须要这么多的时间。为了支持更大的QPS,只能使用增加机器的方式。现在的一些OJ系统的设计将判题的部分和web的部分耦合在一起,部署在一台机器之上,web部分做高QPS很简单,一般一台机器几百是很简单的事情了,但是在一台机器上面同时判题几百道,这个在目前是不太可能的。所以这种架构很难拓展。
基本设计思路
- 每一个判题的程序运行在一个单独的机器之上;
- 每一个机器之上有多个进行实际判题工作的进程(worker进程),另外还有一个对这些woker进程管理的Master进程;
- 每个Woker进程从消息队列中获取数据;
- Worker进程只将必要的数据保持到数据库,暂时性的数据都发给消息队列or放进有过期时间的缓存中;
- 编译的安全性和运行的安全性一样重要;
- 使用Linux的namespace和seccomp机制等保证安全,rlimit之类的机制限制资源使用;
整体的设计
用户提交的任务交给web端。由web负责进行一些必要的检查(比如检查代码的大小or其它一些数据的合法性),赋予这个任务一个唯一的id(这里叫做rid),这个id对于判题核心来说没有直接的用途,只用做标示作用。然后用合适的序列化方式序列化,将这些数据方式到消息队列里面。Worker进程会尝试从消息队列里面获取任务,这里使用的是“拉”的方式,每个Worker进程根据需要拉取任务,不需要处理负载均衡的问题。整个判题核心部分由C++写成。
单机的设计
在一台机器上,会有一个 Master 进程,有与 CPU 核数相等的 Worker 进程。判题服务的启动时,首先启动的是Master 进程,在做一些必要的设置之后,Master进程会启动多个 Worker 进程。Worker 进程完成具体的工作,而 Master 只负责 Worker 的启动与重启。当 Master 监测到一个 Worker 退出时,会重启一个新的 Worker 代替退出的 Worker。但是,Master 并不会无限重启 Worker,当重启的速率太快时,必然是遇到了严重的 Bug 或者是网络异常,系统已经不能正常工作,此时再重启已经没有意义了,Master 会将所有 Worker 退出之后自己结束运行。
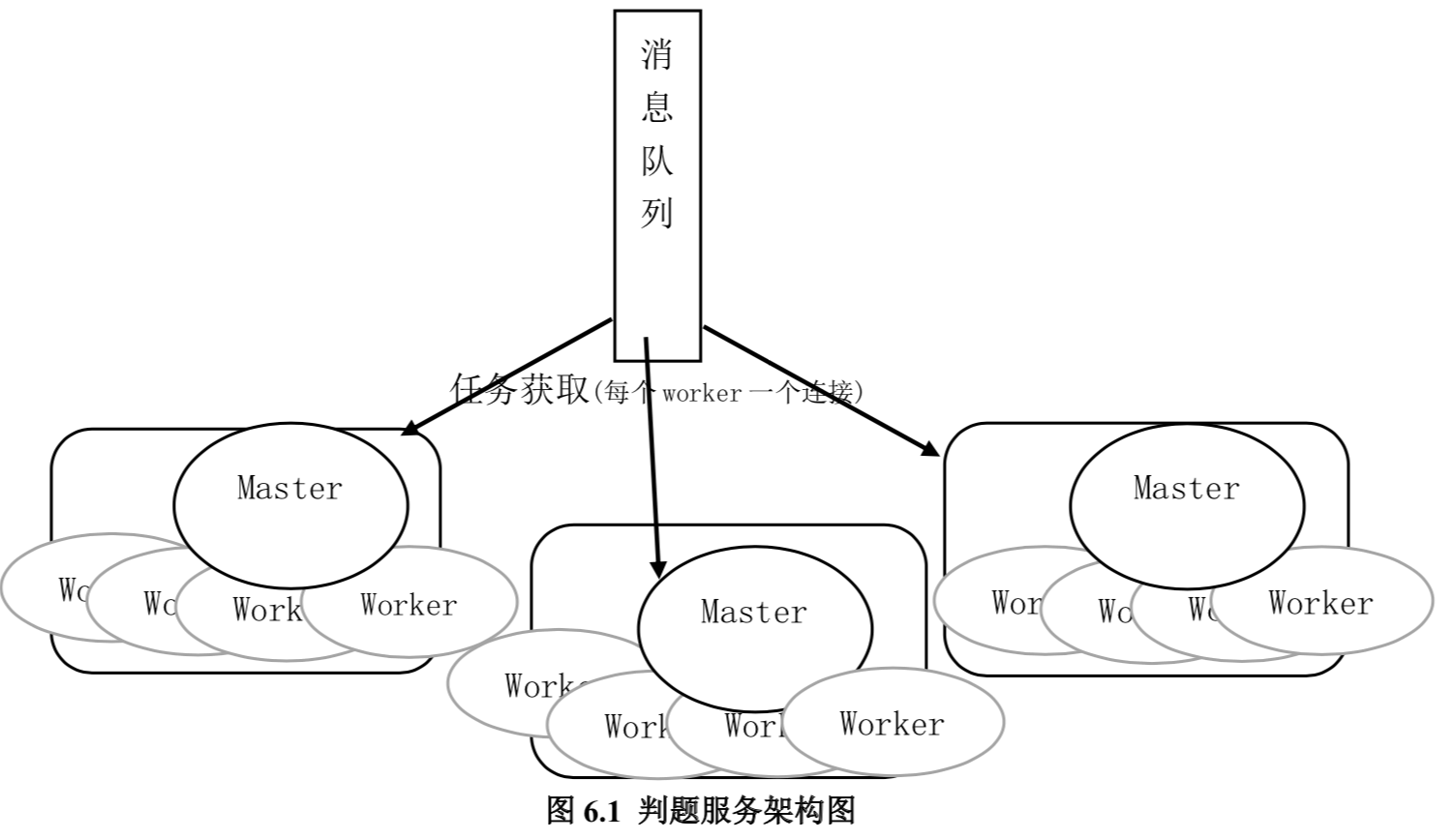
任务获取
任务获取主要解决两个问题:第一,解决判题服务器判题的速率和用户提交的任务 的速率不一致的问题;第二,解决如何将任务公平发送给各个 Worker 的问题。 在这里,用户提交的任务首先被发送到消息队列,由消息队列暂存。当提交任务的 速率大于判题的速率时,消息队列将起到缓冲的作用,任务会堆积在消息队列,在消息 的洪峰过后会将信息逐渐消费,这样保证各部分照常平稳的运行。解决了第一个问题。 