Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads
引言
现在的数据系统中常见的两种存储方式就是行存与列存,常见的关系型数据库使用的是行存的方式,一些NoSQL如HBase之类的使用的是列存的方式。一般认为行存的方式更加适用于OLTP的环境,而列存更利于OLAP的方式。在现在的一些数据库系统,提出来HTAP(hybrid transaction- analytical processing)的概念,就是混合来OLTP和OLAP的方式。在这样的系统中。这篇文章是CPU在它的学术型数据库Peloton使用的一种混合的存储方式,FSM(flexible storage model ),
We also present a technique to continuously evolve the database’s physical storage layout by analyzing the queries’ access patterns and choosing the optimal layout for different segments of data within the same table. To evaluate this work, we implemented our architecture in an in-memory DBMS. Our results show that our approach delivers up to 3× higher throughput compared to static storage layouts across different workloads.
基本思路
现在出现了不少的思路将行存和列存的特性结合到一起,比如PAX和RCFile格式(见后面的拓展)。这里的思路则与这些静态的方法不同,这篇Paper提出的方法FSM增能根据系统运行的状态动态的调整行和列的情况。下面的图是和行存列存的一个对比:
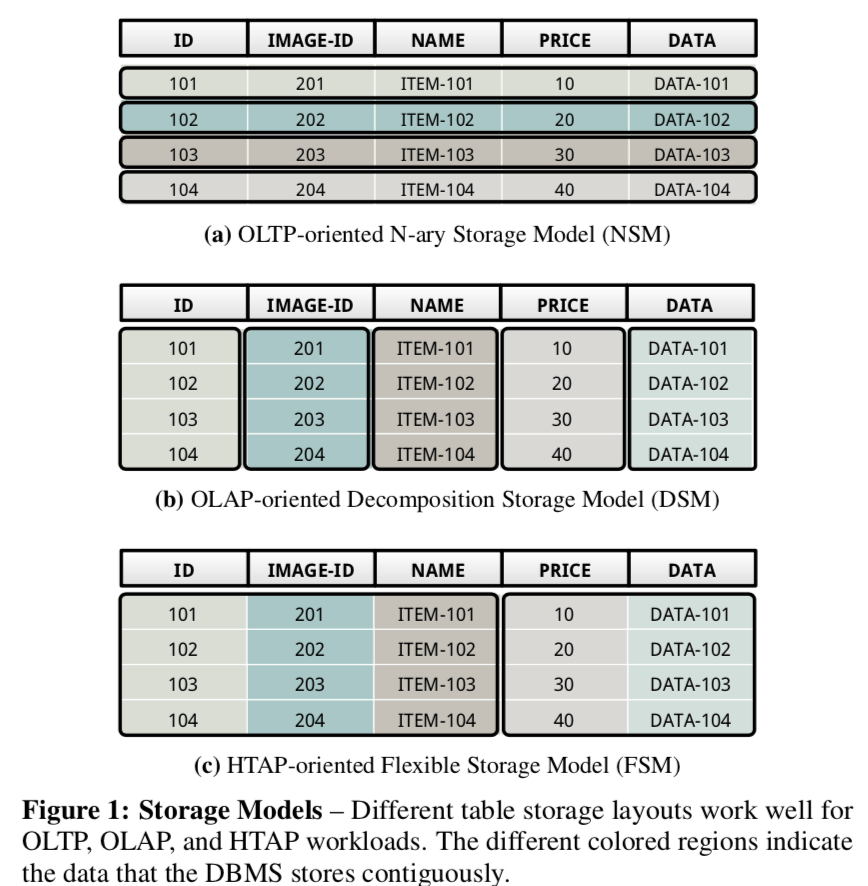
这里就能看出来这里的基本思路就是将其一列分组,在不同的组之间使用行存的方式,在组内使用列存的方式。另外一个特点就是这些组的划分是可以动态调整的,当只划分为一个组的时候,就时行存的方式,当每一个列时一个组的时候,就是列存的方式。而且这里整个table的划分不必要时都是一样的,可以table的不同的不是使用不同的划分方式。在这里FSM将这样的组叫做tiles。这里tiles范围物理上的和逻辑上的。物理上的用于实现具体的列之间的划分,而逻辑上的将这些物理上的实现隐藏起来。
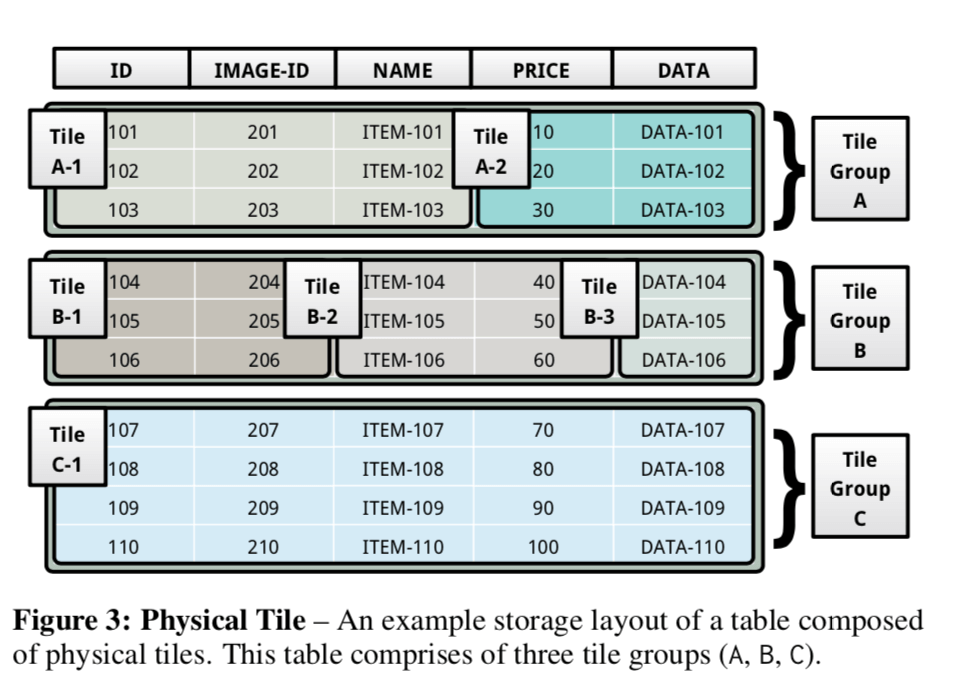
Physical Tile
几个table中的组成一个tile的tuple叫做tile tuple,相当于这些列的一行。一个table中相同的划分方式的这些行的集合叫tile group,整个table就是一些tile groups组成的。下面这个图是一个基本的例子。在这恶搞例子中,table被分为了三个group。在group A中被分为了2个tile,其余的划分各不相同。
Logical Tile
前面的划分方式给了这个table数据的存储方式很大的灵活度,但是也带来了访问比较复杂的问题。这里行之间的存储格式可能是不相同的。为了隐藏这些不同,以便于以一种更加通用的方式访问数据,这里就使用了一个Logical Tile的概念。
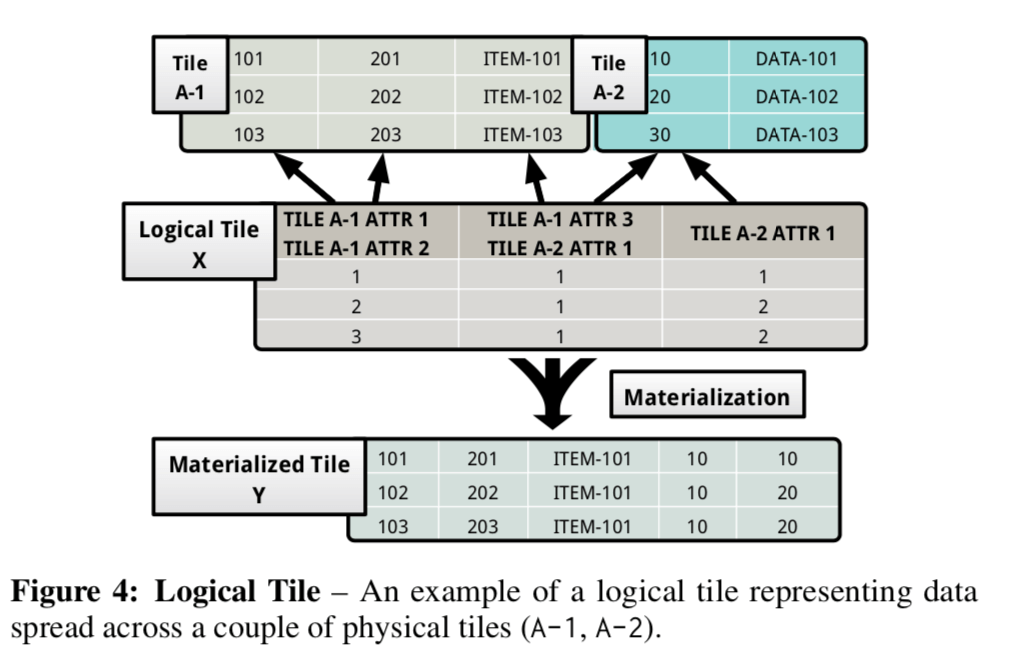
最下面的Materialized Tile Y就表示了访问的时候“看到”的数据布局,这里是使用了Local Tile抽象之后的结构,低层的Tile可能是个种的形式。logical tile可以理解为了一个代表了跨越不同的Physical Tile的值。而且,这个Physical Tile可以来自不同的table,而不仅仅只能是一个,
