Large-scale Incremental Processing Using Distributed Transactions and Notifications
引言
Percolator时Google开发用来解决Bigtable不支持多行事务的一个系统,号称将Google索引的更新速度提高了100倍,将文档的年龄减少了50%。这篇总结只会包含Percolator如何在Bigtable上面实现跨行跨表的事务的。
By replacing a batch-based indexing system with an indexing system based on incremental processing using Percolator, we process the same number of documents per day, while reducing the average age of documents in Google search results by 50%.
Percolator的设计非常巧妙,硬是在一个只支持单行事务的Bigtable上面实现了跨行跨表事务的支持。
基本架构
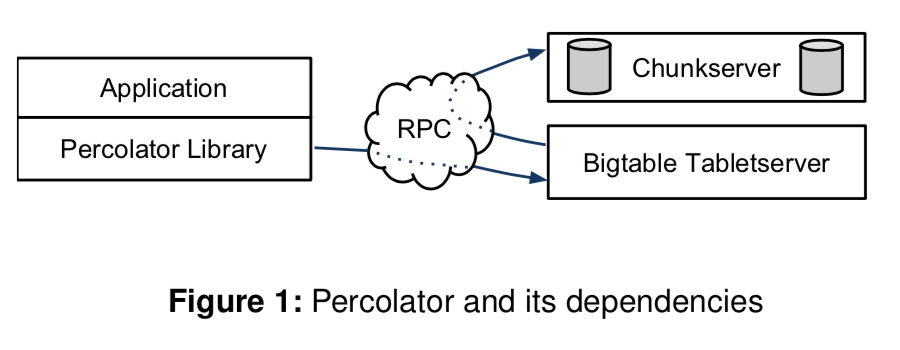
Percolator时为更新索引之类的任务设计的,它的设计原则就是必须能够运行在大规模的系统之上,另外一个就是不要求很低的延时。在Percolator中,一个事务的提交可能被延迟几十秒,这个在OLTP中不可接受的。所以这里要注意Percolator适应的环境。Percolator依赖于Google的其它的常见的基础设施,比如Chubby,Bigtable和GFS,此外,Percolator的提供的是基于时间戳实现的SI级别的隔离,未来整个系统获取单调递增的时间戳,它这里使用了一个时间戳服务,叫做timestamp oracle,
The observers perform transactions by sending read/write RPCs to Bigtable tablet servers, which in turn send read/write RPCs to GFS chunkservers. The system also depends on two small services: the timestamp oracle and the lightweight lock service. The timestamp oracle provides strictly increasing timestamps: a property required for correct operation of the snapshot isolation protocol. Workers use the lightweight lock service to make the search for dirty notifications more efficient.
事务
Percolator提供的是SI的隔离级别。这里Percolator充分利用了Bigtable中时间戳,用来存储数据的多个版本,这个是实现SI的基础。
bool UpdateDocument(Document doc) {
Transaction t(&cluster);
t.Set(doc.url(), "contents", "document", doc.contents());
int hash = Hash(doc.contents());
// dups table maps hash → canonical URL
string canonical;
if (!t.Get(hash, "canonical-url", "dups", &canonical)) {
// No canonical yet; write myself in
t.Set(hash, "canonical-url", "dups", doc.url());
} // else this document already exists, ignore new copy
return t.Commit();
}
上面是Paper中使用Percolator的一小段代码,这里如果Commit()返回的是false就表示事务执行失败了。在给定的一个时间戳,Percolator能提供稳定的一个快照读取。在使用一个时间戳读取了数据之后,一个事务可以以一个玩一些的时间戳来执行写入操作。这个SI隔离很好的解决了写-写之间的冲突,即使时两个事务写入同一个cell(Bigtable中的cell),大部分时候都能保证它们能都提交成功。这里Percolator并不提供serializability级别的隔离级别。下面的表是Percolator使用到的一些字段:
| Column | Use |
|---|---|
| c:lock | An uncommitted transaction is writing this cell; contains the location of primary lock。这里就是这一行的锁,保存的是primary的位置,row + column; |
| c:write | Committed data present; stores the Bigtable timestamp of the data,记录了最近保存数据的时间戳; |
| c:data | Stores the data itself;保存的就是数据本身; |
| c:notify | Hint: observers may need to run,用于标示,具体参考论文[1]的2.4节; |
| c:ack_O | Observer “O” has run ; stores start timestamp of successful last run; |
伪代码+分析
下面的代码是Percolator事务过程的一些伪代码(实际上差不多就是C++的代码)。
class Transaction {
struct Write {
Row row;
Column col;
string value;
};
vector<Write> writes_ ;
int start_ts_ ;
Transaction() : start_ts_ (oracle_.GetTimestamp()) {
}
void Set(Write w) {
writes_.push_back(w);
}
bool Get(Row row, Column c, string* value) {
while (true) {
bigtable::Txn T = bigtable::StartRowTransaction(row); // Check for locks that signal concurrent writes_.
