Self-Driving Database Management Systems
引言
这篇文章是CMU发表的关于自治数据库的一篇文章,对应的数据就是Peloton,为CMU开发的一个学术型的内存数据库。自治数据库时利用现在的一些人工智能以及相关方法来实现自我管理的数据库,可以让数据库自我实现一起需要DBA才能完成的操作,
With this, the DBMS can support all of the previous tuning techniques without requiring a human to determine the right way and proper time to deploy them. It also enables new optimizations that are important for modern high-performance DBMSs, but which are not possible today because the complexity of managing these systems has surpassed the abilities of human experts.
类似的思想在之前的数据库发展中也出现过,这个是进一步的发展。另外这里是Peloton数据库的几个特点:
- 内存数据库,主要面向的是内存和非易失性内存上面的实现;
- MVCC,并发控制基于MVCC;
- 自适应的一种存储布局,在论文[2]中说明了;
- 提出了一种新颖的面向非易失性内存的Log的方式Write-Behind Logging[3];
- 内存索引结构主要是BwTree;
- 利用LLVM、SQL JIT和SIMD之类的一些方式优化性能;
- orz
基本问题
自治数据库的一个核心就是自治啦。在Paper中,作者提出了自治数据库主要要解决的几个问题:
- 首先的问题是对工作负载的预测,比如是OLTP or OLAP类型的应用负载。这里的一个很明显的一个例子就是对于OLTP类型的数据库,一百采取行存的办法;而对于OLAP类型的数据库,一般采取列存的办法。这个相关的论文是[2],[2]中讨论了如何根据当前负载的特点选在元组的保存办法,结合了行存和列存的特点,可以在这两个之间转换,也可以处于行列存中间的一个位置;
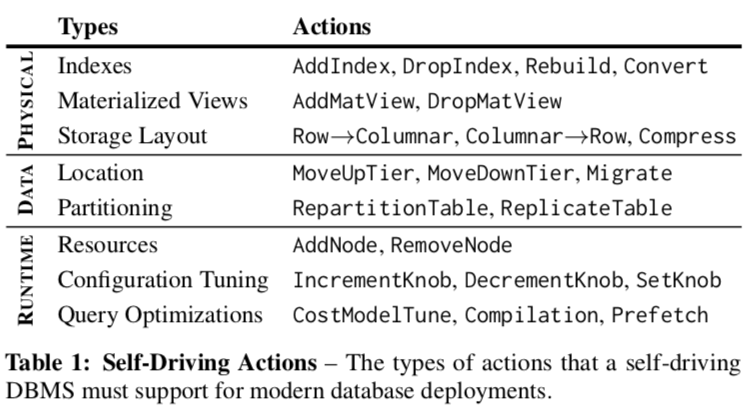
- 另外的一个内容就是预测资源利用的情况。一般情况下,系统都不会一直处于全速运转的情况下,所以资源利用预测的一个主要的内容就是预测应用在什么时候迎来高负载,什么时候系统会处于比较空闲。另外就是根据应用使用这个DBMS的一些特点做对应的优化,下面的图中是一些DBMS可以采取的一些行为:主要包括了 1. 数据库的物理组织,比如索引,存储布局等;2. 数据位置与数据分区等;3. 运行时行为,比如结点管理,自动配置优化,查询优化等;
- 另外,由于自治数据库会根据系统运行的情况不断自我挑战,所以数据库必须要能在不明显增加overhead的情况下应用这些调整;
- 还需要的考虑的是另外的两点限制:1. 必须与现在的一些系统的使用方式相容。也就是自治数据的行为必须都是自我实现的,不需要人工参与。或者是需要修改现在的代码的话,这个是不可以接受的;2. 必须能够使用各种各样的环境;
系统架构
作为一个关系型数据库,关系型数据库需要有的组件peloton也得有。除此之外,未来支持自治,peloton还必须添加额外的组件来支持其自治的操作:
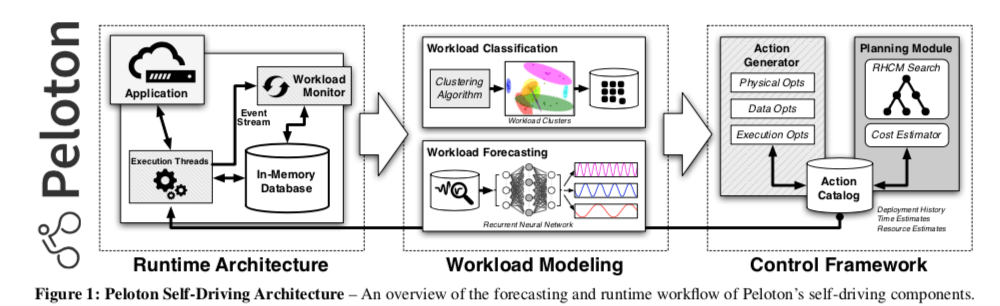
这部分主要包含了三个组件:
-
负载分类;负载分类一个很重要的部分就是对处理的请求进行聚类操作。通过分类的方式讲相似的请求归类到一起统一处理,这样可以大大降低需要处理的模型的数据,不必要每一条SQL语句都作为一个模型。这里使用的算法是DBSCAN算法。接下来的一个问题就是根据什么指标啦进行聚类操作,这里有两种选择:a. 查询操作运行时的指标;b. 查询的逻辑特征。两种方式个有特点,Peloton目前采取的方式是两种方式都使用。系统还会检测预测的情况,如果错误率太高了会重新训练模型,
