Let’s Talk About Storage & Recovery Methods for Non-Volatile Memory Database Systems
引言
这篇Paper主要讨论了数据库的不同类型的存储和恢复方式在NVM上的表现。NVM有着不同于DRAM和SSD的性能特点,自然不同的方式在NVM也有着不同的性能体现。Paper主要讨论了常见的就地更新,Copy-on-Write和 Log-structured Updates在NVM为基础的数据库上的各种的表现。
分类
基本分类:
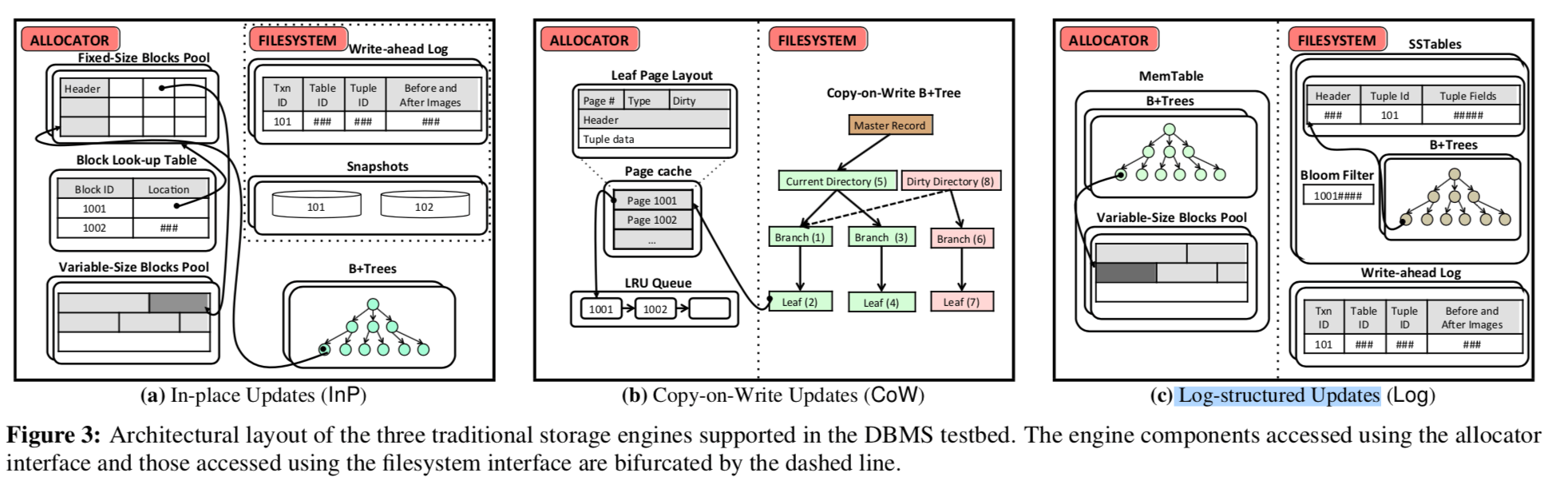
In-Place Updates Engine(InP)
InP是数据库中常见的存储策略,更新数据时就直接在原来的数据上进行。
Storage
在InP engine 中,存储空间被分为一些固定长度的blocks,和一些变长的blocks。这两个不同用于存储不同的数据。每一个block由一组slot组成,tuple被保存在这些slot里面,超过8byte的字段被保存在变长的slot里面,原tuple对应的字段的位置就保存地址信息。
When a transaction inserts a tuple into a table, the engine first checks the table’s pool for an available slot. If the pool is empty, then the engine allocates a new fixed-size block using the allocator interface. The engine also uses the allocator interface to maintain the indexes and stores them in memory.
Recovery
由于在最后一个检查点之前提交的数据时不能保证已经持久化保存了,使用InP使用常见的WAL来解决持久化的问题。最常见的WAL类型就是ARIES。
The InP engine uses a variant of ARIES that is adapted for main memory DBMSs with a byte-addressable storage engine. As we do not store physical changes to indexes in this log, all of the tables’ indexes are rebuilt during recovery because they may have been corrupted.
Copy-on-Write Updates Engine (CoW)
CoW类型的策略时从来步更新原来的数据,只会在原来的基础上创建一个新的数据。CoW引擎使用directories 的方式访问不同版本的数据,常见的例子就是System R上面的影子页。CoW中存在一个Master记录,用于保存目前的directories的信息,基本的组织方式上面的图有很好的说明:
the DBMS maintains two look-up directories at all times: (1) the current directory, and (2) the dirty directory. The current directory points to the most recent versions of the tuples and only contains the effects of committed transactions. The dirty directory points to the versions of tuples being modified by active transactions.
txn提交的时候,DB原子地将指向原来master版本的改为指向新的版本。为了解决拷贝的成本,可以使用 copy-on-write B+trees。
Storage
CoW将directories保存在FS中,可以以一种HDD/SSD优化的给出存储,将所有的字段都内联。这样可以避免昂贵的随机访问操作。每一个数据库(表)都保存在一个单独的文件里面,Master记录总是在文件固定偏移的地方。通过使用映射到主键的方式,CoW支持次级索引。CoW的缺点就是每次会创建新的数据拷贝,即使只是更新了部分数据。此外,垃圾回收也是一个问题。多次拷贝也带了了写操作放大的问题。
Recovery
CoW的方式恢复很简单,如果Master记录在没有改变之前数据库就Crash了,不需要做恢复的处理。
When the DBMS comes back on-line, the master record points to the current directory that is guaranteed to be consistent. The dirty directory is garbage collected asynchronously, since it only contains the changes of uncommitted transactions.
