Spanner: Google’s Globally Distributed Database
引言
Spanner是Google的全球式的分布式数据库。Spanner可以实现在跨越数千个数据中心的数百万台机器上管理万亿级别数据行的能力,可以做到非阻塞的读,lock-free的快照事务。Spanner为了解决Google之前相同存在的一些问题而产生,有着一下几个特点:
- 数据副本可以在很细的粒度上进行动态的控制。应用可以控制哪些数据中心保存哪些数据,控制副本之间的距离以及副本的数量。同时,这些数据还可以在数据中心之间动态透明地移动,以便于平衡数据中心内资源的使用。
- Spanner还实现了分布式数据库很难实现的一些功能,比如它能提供读写的外部一致性,以及在一个时间戳下面的全球一致性的读。还有就是原子的schema变更,即使在有其它操作的情况下也可以。
Google发表的关于Spanner的文章包含了两篇Paper和一篇杂志文章的内容,一般就是OSDI‘12上面的Spanner的最初的论文,还有就是最近在SIGMOD’17上的Spanner的第二篇论文,杂志文章的文章来自ACM Queue,讨论的是关于True Time和CAP相关的内容。总结也是按照这些文章的时间顺序来的。Spanner的第一篇论文的,主要讲的是Spanner的基本架构,一个核心技术基于原子钟和GPS的True Time,以及在此基础上实现的并发控制。
基本架构
从高层次来看Spanner,它就是一个将数据分片保存在跨越多个数据中心的Paxos状态机上面的数据库。
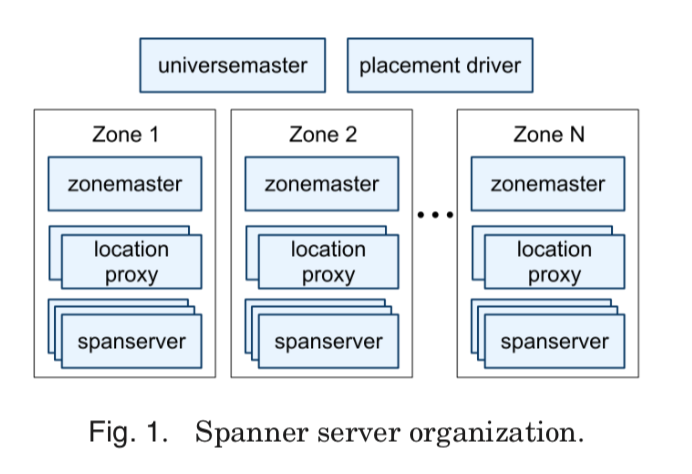
一个Spanner的部署被称为一个universe。一个Spanner有一些zones组成,zone是基本的管理部署单元,一个数据中心内可以有多个zone,zone可以被动态添加以及移除。在一个zone里面会有一个zone master,数百到数千个spanserber。Zone master复杂将数据交给spansever保存,spanserver则为客户端提供数据服务。另外,一个zone有一个 location proxies用来是客户端可以获取数据和spanserver之间的关系。在zone的上层,有一个universemaster,pacement driver,它们都只有一个,前者用来显示系统的一些状态信息以及调试用的,后者则是用来和spanserver周期性地交换,发现需要被移动的数据,满足副本的约束(比如某些副本变得不可用了,就需要生成新的副本),还有就是复杂均衡。
Spanserver的软件栈
Spanserver 里面的大致的架构图:
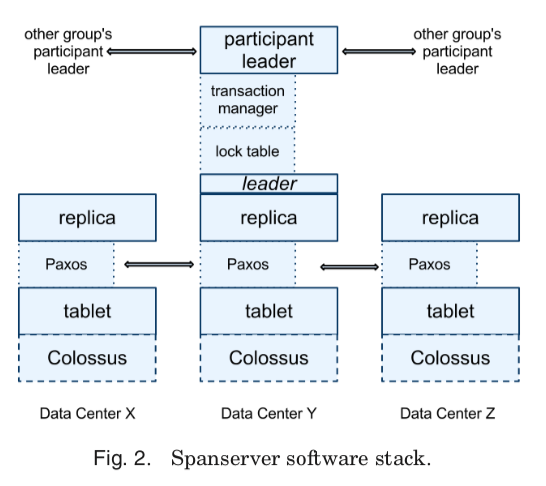
每一个spanserver复杂管理100 – 1000 个tablet的实例,Spanner中的tablet类似约Bigtable中的tablet。实现的是这样的一个映射关系:
(key:string, timestamp:int64) → string
这里和Bitable不同的是,Spanner的时间戳是赋给数据的,这样Spanner就更像是一个MVCC的数据库,而不是一个Key-Value系统。一个tablet的状态是保存若干的类似Btree组织的文件和WAL的日志中的,所有的数据都保存在Colossus分布式文件系统上(这个Colossus分布式文件系统是GFS的后继产品,没有关于它的详细的信息)。每个spanserver会为每一个tablet实现了一个Paxos状态机用于复制。每一个状态机保存了对应tablet的元数据和日志。目前的实现中,每次写操作都会写2次,一次是写tablet的日志,一次是写Paxos的日志。写操作在这里必须是通过Paxos的leader初始化进行的,而对于读,这样这个副本的数据足够”新”就可以直接读取。这里的副本的集合在Spanner中被叫做Paxos Group。这里Spanner对Paxos做了很多的优化,具体可参看原论文,
Our implementation of Paxos is pipelined, so as to improve Spanner’s throughput in the presence of WAN latencies. By “pipelined,” we mean Lamport’s “multi-decree parliament” , which both amortizes the cost of electing a leader across multiple decrees and allows for concurrent voting on different decrees. It is important to note that although decrees may be approved out of order, the decrees are applied in order (a fact on which we will depend in Section 4).