When this occurs, the DBMS has to re-build its clusters, which could shuffle the groups and require it to re-train all of its forecast models. Peloton uses standard cross validation techniques to determine when the clusters’ error rate goes above a threshold. The DBMS can also exploit how queries are affected by actions to decide when to rebuild the clusters. -
负载预测;这里其实感觉就变成了一个机器学习上面常见的一个预测性质的问题,Paper中主要讨论了两种类型的方法,auto-regressive-moving average model(ARMA)和Recurrent neural networks (RNNs,long short-term memory (LSTM)):
... ARMAs can capture the linear relationships in time-series data, but they often require a human to identify the differencing orders and the numbers of terms in the model. Moreover, the linearity assumption may not be valid for many database workloads because they are affected by exogenous factors. ... The accuracy of a RNN is also dependent on the size of its training set data. But tracking every query executed in the DBMS increases the computational cost of model construction.... -
行为计划和执行引擎;这里的行为计划和执行引擎并不是指传统关系型中SQL的执行。而是指在前面的组件发现了可以使得数据性能更好的方式之后,对数据库的前面提到的可以行使的一些操作的执行的过程,这些操作主要由两个指标决定它的特性: 1. 代价,执行这个“自治”操作需要付出的代价;2. 收益,执行了这个“自治”操作之后可以获取的好处。Peloton会根据这些指标对可以进行的操作进行排序,依次执行。
另外Paper 中提到的一个部分就是与人交互相关的,Peloton需要讲执行的操作以方便人类阅读的形式展现,辅助DBA决策等等:
Lastly, it may be necessary to provide an override mechanism for DBAs. ... To prevent the DBA from making bad decisions that are permanent, the DBMS can require the DBA to provide a expiration for the manual actions. If the action was truly a good idea, then the DBMS will keep it. Otherwise, it is free to remove it and choose a better one
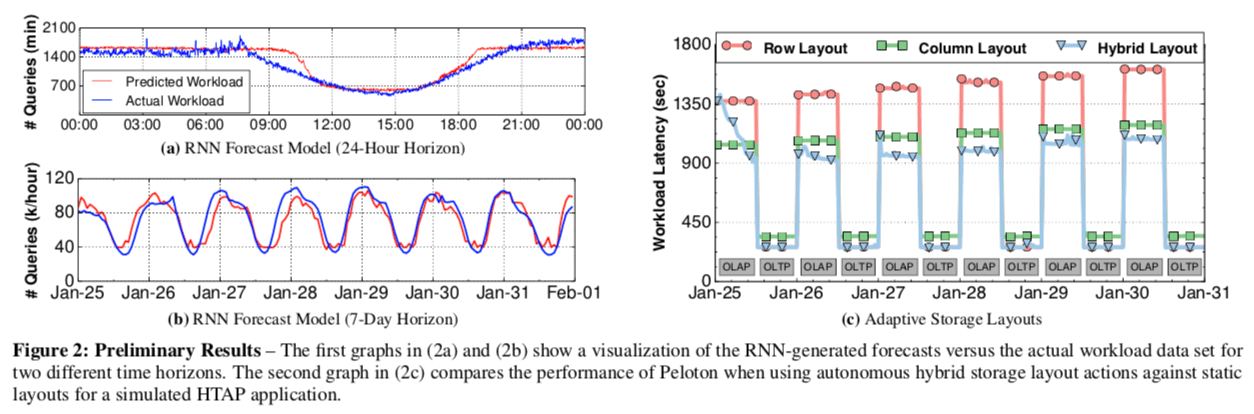
评估
这个具体信息参看[1]
参考
- Self-Driving Database Management Systems, CIDR ‘17.
- Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads, SIGMOD’16.
- Write-Behind Logging, VLDB 2016.