解决第二个问题的方式就是消息的获取的方式采用了 Pull 的模式,由 Worker 主动 向消息队列 Pull 消息。获取到一个消息之后,Worker 就去完成这个消息代表的任务。 任务是 Worker 按自己的“需要”获取的。获取的任务耗时长时,Worker 获取的消息速率 就会降低,获取的任务耗时短时,Worker 获取消息的速率就会加快。这样就没有负载均 衡的问题。这样,就解决了第 2 个问题。
将任务的获取抽象成信息获取。消息以一定的格式保存(默认为 JSON)。消息中包 含了关于这个任务的各种信息和数据,如题目的编号,各种资源的限制(内存限制,CPU 时间限制)以及用户提交的代码,这些信息都是后台的系统设置的。Work 获取到信息之后,就进入判题的流程。基本的工作流程如下:
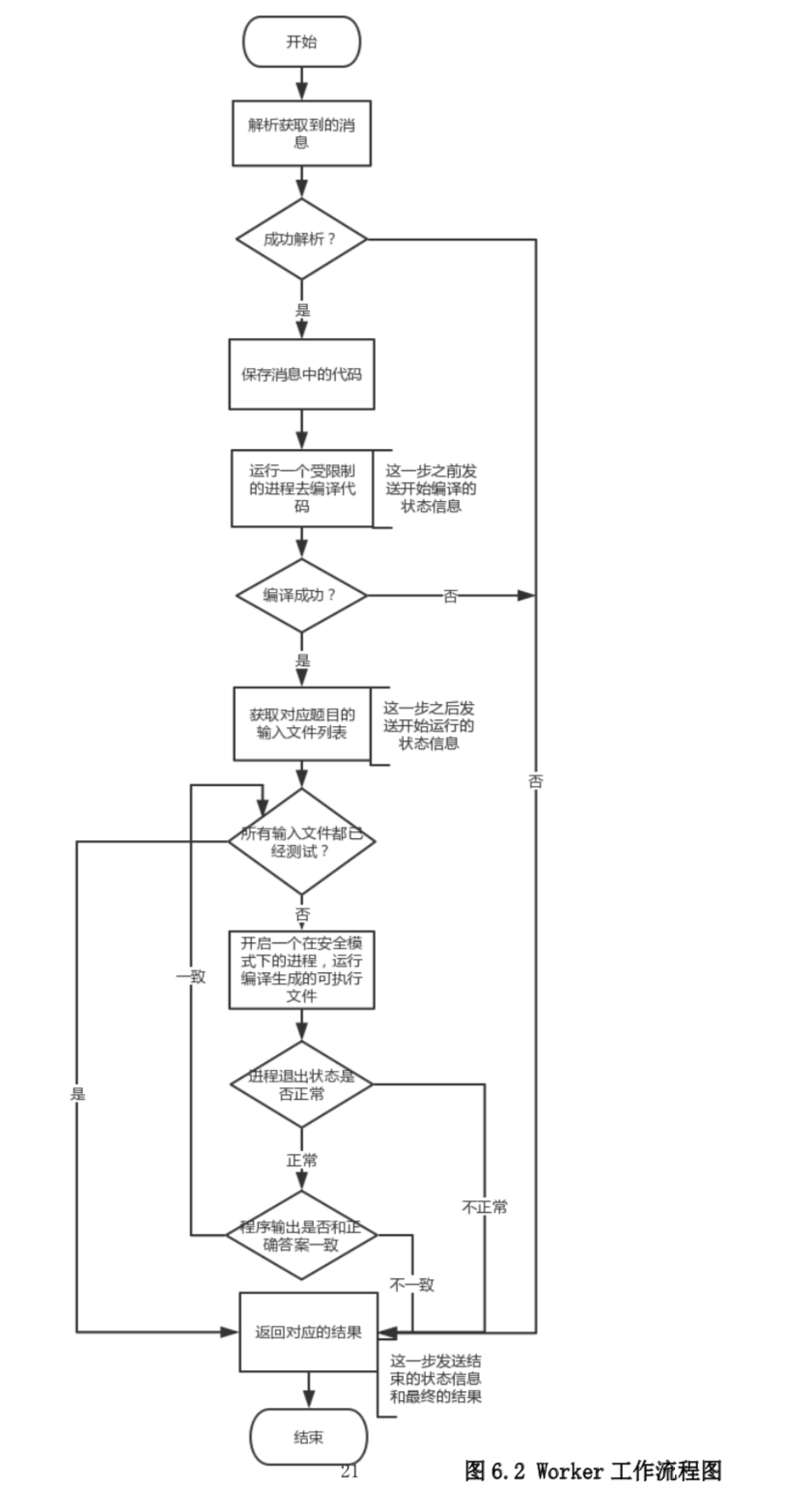
运行结果的判断
结果的判断主要依赖于 wait4 的系统调用。wait4 在 Linux 的定义如下:
pid_t wait4(pid_t pid, int *status, int options, struct rusage *rusage);
当调用返回,表示等待的子进程运行已经结束,我们就可以从 status 和 rusage 中获取运 行的一些信息。 首先是子进程退出的原因,原因可能有以下两个:
- 以exit系统调用的形式退出。从main函数返回实际上也是属于这一张退出行为。 此时,可以获取进程的退出码。
- 由于信号(signal)退出。超时运行、使用过量的内存、使用被禁止使用系统调用、 运行时的段错误或者调用了 abort,进程都会接收到一个特定的信号而导致进程 退出。
这部分的信息可以从 status 参数获取。 其次是运行时间、运行使用内存等的数据,这部分的数据可以直接从 rusage 参数中获取。 正常的情况下,进程一般都以 exit 的形式退出,且退出的状态码是 0。所以这里对进程是否为正常退出判断方式就是: 如果进程不是因为 signal 而退出,而 exit 的退出的状态码又不是 0,那就认为进程为非正常退出。大部分的异常退出都属于这一种。程序退出的 signal 会有以下的情况:
- 由于使用了Linux的rlimit和setitimer机制来限制程序的运行时间,当进程 的退出信号为 SIGALRM SIGVTALRM、SIGXCPU、SIGPROF 或者 SIGKILL进程是由于运行超时被系统结束运行。
- 当signal为SIGXFSZ时,退出的原因就是进程写入了过多的数据到磁盘,导致 进程被系统结束。
- 当 signal 为 SIGSEGV 时,如果获取到的使用内存超过限制,那么结果就是超出内存限制,否则就是重新运行错误