每一个leader上面,spanserver使用一个lock table来实现并发控制。这个lock table 包含了2阶段锁的状态,它将一个范围的keys映射到锁的状态。除了这个lock table之外,每个spanserver还实现了一个transaction manager,用来管理分布式事务,这个是用来处理跨Paxos Group的事务的,如果是一个Paxos Group内的事务,则可以直接不使用。这个transaction manager用于实现一个participant leader,组内其它的副本就叫做participant slaves。在跨的时候,需要每一个Group里面的这个leader来协调完成两阶段提交,其中的一个会被选为coordinator leader,其它的就是coordinator slaves。 transaction manager的状态信息是保存在它低层的Paxos Group里面的。这里是Spanner中一些基本组件的介绍,一开始开始去可能不知道为什么,还是结合后面的内容就知道每一个部分的作用or为什么这么设计的目的了。
数据模型
Spanner的数据模型和Megastore的数据模型有很大的相似性。Spanner开始的论文中说半关系的模型,可见2012年的时候它还会不能算是一个完全意义上的SQL System。当然之后演变了,所以SIGMOD’17上的论文就是” Spanner: Becoming a SQL System “。Spanner的数据模型是建立在directory-bucketed key-value映射层上面的。Spanner中的table很像关系数据库中的table,但是有些区别,它做了一些拓展。这里是一个简单的的例子,
CREATE TABLE Users {
uid INT64 NOT NULL, email STRING
} PRIMARY KEY (uid), DIRECTORY;
CREATE TABLE Albums {
uid INT64 NOT NULL, aid INT64 NOT NULL,
name STRING
} PRIMARY KEY (uid, aid),
INTERLEAVE IN PARENT Users ON DELETE CASCADE;
这里的directory-bucketed key-value映射指的是Spanner一个最底层Key-Value存储的一个抽象层。Spanner使用了一个叫做directory的抽象,实际上就是一些具有相同前缀的Key的集合。

上面这个图就表示处理这个directory的结果。这样的好处就是将相关的数据放在了一起,这个对性能是至关重要的。
Client applications declare the hierarchies in database schemas via the INTERLEAVE IN declarations. The table at the top of a hierarchy is a directory table. Each row in a directory table with key K, together with all of the rows in descendant tables that start with K in lexicographic order, forms a directory. ON DELETE CASCADE says that deleting a row in the directory table deletes any associated child rows.
...
This interleaving of tables to form directories is significant because it allows clients to describe the locality relationships that exist between multiple tables, which is necessary for good performance in a sharded, distributed database. Without it, Spanner would not know the most important locality relationships.
True Time
True Time是非常有意思的一个创新,文件[1]这一段的核心就2个,总结如下:
-
即使Spanner使用了原子钟,获取到的时间还是有误差的,不过Spanner可以保证这个误差在一定的范围之类。所以
TT.now()返回的不是一个时间点,而是一个时间的区间。所以这里的时间先后的比较要考虑到这个时间的误差,Spanner直接提供了TT.after()和TT.before()两个API。这里能确定一个时间小于or大于另外一个时间是很容易理解的,就是必须在它可能的时间区间之外,Denote the absolute time of an event e by the function tabs(e). In more formal terms, TrueTime guarantees that for an invocation tt = TT.now(), tt.earliest ≤ tabs(enow) ≤ tt.latest, where enow is the invocation event. -
另外一个问题就是如何保证这个时间的误差在一定的范围之类,这里使用了两种方式共同来保证,一个是使用原子钟和GPS这类计时精度非常高的方式。另外一个就是使用多个时间来源和时间校对。具体的做法这里可以参看原论文。通过使用这些方式,True Time可以做到大多数情况下这误差在4ms,不超过7ms。
In our production environment, ε is typically a sawtooth function of time, varying from about 1 to 7 ms over each poll interval. ε is therefore 4 ms most of the time. The daemon’s poll interval is currently 30 seconds, and the current applied drift rate is set at 200 microseconds/second, which together account for the sawtooth bounds from 0 to 6 ms. The remaining 1 ms comes from the communication delay to the time masters. Excursions from this sawtooth are possible in the presence of failures.
