Anti-Caching: A New Approach to Database Management System Architecture
引言
这篇Paper将的是一个新的数据库架构的设计。在传统的数据中,数据一般是被保存在磁盘上面的,需要处理这些数据的时候,要先将需要的数据读取到内存中去。这里处理的地方就是buffer pool,可以说在传统的数据中buffer pool是一个很核心的组件了。在这里,传统数据库设计用来处理的情况就是数据的大小大与机器内存的。所以在需要的时候需要将一些page移出buffer pool,这样的工作方式就是Cacheing的方式了。数据库最近的一些研究就是将所有的数据都放在内存中,一方面是现在内存的大小以及很大了,价格越来越低,另外一方面就是读到很大的性能提升。但是这样做也有一个问题就是数据库中的数据的使用频率是相差很大的,有得数据会频繁使用,将这些数据放在内存中是一种很好的做法,但是有些数据是很少被使用的,将这些冷的数据放在内存里面是完全没有必要的。还有的一个问题就是将所有的数据放在内存里面带来的后果就是不能处理数据大小超过内存大小的情况。
未来解决内存数据出现的这些问题,这里提出了一个Anti-Caching的新型的数据库架构。顾名思义,Anti-Caching就是反Caching,工作的思路与传统的Caching的思路相反。对于Anti-Caching的数据来说,内存就是数据保存的地方,不过对于那些没有必要保存在内存中的数据,可以将它转移到磁盘上面去。既可以解决冷数据浪费内存的问题,也可以解决存储不了大于内存数据的问题。
We implemented a prototype of our anti-caching proposal in a high-performance, main memory OLTP DBMS and performed a series of experiments across a range of database sizes, workload skews, and read/write mixes. We compared its performance with an open-source, disk-based DBMS optionally fronted by a distributed main memory cache. Our results show that for higher skewed workloads the anti-caching architecture has a performance advantage over either of the other architectures tested of up to 9x for a data size 8x larger than memory.
基本思路
一个基本的对比图:
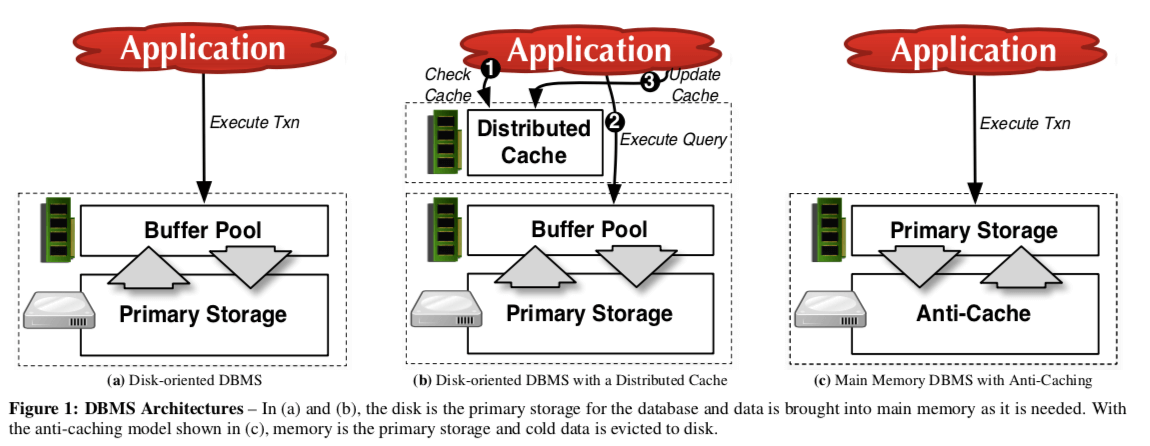
系统运行的时候,数据库会监控系统的内存使用情况,当内存使用达到一定的阈值之后,系统会选择一个”冷“的数据块驱逐到磁盘上面。由于一般的内存数据的数据都不像传统的数据一样时按page组织的。未来支持anti-cacing,这里将要被驱逐出去的数据组织成固定大小的数据块。系统会保存这些被驱逐出去的数据块的信息,在一个事务需要这些数据的时候,数据库会先通过一个“pre-pass” 模式去确定这个事务会访问哪些元组,当这个工作完成的时候,系统先将这个事务abort。然后再将这些在磁盘上面的数据取回来,在重启这些事务。在传统的数据库架构中,在buffer pool中的数据除了暂时还有持久化到磁盘上面的部分数据(这部分数据也在log中),都是既在buffer pool中,又在磁盘上面。而anti-cahing架构数据库的数据同一时间只会在一个地方,不会同时存在磁盘和内存里面。
系统模型
存储架构
系统将管理这些操作的组件叫做anti-cache storage manager ,anti-cache storage manager 主要由三个部分组成:
- 一个磁盘上面的hash table叫做Block Table,保存着被驱逐出去的数据块。每个数据块的大小固定,有一个4bytes的数组标示。每一个块的header保存了来自哪一个table以及被创建的时间等的信息;
- 一个在内存中的Evicted Table,保存着元组到数据块的映射信息,它存在的目的就是需要将数据取回的时候知道去哪一个数据块读取数据;
- 一个内存中的LRU Chain,这个chain的信息被用于确定哪些数据时冷数据。在Paper中的实现中,这个chain被组织为double list,相关的结构被直接保存在元祖的header里面,而不是用分开的数据结构保存。为了减少系统的overhead,不是所有的事务都被记录访问信息,系统只会挑选其中的一部分来组织LRU的信息。
Block Eviction
这里主要的要解决2个问题:
- 从哪一个表里面驱逐数据;
-
从选定的表里面驱逐多少数据;
这里解决第一个问题的方式就是根据表的使用频率。当然这里不让一味的驱逐使用最不频繁表的数据,而是根据比例来驱逐。访问越不频繁的表越可能被驱逐更加多的数据。
对于第二个问题,在决定了从哪一个表驱逐数据之后,运行一个特殊的事务来选择被驱逐的元组,然后将其写入磁盘。这个驱逐事务会阻塞这个分区上面执行的启动的事务。每一个被驱逐的元组被使用 evicted flag标示。
This eviction process continues until the block is full, at which point the transaction will create the next block. The process stops once the transaction has evicted the req- uisite amount of data from each table. Groups of blocks are written out in a single sequential write. For example, if the table is asked to evict a set of n blocks, it will create each of the n blocks independently, and only when all n blocks have been created will it write the result to disk in one sequential write.