- 当 signal 为 SIGSYS 时,程序退出的原因就是使用了被禁止的系统调用,表明程序使用了非法的操作。
- SIGUSR1,SIGUSR2 为用户定义的信号,接受到这两个是,认为程序为运行错误。
- 接受到其它信号可能是出现了意料之外的情况或者程序自己引发的信号,这里都认为是程序运行异常。
接下来就是对查询输出进行正确性检测。 对输出检测的方法是将程序的输出和正确结果的文件进行差异性对比。系统会对比 一下几种差异:
- 比较忽略空格不同的差异;
- 比较忽略换行不同的差异;
- 比较忽略格和换行不同的差异;
- 严格比较,不忽略任何差异; 如果只有空格、换行或者空格和换行的不同,结果就是对应的格式错误,如果存在其它的不同,那么就是结果错误。
具体的实现是通过 Linux 下的 diff 工具完成的。
任务状态
任务的提交是异步的,任务的执行状态和结果的提交也是异步的。其机制和任务获取的机制相似。状态不会持久化保存。任务的状态分为以下 5 种:
- SubmitFailed,提交失败,在提交的阶段就出差;
- Submited 或者 Queuing,两者为同一个意思,表示任务已经提交;
- Compiling,任务已经进入编译阶段;
- Running,任务已经进入运行阶段;
- Finished,任务已经完成。
一些攻击Online Judge的方式
这里还是不写出来了。不少的OJ系统存在问题。
安全机制
Linux Seccomp
Seccomp(secure computing 的缩写)是 Linux kernel 支持的一种沙箱机制,名字的直接意思就是安全计算,Seccomp 使一个进程进入到一种安全运行模式,该模式下运行的进 程只能调用 4 种最基本的系统调用,即 read(), write(), exit()和 sigreturn(),否则进程便会 被系统以一个 SIGKILL 的信号终止运行。Seccomp-BPF 是 Seccomp 的功能拓展,可以支持动态管理允许使用的系统调用。这 个机制就就是判题服务的安全核心之一。
在判题服务的具体实现中,通过使用系统调用白名单的方式,严格控制运行用户提 交代码的行为来保证服务器安全,由于使用的是白名单的方式,这里阐述一下允许执行 的系统调用,使用不在此之列的系统调用都会导致程序接受到 SIGSYS 的信号,进而导致进程被系统终止:
- 对stdin的读操作,对stdout,stderr的写操作;
- 获取时间的相关调用,有gettimeofday,clock_gettime和time;
- 分配、释放内存的系统调用,有brk、mmap和munmap;
- 设置内存标志的系统调用,有mprotect;
- 获取文件信息的系统调用,有stat,lstat和fstat;