TrueTime的API:
| Method | Returns |
|---|---|
| TT.now() | TTinterval: [ earliest, latest] |
| TT.after(t) | true if t has definitely passed |
| TT.before(t) | true if t has definitely not arrive |
并发控制
Spanner支持多种的事务类型,有读写事务,只读事务和快照读,
| Operation | Concurrency Control | Replica Required |
|---|---|---|
| Read-Write Transaction | pessimistic | leader |
| Snapshot Transaction | lock-free | leader for timestamp; any for read |
| Snapshot Read, client-chosen timestamp | lock-free | any, |
| Snapshot Read, client-chosen bound | lock-free | any |
时间戳管理
-
Paxos Leader Leases,Spanner中的Paxos的leader使用了租约的机制来实现长时间的leader地位。Leader的地位当然是会变化的,这里它还可以主动地让出leader的地位,这里Spanner对退位的时间做了限制,如果定义S-max为一个leader可以使用的最大的时间戳,那么在退位之前,必须达到TT.after(S-max)为true。
-
Assigning Timestamps to RW Transactions,Spanner对读写事务使用的是严格的2阶段的锁协议。时间戳的分配在所有需要的锁都获得之后,在任何锁释放之前,这个时间戳代表了事务的提交的时间。Spanner可以保证即使跨越了多个leader,也可以给每个读写事务分配单调的时间戳。这里一个单一的leader是很容易获取单调递增的时间戳的,对于多个的leader,其中的一个leader就只能分配在它租约时间分为内的时间戳。于此同时,这里会及时地更细S-max。Spanner可以保证这样的外部一致性:如果T2在T1提交之后开始运行,那么T2的时间戳一定会比T1的大,抑郁一个事务Ti,定义开始和提交的事件分别为e_{i-start}和e_{i-commit},定义提交的时间戳为Si,那么这里实际上就是满足: \(\\ t_{abs}(e_{1}^{commit}) < t_{abs}(e_{2}^{start}) \Rightarrow s_{1} < s{2}\) 定义一个事务的提交请求达到coordinator leader的事件记为e_i^{server},这个coordinator leader对于这个写入事务会赋予一个不早于TT.now().last的时间戳。这里会等到TT.after(s*i)为真的时候客户端才能看到这里已经提交的数据。
-
Serving Reads at a Timestamp,对于读操作来说,主要就是要判断这个数据的版本是否足够新可以被当前的事务读取,这里使用的就是时间戳的方法,Spanner中的每个副本都会跟踪记录一个被称为安全时间 T-safe的值, 它是一个副本最近更新后最大的时间戳。如果一个读操作的时间戳是T满足 T <= T-safe 时, 就表明这个副本可以被这个读操作读取。 这里的T-safe定义为Paxos状态机的T-safe和TM的T-safe的较小的值,Paxos状态机的T-safe指的就是最大的应用写操作的时间戳。TM的T-safe定义为最小的意见Prepared的TS记为 \(\\ T_{safe} = min({t_{safe}^{Paxos}},t_{safe}^{TM}), t_{safe}^{TM}) = min_i{s_{i,g}^{prepare}}-1.\)
-
Assigning Timestamps to RO Transactions,为一个只读的事务分配一个时间戳分为两个阶段,第一步就是分配一个时间戳S-read,然后就是利用这个时间戳进行读操作。这个时间戳可以简单地分配为S-read = TT.now().latest,这样这里有可能由于T-safe 没有增长到足够大而造成对这个事务的阻塞,这里为了减少这种阻塞,Spanner对分配时间戳做了一些优化,选择尽可能老的老的时间戳。这里还要注意的就是S-read也可能改变S-max。
Paper中还有关于Read-Write Transactions、Snapshot Transactions、Schema-Change Transactions以及一些优化的细节讨论,TODO。
评估
详细信息可以参看论文[1].
参考
- Corbett, J. C., Dean, J., Epstein, M., Fikes, A., Frost, C., Furman, J. J., Ghemawat, S., Gubarev, A., Heiser, C., Hochschild, P., Hsieh, W., Kanthak, S., Kogan, E., Li, H., Lloyd, A., Melnik, S., Mwaura, D., Nagle, D., Quinlan, S., Rao, R., Rolig, L., Saito, Y., Szymaniak, M., Taylor, C., Wang, R., and Woodford, D. 2013. Spanner: Google’s globally distributed database. ACM Trans. Comput. Syst. 31, 3, Article 8 (August 2013), 22 pages. DOI:http://dx.doi.org/10.1145/2491245.
- Spanner: Becoming a SQL System, SIGMOD’17.