A logical tile succinctly represents values spread across a collection of physical tiles from one or more tables. The DBMS uses this abstraction to hide the specifics of the layout of the table from its execution engine, without sacrificing the performance benefits of a workload-optimized storage layout.
Logical Tile Algebra
接下来的问题就是如何在这样的存储布局上面实现关系代数的操作了。这里的解释是一下面的图中所示的例子出发的:
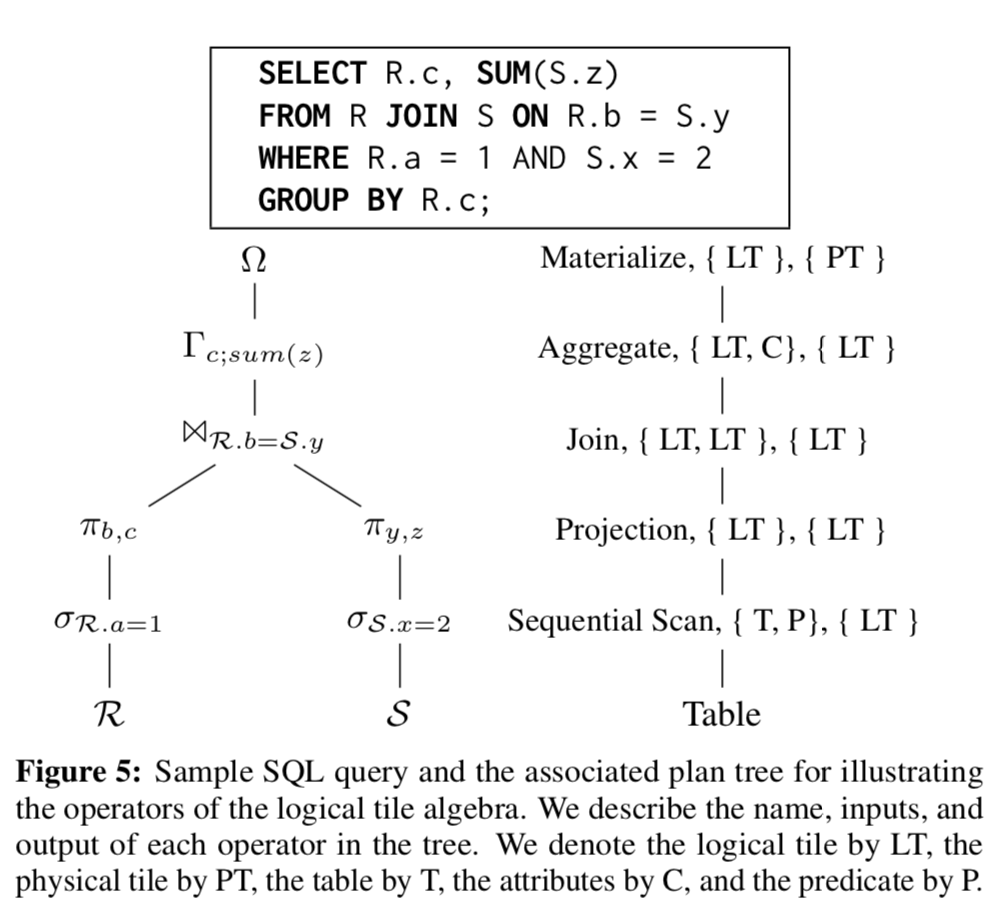
为了在这样的存储布局上面实现有效的查询处理,这里将查询处理实现为 layout transparency,从而减少复杂程度。操作:
-
Bridge Operators,大部分的在logical tile上面的关系代数都是直接使用的logical tile,对下面的physical tile不敏感。这里存在两种情况需要直接感知存储的具体情况,一个就是在上面的查询树的最下面的操作和最上面的操作。这里将这些操作叫做bridge operators(它们需要联系logical tiles和physical tile)。这样的操作包括对表的顺序扫描和根据索引查找。以顺序扫描为例,这个操作会生成为每一个tile group 一个logocal tile,每一个logical tile只会有一行,每一行是一个这个tile tuple在这个group中保存的偏移值,
In Figure 5, the sequential scan (σ) operator associated with R emits logical tiles that represent the tuples that satisfy the predicate a=1. The index scan operator identifies the tuples matching the predicate using the index, and then constructs one or more logical tiles that contain the matching tuples.DBMS可以通过
materialize将logical tile转化为physical tile。在上面的表示查询树的图中,最上面的聚合操作之后,需要将结构发送给客户端,就是使用materialize operator (Ω)获取physical tile。这里不需要重新构造physical tile,直接处理下面的physical tile就可以了。 -
Metadata Operators,Mutators,Pipeline Breakers对理解这个方法关系不是很大,这里的具体信息可以参考论文[1].
并发控制
并发控制之类是接下来要处理的问题。这里讨论的CC方式是MVCC,这也是在现在的数据库系统中最常用的CC协议(没有之一),这里的协议中也包含了这几个常见的概念:
• TxnId: A placeholder for the identifier of the transaction that currently holds a latch on the tuple.
• BeginCTS: The commit timestamp from which the tuple becomes visible.
• EndCTS: The commit timestamp after which the tuple ceases to be visible.
• PreV: Reference to the previous version, if any, of the tuple.
