MapReduce: Simplified Data Processing on Large Clusters
引言
这两篇Paper好像之前就看过。另外Mapreduce和Spark产生的影响还是很大的,后续的发展也很多,这里就只看看它们原始的论文里面提到的一些东西吧。Mapreduce在分布式系统中确实是一个里程碑性质的作品s,最后面相关的系统研究产生了非常大的影响。
编程模型
Mapreduce中任务都被抽象位map和reduce两个部分,
map (k1,v1) → list(k2,v2)
reduce (k2,list(v2)) → list(v2)
一个基本的word count的例子,
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
这个例子应该是非常出名了。
实现
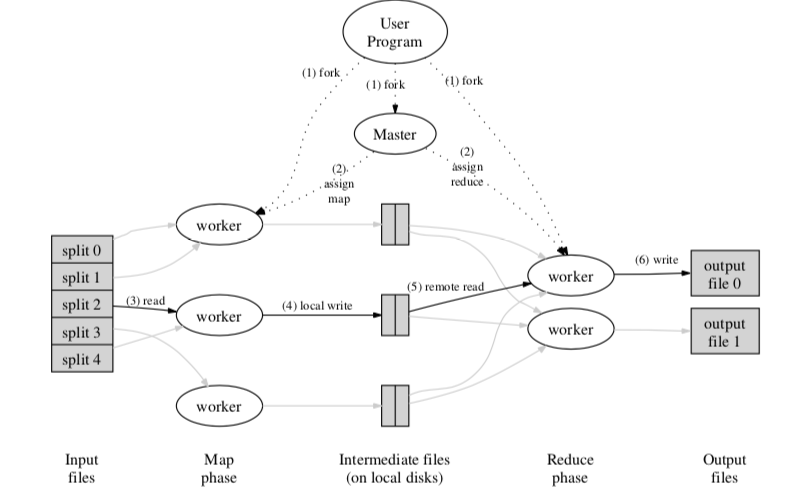
Mapreduce执行的方式大致上表示如下图。在Google实现Mapreduce的时候,一般的服务器还是双核的CPU、2到4GB的内存100Mb到1Gb的网卡,和今天的差别还是很大的。一般的一个Mapreduce系统是有几百or几千台的机器组成的。Mapreduce中几个点,
- 数据交给若干台的机器处理,首先要做的就是将数据分区。Mapreduce会将输入分裂成16M到64M的块。
- 在接下来的Map步骤,一个机器上运行的程序会称为Master,其它的成为Worker。Worker的工作有Master分配。
- Worker在接受到任务之后,去读取对应的数据,在执行用户定义的Map函数,处理数据。处理的数据会先暂时放在内存里,在得到一定的量之后写入到磁盘。写入的时候会根据Reduce的Worker的数量对Map阶段的输出进行分区。Worker也会把这些输出的位置信息报告给Master;
- Master通知Reduce阶段的Worker上一阶段的输入数据的位置信息。然后Reduce的Worker使用RPC从Map阶段的机器上面读取其本地磁盘上面的输出。在读取了所有的数据之后,会对中间数据进行排序;
- Reduce阶段的Worker这些中间数据,指向用户定义的Reduce函数。输入这部分的结果。
-
在所有的Map和Reduce任务都完成之后。执行回到用户程序;在结束之后,输入的结果会分布在多个文件之中(Reduce Worker的数量);
Master主要负责监控Workers的状态、Map阶段输入的位置以及非空闲的Work机器的标识,通知Reduce Worker处理数据。另外容错是Mapreduce设计中重点考虑的一个部分。这里分为Master出错和Worker出错。对于前者,Mapreduce的处理方式是Master会周期性地将Master中的数据结构写入checkpoint,另外启动一个然后从checkpoint恢复。Paper中认为,Master出现失败的可能性必须低,当时的实现方式就是简单终止运行,客户端可以根据自己的需要重试操作。对于Worker的失败,Master在发现Worker一段时间没有响应之后。完成的Map任务必须重新执行,另外Map的执行的输出在Map机器的本地磁盘。而Reduce阶段的失败则不需要,因为它们的输入保存在一个全局的文件系统(应该就是GFS)。
优化 & 改进
Paper中提到的在基本的Mapreduce上的一些改进or优化,
-
支持自定义的分区函数;
-
可以定义Combiner函数,用于部分合并一些中间结果;
-
支持Counter,用来做一些统计信息,
Counter* uppercase; uppercase = GetCounter("uppercase"); map(String name, String contents): for each word w in contents: if (IsCapitalized(w)): uppercase->Increment(); EmitIntermediate(w, "1"); -
支持输入输出的数据类型;
-
Side-effects,支持运行中输出一些额外的数据;
-
支持本地执行方便测试;
-
支持处理的时候跳过一些坏的记录。
性能
Paper中性能的数据感觉在今天已经没有多大的意义了。
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
引言
这篇Paper是Spark最初的论文,只要讨论的是Spark中RDD抽象的一些东西。当然现在Spark的内容远远不止这些。这里只看看论文中写的一些东西,
... We show that Spark is up to 20× faster than Hadoop for iterative applications, speeds up a real-world data analytics report by 40×, and can be used interactively to scan a 1 TB dataset with 5–7s latency. More fundamentally, to illustrate the generality of RDDs, we have implemented the Pregel and HaLoop programming models on top of Spark, including the placement optimizations they employ, as relatively small libraries (200 lines of code each).