if (T.Read(row, c+"lock", [0, start_ts_])) {
// There is a pending lock; try to clean it and wait
BackoffAndMaybeCleanupLock(row, c);
continue;
}
// Find the latest write below our start timestamp.
latest_write = T.Read(row, c+"write", [0, start_ts_ ]);
if (!latest_write.found())
return false; // no data
int data_ts = latest_write.start_timestamp();
*value = T.Read(row, c+"data", [data_ts, data_ts]);
return true;
}
}
// Prewrite tries to lock cell w, returning false in case of conflict.
bool Prewrite(Write w, Write primary) {
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// Abort on writes_ after our start timestamp ...
if (T.Read(w.row, c+"write", [start_ts_ , ∞]))
return false; // ... or locks at any timestamp.
if (T.Read(w.row, c+"lock", [0, ∞]))
return false;
T.Write(w.row, c+"data", start_ts_ , w.value);
T.Write(w.row, c+"lock", start_ts_ , {primary.row, primary.col});
return T.Commit();
}
bool Commit() {
// The primary’s location.
Write primary = writes_ [0];
vector<Write> secondaries(writes_.begin()+1, writes_.end());
if (!Prewrite(primary, primary))
return false;
for (Write w : secondaries) {
if (!Prewrite(w, primary)) {
return false;
}
}
int commit_ts = oracle_.GetTimestamp();
// Commit primary first.
Write p = primary;
bigtable::Txn T = bigtable::StartRowTransaction(p.row);
if (!T.Read(p.row, p.col+"lock", [start_ts_ , start_ts_ ]))
return false; // aborted while working T.Write(p.row, p.col+"write", commit ts,
T.Write(p.row, p.col+"write", commit_ts, start_ts_ ); // Pointer to data written at start_ts_ .
T.Erase(p.row, p.col+"lock", commit_ts);
if (!T.Commit())
return false; // commit point
// Second phase: write out write records for secondary cells.
for (Write w : secondaries) {
bigtable::Write(w.row, w.col+"write", commit_ts, start_ts_);
bigtable::Erase(w.row, w.col+"lock", commit_ts);
}
return true;
}
}; // class Transaction
事务执行Commit的第一个的第一个阶段就是Prewrite,这里的目的就是尝试锁住所有的要写入的cell,这里来看一些Prewrite的操作:
// Prewrite tries to lock cell w, returning false in case of conflict.
bool Prewrite(Write w, Write primary) {
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// Abort on writes_ after our start timestamp ...
if (T.Read(w.row, c+"write", [start_ts_ , ∞]))
return false; // ... or locks at any timestamp.
if (T.Read(w.row, c+"lock", [0, ∞]))
return false;
T.Write(w.row, c+"data", start_ts_ , w.value);
T.Write(w.row, c+"lock", start_ts_ , {primary.row, primary.col});
return T.Commit();
}
bool Commit() {
// The primary’s location.
Write primary = writes_ [0];
vector<Write> secondaries(writes_.begin()+1, writes_.end());
if (!Prewrite(primary, primary))
return false;
for (Write w : secondaries) {
if (!Prewrite(w, primary)) {
return false;
}
}
// .....