- 其它一些安全又必要的系统调用,有 access, arch_prctl,nanosleep, gettid, uname,exit 和 exit_group;
在 Seccomp 之前,实现类似系统调用白名单使用的方式一般是 ptrace。对比 ptrace,Seccomp 出现的时间更晚,一开始就是为了运行不安全的代码设计,不像 ptrace 是为了调试而设计的。Seccomp 使用上比 ptrace 更加简单,除此之外,使用 ptrace 会导致频繁的上下文切换,降低系统的性能,而 seccomp 不会存在这种问题,seccomp 性能更有优势。
rlimit & itimer
Rlimit即Resource Limit,为Linux或者其它类Unix系统为限制进程资源使用的一 种机制。Resource Limit 可以限制很多方面, 在判题服务中,利用此机制来对运行程序进行 一下几项的限制:
-
限制进程使用的内存;
-
限制最大写入文件数据的大小;
-
限制最大的CPU时间;
-
限制最大的打开文件的数量;
-
限制最大进程数量。对于具体的数据,根据不同的题目,不同的编程语言有不同的限制数据。
对于第 1 点,由于 rlimit 只能限制虚拟内存的大小,并不能限制实际使用内存的大小。一般情况下进程虚拟内存的大小都明显大于实际使用的物理内存,所以在这里设置 了一个内存限制更大的数,默认的数据为内存数据的 3 倍。也因此在最终结果判断的时 候,即使进程不是因为使用过多的内存被结束运行,它也有可能是超出内存限制,需要多做一个判断。对于第 3 点,rlimit 只能限制 CPU 使用的时间,不能限制实际的运行时间,所以 额外增加了及时机制来保证只能让进程运行指定的时间。 Linux 的 setitimer 可以计算实际的时间,在到达计时的时间后,系统会向进程发送信号。由于之前又限制了进程可以使用的系统调用,进程不能取消定时器,到达设定的时候时,进程接受到信号之后会被系统结束运行。
Linux Namespace
在服务中使用 Linux Namespace机制来实现运行进程的隔离。在进程隔离之后,进程会认为自己在一台独立的机器上运行,只能访问有限的文件。Linux Namespace 是 Linux 内核提供的一种系统级别的环境隔离手段,自 namespace在 Linux 2.4.19 开始加入 Linux 内核,到 Linux 3.8 基本完成 namespace 功能,经历了 10余年的时间,使用此机制最有名的应用就便是 Docker。
