Ceph: A Scalable, High-Performance Distributed File System
引言
Ceph也是一个很有名的分布式文件系统的设计。Ceph和GFS一样,也采用了元数据和数据分开管理的方法,不过设计上存在不小的差别,
Performance measurements under a variety of workloads show that Ceph has excellent I/O performance and scalable metadata management, supporting more than 250,000 metadata operations per second.
在这里只是很简单地描述了Paper[1]中Ceph一些内容。
基本设计
Ceph主要由3个组件组成,客户端提供类似于POSIX的文件系统接口,一个object storage devices (OSDs)的集群,负责存储所有的数据和元数据,一个metadata server集群,负责管理命名空间,处理安全性、一致性和连贯性等的问题。
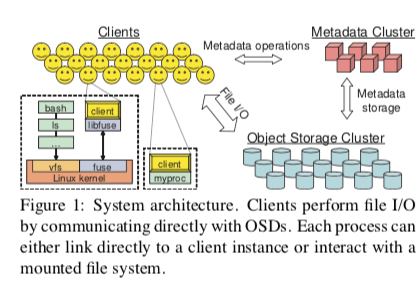
Ceph通过3个设计来实现它的高性能,高可靠性和高可用性:
- 元数据和数据分离。在Ceph中和GFS一样也是元数据和数据分开保存的,元数据由元数据管理集群管理。客户端则可以通过OSDs直接执行文件IO操作。和现在的一些对象的存储系统不同,Ceph消除了块分配列表的设计,而是使用CRUSH算法来实现对象发布,可以通过对象计算来得到对象存储的位置,而不是维护一个发布信息的列表;
- 动态元数据发布管理。元数据的操作在文件系统的操作中占了大约一半的比例,而且会随着时间的变化,数据、负载等的也会随之变化。Ceph的元数据管理会自动适应这些变化,它的管理方式是基于一种Dynamic Subtree Partitioning的方式。
- 可靠的自动发布的对象存储。系统中的机器一般都是逐渐加入的,在这个过程中又的机器会变得不可用。Ceph必须管理这些机器的添加、删除的操作,还要负责对数据进行复制、迁移、错误探测和故障恢复等的工作,
客户端操作
Ceph提供的接口是很类似于POSIX文件系统的接口,在这Paper的描述中,Ceph的接口是一个用户空间的接口(现在可能有拓展)。客户端打开文件的时候,相关的请求会先发送给MSD集群,正确的情况下,MSD会返回给客户端关于这个文件的一些元数据,如inode号、文件大小已经权限的信息等。当时Ceph提供了read, cache reads, write, 和 buffer writes四种的权限,当然现在可能存在变化,比如Paper描述将来可能添加security keys的功能。
前面说了Ceph并没有采取分配列表的设计,而是使用计算的方式来获取文件的对象存在的位置。Ceph使用了一系列的条带化的策略来实现实现文件数据到一个对象序列的映射的关系。对象的名称有文件的inode号和条带好号组成,对象的副本由CRUSH算法(一个全局的映射的函数)将其发布到OSDs中。当有了文件的inode号、布局和文件尺寸的时候,就可以知道保存了文件数据的对象的名字和位置。文件也可能存在一段区间内的数据实际上不存在,Ceph将其称之为空洞。
客户端同步
POSIX文件系统接口的语义要求读取操作反映出前面的写操作的结构,而且写入操作是原子的。由于Ceph是存在read buffer和write buffer,所以当然一个操作混合了读写操作的时候,MDS要求客户端进行IO同步的操作。同步操作显然对性能是很不利的,特别是文件的读写的情况下,而对此Ceph采用了一种放松一致性的语义来提高性能,
Most notably, these include an O_LAZY flag for open that allows applications to explicitly relax the usual coherency requirements for a shared-write file. Performance-conscious applications which manage their own consistency are then allowed to buffer writes or cache reads when I/O would otherwise be performed synchronously.
命名空间操作
文件系统命名空间的管路属于Ceph元数据管理的一部分,它主要就是文件系统的层次关系,有MDS集群管理。在这些文件系统的操作上面,没有采用缓存的方式,都是同步进行的,这个简化了系统的设计且更加安全。此外,Ceph还对一些常见的操作做了优化,比如一个redadir操作后面接着获取每一个文件的元数据,这种情况下,Ceph可以在readdir操作的时候就缓存相关的信息,这样的一个后果就是一致性会有一些减弱。
动态元数据分布
文件的元数据一般都比较小,而且Ceph消除了保存分配列表的设计,进一步减少了元数据的大小。缓存有利于提高MDS的性能,但是元数据的更新必须及时提交到磁盘。另外,Ceph的MDS一个核心的功能就是动态分区,
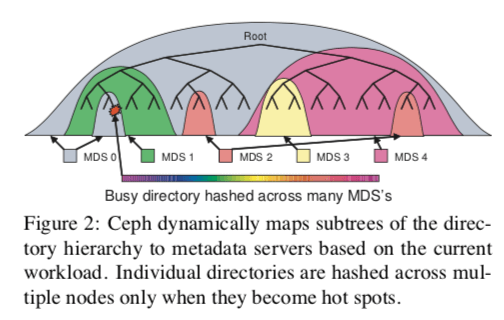
MDS通过动态的分区更好地适应系统的实时的变化。每一个MDS会使用计数器来记录元数据的访问量,从而获取负载的分布情况,而且这个值会根据指数时间衰减。这些计数值就是衡量MDS权重的一个标准。Ceph会定期地比较这些数据,在需要的时候进行迁移的工作。在迁移的时候,
The combination of shared long-term storage and carefully constructed namespace locks allows such migrations to proceed by transferring the appropriate contents of the in-memory cache to the new authority, with mini- mal impact on coherence locks or client capabilities.