下面的图中表示了这些数据的组织。DBMS将这些数据和physical tile是分开保存的,这样就可以以同时的方式处理不同的physical tile。这里使用了PreV来对之前的版本进行寻址。注意这里不同的版本可以出在不同的physical tile之中,物理布局也可能是不相同的,比如在下面的图中的ID为101的记录。
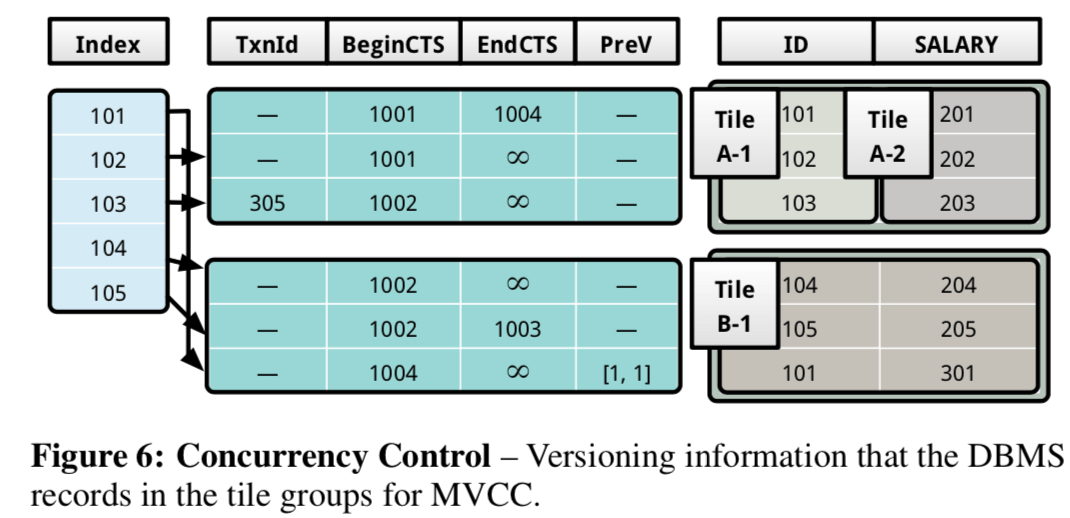
一个事务在iinsert操作的时候,显示请求一个空的slot,同时使用CAS指令原子地将这个slot用自己txn-id标示。开始的时候BeginCTS被设置为无穷大,这样标示这个记录还是没有提交的,对其它的事务不可见,当一个事务提交的时候,会被设置为它的txn-id,此时,如果这个版本的数据是最新的,那么EndCTS就是无穷大,如果已经出现了比这个版本更加新的数据,那么这个EndCTS会被设置为新版本的BeginCTS,事务在提交的时候会重新设置txn-id字段,表示自己的操作已经完成。这里的工作方式和一般的MVCC的方式没有很大的区别。在删除操作的时候,设置txn-id的动作是相同的,这里要设置的字段就是EndCTS,比如105对应的数据,EndCTS为1003,表示这个数据在时间1003之后已经被删除了。这里tile tuple的可见性中,需要处理的就是顺序扫描和索引扫描之类的操作,其它的操作都不需要处理这个问题。在上面的索引中,不直接保存物理指针,而是保存最新一个版本的逻辑位置,避免在动态改变布局的时候需要更新这些数据。
布局重排
这里就是两个问题,1. 决定哪些字段分在一个tile tuple,2. 如果在运行的时候改变布局:
-
决定哪些字段分在一个tile tuple,这里使用的是基于监控过去查询历史的方式.算法分为两个部分,如下面的图所示。第一个部分是使用一个
clustering algorithm决定哪些字段应该被放到一个tile tuple。在第二步,使用第一步得到的数据使用基于贪心的算法计算出最终的存储布局,Our approach leverages the query statistics to compute the layout in two stages. As shown in Algorithm 1, it first employs a clustering algorithm to determine which set of attributes should be stored together in the same physical tile. It then uses a greedy algorithm that uses the output of the clustering algorithm to generate a workload-aware tile group storage layout. -
如果在运行的时候改变布局,这里使用了渐进式的办法。每次移动一个数据到新的布局上面,然后使用原子指令相关结构,旧的数据会被DBMS在适当的时候回收,
Any concurrent delete or update operation only modifies the versioning metadata that is stored separate from the physical tiles. The newly constructed tile group refers to the versioning metadata of the older tile group. The storage space consumed by the physical tiles in the older tile group is reclaimed by the DBMS only when they are no longer referenced by any logical tiles. Due to its incremental nature, the overhead of data layout reorganization is amortized over multiple queries.

评估
这部分可以参考论文[1].
拓展
PAX
PAX(Partition Attributes Across)的思路其实很简答,就是将一个Page再划分为更加小的Page。叫做Mini-Page。这里就是将不同的属性放在不同的Mini-Page里,可以理解为这里就是在一个Page里面的数据的重新组织。
RCFile
参考
- Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads, SIGMOD’16.