当没有User Namespace时,在Linux中,mount、chroot、sethostname等操作需要 root权限。当有User Namespace 功能时,普通用户可以创建在新的User Namespace运行的进程,这个进程在新的User Namespace中可以被设置为在这个User Namespace中 有 root 权限,这样就可以进行以前需要 root 权限才能进行的操作,还不会影响到系统的其它部分。每次运行用户提交的代码都会创建一个运行在新的 User Namespace 中的进程,之后设置运行这个进程的 UID 为 0,这样这个进程就拥有了在新 User Namespace 中 root 的权限。 然后,这个进程将 mount 运行用户代码必要的目录,主要为以下几个:bin, lib,lib64,usr(这部分主要是为了支持 Java 和 Python,实际上,运行静态链接的 C/C++,编译好的文件不需要 mount 以上的目录。),然后执行 chroot 操作,这样这个进程就完全被隔离出来,接下来就可以运行(使用 execve)用户的代码了。
编译的安全
编译安全是容易被人忽略的部分,但是实际上编译用户的代码也是一种危险的行为,特别是对于 C/C++而言。关于编译时期攻击的方式,这里还是不说了,防御的方法与运行时期防御的方法一样,使用的是同样的机制。
添加和移除机器
对于添加机器来说是很简答的,只需要将相关题目的(答案)数据拷贝到要加入服务的机器上面的指定的位置,然后启动即可。对于要移除的机器,这里要考虑的就是平滑退出。简单的kill 进程可能导致一些正在运行的任务中断。所以这里是分为2步。1. 想要退出服务的机器发出信号,告诉其要退出服务。进程在收到信息之后,就停止从消息队列里面获取数据。2. 在正在运行的任务都完成之后,这些都自动退出。完成移除工作。
参考
-
Linux man page. getrlimit, setrlimit, prlimit - get/set resource limits. https://linux.die.net/man/2/setrlimit.
- Linux man page. getitimer, setitimer - get or set value of an interval timer. https://linux.die.net/man/2/setitimer.
- Linux man page. diff - compare files line by line. https://linux.die.net/man/1/diff.
- Wikipedia. seccomp, https://en.wikipedia.org/wiki/Seccomp.
- Wikipedia. Linux namespaces, https://en.wikipedia.org/wiki/Linux_namespaces.