另外,元数据在多个MDS中间复制的时候,inode的数据被分为3个部分,它们有着不同的一致性语义的要求,security(owner, mode), file (size, mtime),以及 immutable (inode number, ctime, layout)。不变的数据对一致性没啥要求。动态分区的方式能够处理大部分的负载不均衡的问题,但是在处理热点的时候也存在一些不足,Ceph的处理方式是元数据分散分布,这样的做法也会带来一些问题,比如失去一定的局部特性,也使得处理起来更加复杂。
分布式对象存储
OSDs是Ceph实际存储数据的地方,基本架构如下图所示:
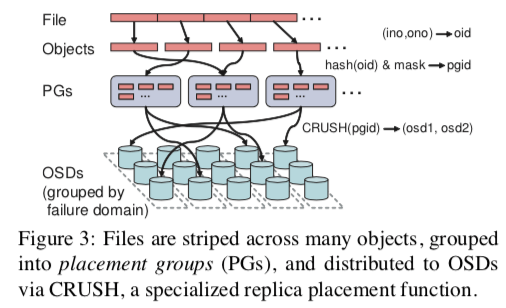
Ceph中数据发布的一个核心的方法就是CRUSH。首先,对象通过一个简单的hash算法来将对象映射到一个 placement groups(PGs),这里会加上一个mask来平衡OSD的使用率,这个mask就直接和OSD的使用率相关。然后,PGs通过CRUSH算法来确定具体将这个对象映射到哪一个OSD上面,
CRUSH (Controlled Replication Under Scalable Hashing), a pseudo-random data distribution function that efficiently maps each PG to an ordered list of OSDs upon which to store object replicas. This differs from conventional approaches (including other object-based file systems) in that data placement does not rely on any block or object list metadata.
使用CRUSH定位一个对象,只需要PG的信息和一个OSD cluster map(描述了OSD存储集群的简单的层次化的描述)。它有两个主要的优点,
first, it is completely distributed such that any party (client, OSD, or MDS) can independently calculate the location of any object; and second, the map is infrequently updated, virtually eliminating any exchange of distribution-related metadata. In doing so, CRUSH si- multaneously solves both the data distribution problem (“where should I store data”) and the data location problem (“where did I store data”).
CRUSH在Ceph中有更多的内容,这里没有信息介绍,另外CRUSH也有一篇专门讲述的论文[2]。Ceph也使用多副本的方式来提高可靠性和可用性。前面的对象映射到的OSDs是一个OSD的结合,Ceph会选择其中的一个作为Primary,另外的Replica。写操作都在Primary进行。读操作也都是通过Primary进行的,这个做法大大简化了一致性等方面的设计。另外,Ceph也是当副本都完成写的时候代表客户端的写操作完成。
在Ceph中,OSD集群是会经常变化的,机器的实效和加入会是常见的事情。为了加速恢复操作,每一个OSD会保存每个对象的一个版本的信息和对于每一个PGs的最近操作的日志。当一个正常工作的PSD接受到一个新的机器的描述图时,它会迭代每一个PGs并利用CRUSH算法来计算自己相对于这个PGs是一个什么样的角色。如果一个PGs所在的OSD结合发生了变化或者是这个OSD刚刚启动,它必须和其它的OSD组成伙伴关系。如果这个OSD作为Primar。则要收集副本的PGs的版本的信息,在必要时进行更新,然后发送新的信息给副本。举一个例子,加入osd1崩溃了,然后被标记为down,osd2成为了这个pgA新的Primary。当osd1恢复过来的时候,它重新被标记为up。当osd2收到信的描述图的时候,它发现它不在时Primary了,这个时候PGs会把最小的版本的信息发送给osd1。osd1会从osd2取回pgA的log,检查数据,然后开始处理新的请求并后台进行恢复操作。
评估
具体的信息可以参看[1]
参考
- Ceph: A Scalable, High-Performance Distributed File System, OSDI’06.
- CRUSH: controlled, scalable, decentralized placement of replicated data, SC’06.