Transaction Execution & Block Retrieval
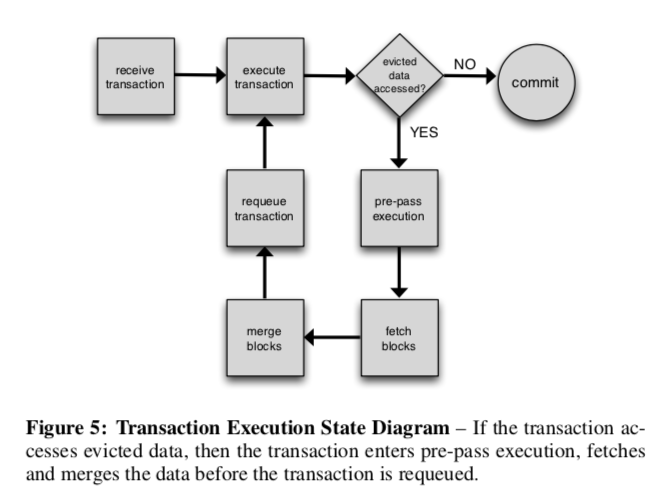
由于Paper里面测试的是内存数据库,如果一个事务要访问被驱逐出去的数据时,如果在事务执行的时候取回数据然后继续执行的话会阻碍到其它的事务执行。所以这里使用了另外的一种方式。
##### Pre-pass Phase
为了让取驱逐数据的时候,后面的事务能够继续进行,这里系统会让事务进入到一个Pre-pass的阶段。在这个阶段,系统将需要的数据取回,然后将这个事务会滚。最好重新将这个事务排入执行队列里面。为了就可能减少这个事务被重新执行的次数,系统会尝试一次就可能地多取回需要访问的被驱逐的数据。有时候也不能一次就确定所有的需要取回的数据,
For some transactions, it is not possible for the DBMS to discover all of the data that it needs in a single pre-pass. This can occur if the non-indexed values of an evicted tuple are needed to retrieve additional tuples in the same transaction. In this case, the initial pre-pass phase will determine all evicted data that is not dependent on currently evicted data.
##### Block Retrieval
这里只关注一个问题:以什么样的方式取回数据?这里有2中方式,一种是取回包含要访问元组的这个块,一种就是只虫块内取回需要访问的元组:
-
Block-Merging,最简单的方式就是将整个块都取回,需要访问的元组被添加到LRU Chain的前面,不需要访问的就放在后面,这样需要的就不太可能马上就又被驱逐出去,而不需要的被驱逐的可能性就比较大,这样处理更加好。这种方式的优点就是简单易处理,缺点就是可能会取回很多无用的数据,而这些无用的数据又可能马上被驱逐出去,这样就造成了不小的overhead;
-
Tuple-Merging,这种方式为了解决前面取回很多无用数据的问题,它只取回需要访问的数据,这样,由于磁盘上面的块还存在需要保存的数据,这样就不能将其简单地删除,这样导致的问题就是在内存和磁盘上存在两个版本的数据,这样就需要将之前的数据标记为无效,只使用现在的在内存中的最新的数据。之后处理磁盘上面的数据块的时候,也要将这个块里面的过期的数据忽略。这样的做法还有另外的一个问题需要处理,就是随着时间的推移,一个磁盘上面的数据块里面存活的数据是越来越少的,这里就需要将这些数据块里面的数据合并,同时更新相关的结构。
We employ a lazy block compaction algorithm during the merge process. This compaction works by tracking the number of holes in each of the blocks in the Block Table. When the DBMS retrieves a block from disk, it checks whether the number of holes in a block is above a threshold. If it is, then the DBMS will merge the entire block back into the memory, just as with the block-merge strategy.
Distributed Transactions & Snapshots & Recovery
-
Distributed Transactions,Paper中使用H-Store数据还支持分布式事务,这里的方式和在单一分区的方法没有很大的区别。另外一个要注意的问题就是H-Store会确保在处理取回数据的时候它要访问的元组不会被驱逐出去,
The transaction is aborted and not requeued until it receives a notification that all of the blocks that it needs have been retrieved from the nodes in the cluster. The system ensures that any in-memory tuples that the transaction also accessed at any partition are not evicted during the time that it takes for each node to retrieve the blocks from disk. -
Snapshots & Recovery,snapshot的处理和一般的数据库没有什么区别,要做的额外的时间就是在antiaching中添加的几个结构也需要做对应的处理就行了。在一个snapshot执行的过程中是不允许驱逐出去的,因为这样可能导致出现错误。未来优化性能,还是用了增量snapshot的方式,
Instead of making copies for each checkpoint, the DBMS takes delta snapshots. Because the data within a block in the Block Table is not updated, the DBMS just checks to see which blocks were added or removed from the Block Table since the last snapshot. This technique greatly reduces the amount of data copied with each snapshot invocation.
评估
这里的详细信息可以参看原论文。
参考
- Anti-Caching: A New Approach to Database Management System Architecture, VLDB’13.