}
这里判断冲突的方式是读取这一行中指定的列来判断的,这些列在前面的表格中有说明,这里读取的是c:write和c:lock,前者是判断写-写的冲突,这里的写入操作的时候会设置这个值,就是下面检查通过的时候设置的。后者是一个事务已经提交了事务,但是由于一些原因推迟了锁的是否,这里出现的可能性很小,但是还是会导致返回false。检查通过之后就是写入这些元数据了,这里数据需要注意的是,对于c:lock,它的数据就是primary的位置信息{primary.row, primary.col},这个是后面的操作需要用的信息。主要这里有一个primary的东西,这里primary具体是谁不重要,后面会解释这个primary。
在Prewrite完成之后,之后先从Oracle获取一个时间戳。这里先处理的是primary。这里实际上就是一个写入一个写记录然后释放锁的过程。这里的操作primary的操作是在Bigtable的事务下进行了,保证了这里操作的原子性,在primay的事务提交之后,下面就是将其它的也做系统的操作,但是这里就可以不同Bigtable的事务了。注意这里只要是primary上面的操作成功了,后面的操作是一定可以成功的(不考虑这个时候机器奔溃了),这里后面说明。这要还要注意的一个地方就是在Prewrite阶段加的锁,这里即使没有提交成功,它也没有去清理,这个就是Percolator的lazy清理的方式。
bool Commit() {
// ......
int commit_ts = oracle_.GetTimestamp();
// Commit primary first.
Write p = primary;
bigtable::Txn T = bigtable::StartRowTransaction(p.row);
if (!T.Read(p.row, p.col+"lock", [start_ts_ , start_ts_ ]))
return false; // aborted while working T.Write(p.row, p.col+"write", commit ts,
T.Write(p.row, p.col+"write", commit_ts, start_ts_ ); // Pointer to data written at start_ts_ .
T.Erase(p.row, p.col+"lock", commit_ts);
if (!T.Commit())
return false; // commit point
// Second phase: write out write records for secondary cells.
for (Write w : secondaries) {
bigtable::Write(w.row, w.col+"write", commit_ts, start_ts_);
bigtable::Erase(w.row, w.col+"lock", commit_ts);
}
return true;
}
对于一个Get操作来说,第一步就是检查要读区的行有没有在[0, start_ts_]范围内的锁,如果有,这里要等待or清理这个锁。之后会读取这个时间范围内最新的一个有提交的时间戳,然后使用这个时间戳读取数据。没有数据就返回false。这里的运行过程要考虑到任何时候client都是可能崩溃的,所以前面的写操作加的锁可能由于故障导致了锁没有被清理,这时候就是进行清理操作。但是精确度判断这里一行上存在一个锁时,是有事务在进行写入擦走,还是一个准备写入操作的事务已经崩溃了。这里就使用了前面提到的primary,这个primay具体是谁不重要,在代码中可以看到它选择的就是第一个要写入的对象。
Percolator handles this by designating one cell in every transaction as a synchronizing point for any commit or cleanup operations. This cell’s lock is called the primary lock. Both A and B agree on which lock is primary (the location of the primary is written into the locks at all other cells). Performing either a cleanup or commit operation requires modifying the primary lock; since this modification is performed under a Bigtable row transaction, only one of the cleanup or commit operations will succeed.
这里的提交和清理的操作都是要现在primaty的操作上面达成一致,也就是对primary的lock进行修改,这里依赖的是Bigtable的单行事务。用于行里面的c:lock实际上保存的就是primary的位置信息,所以一个Get操作想要去清理这个锁的时候,它这样通过这里获取到这个锁的位置,在上面提交的代码中,在提交之前也是要先检查这个在start_ts_时刻的锁释放存在,如果这个时候发现不存在了,那么就是被其它的事务清理掉了,操作只能返回false。在前面的Commit()的代码中,在检查lock通过之后,它是会清理这个primary上面的锁的,如果这读的事务发现primary的锁还存在,它就可以将这些锁安全的清楚(这里只是安全地清除,还是存在一定的可能让一个正在准备提交的事务提交失败的)
bool Get(Row row, Column c, string* value) {
while (true) {
bigtable::Txn T = bigtable::StartRowTransaction(row); // Check for locks that signal concurrent writes_.
if (T.Read(row, c+"lock", [0, start_ts_])) {
// There is a pending lock; try to clean it and wait
BackoffAndMaybeCleanupLock(row, c);
continue;
}
// Find the latest write below our start timestamp.