RDD抽象
RDD是一个只读的、分区的数据记录集合。RDD只能从从存储的数据中创建和其它的RDD转化而来。RDD一个关键的地方就在与RDD之间的转换(transformations),Spark保护诸多的转换的函数。RDD在任何时候都不需要去实例化,它知道其的派生的关系(lineage),利用这个lineage可以从它的物理存储数据的分区计算出RDD。另外,用户还可以对RDD进行持久化和分区操作。Spark是使用Scala写出的,辨析的代码很精炼,

另外一个🌰,
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split(’\t’)(3))
.collect()
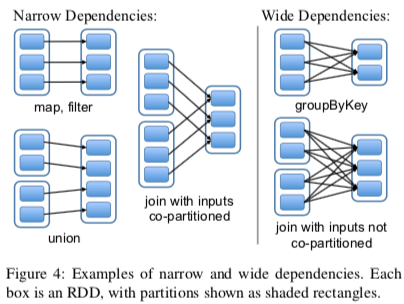
RDD的计算时lazy的,即延迟计算,只有在真的需要计算出结果使用的时候才会实际进行计算操作。操作一般都在内存中进行,如果内存不够,RDD可以写到磁盘上面。在RDD之间的转换上面,存在宽依赖和窄依赖的区别,前者只的是转化而来的RDD依赖与前一步的所有的RDD,而后者指的是只依赖与常数个,与数据规模无关,
编程接口
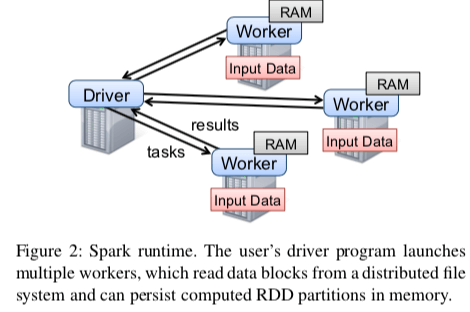
使用Spark的方式时编写driver程序,driver会和多个Worker连接。Driver定义若干的RDD以及在这些RDD上面的操作,Spark的代码包含了这些RDD的lineage。Workers时长时间运行的进程,保存和处理RDD。
与前面的Mapreduce就是Map和Reduce两个操作,Spark中的操作丰富地多,

几个🌰:逻辑回归,
val points = spark.textFile(...)
.map(parsePoint).persist()
var w = // random initial vector
for (i <- 1 to ITERATIONS) {
val gradient = points.map{ p =>
p.x * (1/(1+exp(-p.y*(w dot p.x)))-1)*p.y
}.reduce((a,b) => a+b)
w -= gradient
}
PageRank
val links = spark.textFile(...).map(...).persist()
var ranks = // RDD of (URL, rank) pairs
for (i <- 1 to ITERATIONS) {
// Build an RDD of (targetURL, float) pairs
// with the contributions sent by each page
val contribs = links.join(ranks).flatMap {
(url, (links, rank)) =>
links.map(dest => (dest, rank/links.size))
}
// Sum contributions by URL and get new ranks
ranks = contribs.reduceByKey((x,y) => x+y)
.mapValues(sum => a/N + (1-a)*sum)
}
实现的一些信息
在论文中Spark版本的实现只用了14000多行的Scala代码。系统运行在Mesos机器管理器之上。Paper中关于Spark实现的一些信息讨论了4点,
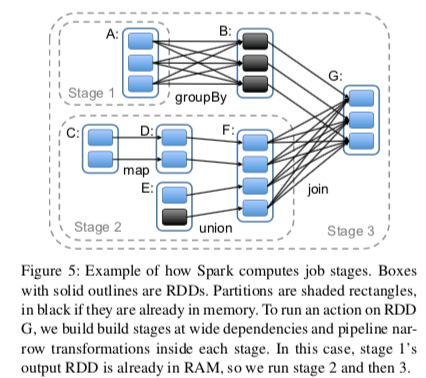
- 任务调度,Spark的任务调度也充分利用了RDD的linage。调度根据RDD的linage构建一个保护多个stage的DAG。调度这里会尝试让一个Stage里面包含更加多的窄依赖关系,使它们流水线化。调度的时候也会考虑到局部性,减少通信开销。另外,对于宽依赖,父分区的节点会将中间结果实例化(物化),简化容错处理,有点类型与Mapreduce中Map阶段的处理方式,
- 交互式一个解释程序,这里就是指安装Spark之后可以在命令行下面使用的一个交互式的工具;
- 内存管理,Spark支持三种的RDD存储方式:以一般的Java对象保存在内存中,系列化保存在内存中以及保存在磁盘中。第一种性能最好,但是由于JVM的一些原因这个比较消耗内存。由于内存有限,Spark也可以将RDD保存磁盘上面去,在这里也使用了常用的LRU的淘汰机制;
- Checkpoint支持,Spark的Linage机制可以容易子在故障之后恢复数据,但是有些时候可能很消耗时间。这里Spark支持检查点的方法,并提供了相应的API。
评估
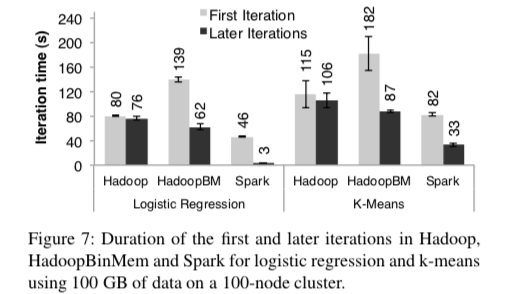
这里的具体信息可以参看[1],
参考
- MapReduce: Simplified Data Processing on Large Clusters, OSDI ’04.
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, NSDI’12.