latest_write = T.Read(row, c+"write", [0, start_ts_ ]);
if (!latest_write.found())
return false; // no data
int data_ts = latest_write.start_timestamp();
*value = T.Read(row, c+"data", [data_ts, data_ts]);
return true;
}
}
准备提交的事务在清理了primary上面的锁之后,如果在清理后面的行上面的锁的时候奔溃了,就会擦走遗留了一些锁没有被清理掉。这里读的通判断primary上面的c:lock和c:write,那么写入这个锁的事务必须被提交,否则的话应该是被回滚。为了避免不必要的回滚,这里就要去判断某个事物是否是存活的,这里使用的方法是村Chuuby中保存一个代表一个worker的token,这里还为这个token添加了一个墙上时钟,在这个时钟过期的时候就会清理这个token,所以worker要定期地更新这个墙上时钟。
A transaction that encounters a lock can distinguish between the two cases by inspecting the primary lock: if the primary lock has been replaced by a write record, the transaction which wrote the lock must have committed and the lock must be rolled forward, otherwise it should be rolled back (since we always commit the primary first, we can be sure that it is safe to roll back if the primary is not committed).
例子
这里先以一个转账的例子来大概说明执行的过程:
- 初始状态的时候,Bob有$10,而Joe有$2,这里保存在时间戳5下面。这里可以看到上次的事务是在时间戳5的时候开始,在时间戳6的时候提交的;
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 6: ;5:$10 | 6: ; 5: | 6: data@5; 5: |
| Joe | 6: ;5:$2 | 6: ; 5: | 6: data@5 ; 5: |
2.下面的一步对应代码中的Prewrite步骤,这里Bob作为Primary,将相关数据保存在对应的时间戳下面;
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 7:$3; 6: ;5:$10 | 7: I am primary; 6: ; 5: | 7: ;6: data@5; 5: |
| Joe | 6: ;5:$2 | 6: ; 5: | 6: data@5 ; 5: |
- 这里对Joe的行进行加锁,锁里面的数据就是Bob对应列的位置信息,也在对应的时间戳下面提交数据。
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 7:$3; 6: ;5:$10 | 7: I am primary; 6: ; 5: | 7: ;6: data@5; 5: |
| Joe | 7: $9; 6: ;5:$2 | 7: primary@Bob.bal; 6: ; 5: | 7: ;6: data@5 ; 5: |
- 这里达到了正式commit的阶段,这里在write的字段写入了7,表示数据就保存在时间戳7下面。这里的时候primary的锁已经被释放了;
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 8: ;7:$3; 6: ;5:$10 | 8: ; 7: I am primary; 6: ; 5: | 8; data@7; 7: ;6: data@5; 5: |
| Joe | 7: $9; 6: ;5:$2 | 7: primary@Bob.bal; 6: ; 5: | 7: ;6: data@5 ; 5: |
- 这里就是修改Joe的行,在write列记录新的数据所在的时间戳,如何释放锁。
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
| Bob | 8: ;7:$3; 6: ;5:$10 | 8: ; 7: I am primary; 6: ; 5: | 8; data@7; 7: ;6: data@5; 5: |
| Joe | 8: ;7: $9; 6: ;5:$2 | 8: ;7: ; 6: ; 5: | 8: data@7; 7: ;6: data@5 ; 5: |
时间戳
前面可以看到每一个的事务都会请求Oracle两次。这里使用的一个优化的方法也是在类似时间戳or计数器分配的一个常用的优化的方法:每一都分配一段时间戳,而不是一个,当系统崩溃的时候,恢复就使用上次被分配出去的更大的值,即使上次被分配出去并没有使用完。由于Oracle可以保障给出的时间戳都是单调递增的,Percolator这里可以保证一个Get操作可以返回所有在它获取的时间戳前提交的事务的数据,
Since T-W < T-R, we know that the timestamp oracle gave out TW before or in the same batch as TR ; hence, W requested TW before R received TR . We know that R can’t do reads before receiving its start timestamp TR and that W wrote locks before requesting its commit timestamp TW . Therefore, the above property guarantees that W must have at least written all its locks before R did any reads; R’s Get() will see either the fully-committed write record or the lock, in which case W will block until the lock is released. Either way, W’s write is visible to R’s Get().
通知
这里时Percolator中一个非常有用的一个功能,可以在某些数据改变的时候触发某些擦走。这里也是上面提到的c:notify列的起作用的地方,就是用于加快查找这个修改了的数据。不过这里与Percolator事务实现没有太大的关系。这里就没有总结了。
评估
具体信息可以参考论文[1].
参考
- Large-scale Incremental Processing Using Distributed Transactions and Notifications,