Log-structured Updates Engine (Log)
Log的方式来自log-structured文件系统。Log方式使用LSM-tree。
The design for our Log engine is based on Google’s LevelDB, which implements the log-structured update policy using LSM trees.
Storage
数据存储使用了LSM tree,这个就不细说了.
The log-structured update approach performs well for write-intensive workloads as it reduces random writes to durable storage. The downside of the Log engine is that it incurs high read amplification (i.e., the number of reads required to fetch the data is much higher than that actually needed by the application).
Recovery
Log方式恢复的方法就是从WAL重建MemTable。
It first replays the log to ensure that the changes made by committed transactions are present. It then removes any changes performed by uncommitted transactions, thereby bringing the MemTable to a consistent state.
NVM-Aware Engine
上面提到的存储恢复方式都是为了DARM + HHD/SSD的存储层级结构设计的,在NVM上面有应该怎么样优化呢?一个基本的表示图,注意和上面的图的区别:
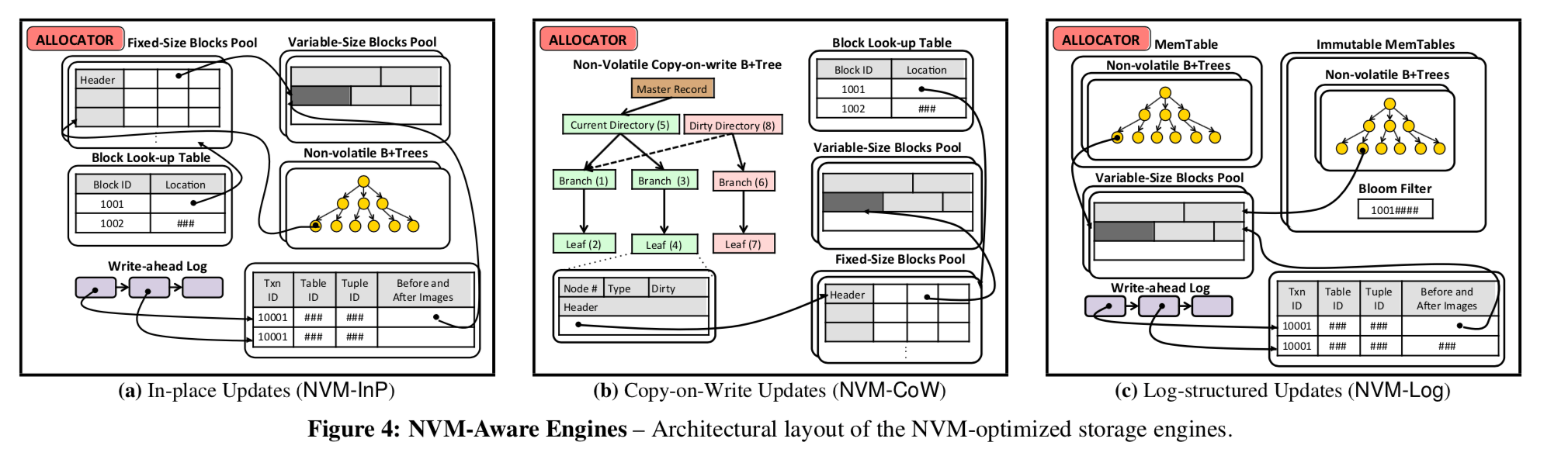
In-Place Updates Engine (NVM-InP)
InP存在的一个问题就是数据重复比较多,比如数据被更新一次就会向WAL中写入一次,然后在向table存储区域中写入一次。当然,在原来的系统中这么设计时必须的。但是在NVM中,因为在NVM中,数据一旦写入到table存储区域中,数据就被持久化了,没有之前系统中不保证持久化的问题。 所以在NVM-InP中,WAL中只会记录指向tuple的指针。
Thus, the engine can use the pointer to access the tuple after the system restarts without needing to re-apply changes in the WAL. It also stores indexes as non-volatile B+trees that can be accessed immediately when the system restarts without rebuilding.
Storage
存储方式和InP的方式基本一样,存储空间被分为一些固定长度的blocks,和一些变长的blocks。这两个不同用于存储不同的数据。每一个block由一组slot组成,tuple被保存在这些slot里面。做出的一些改变就是每一个slot都被加了一个状态标记,用于垃圾回收:
To reclaim the storage space of tuples and non-inlined fields inserted by uncommitted transactions after the system restarts, the NVM-InP engine maintains durability state in each slot’s header. A slot can be in one of three states - unallocated, allocated but not persisted, or persisted. After the system restarts, slots that are allocated but not persisted transition back to unallocated state.
NVM-InP将WAL组成成一个非易失的list,新提交的就直接接到list的尾部。 系统必须在WAL的一项持久化之后才能更改slot的状态。
Recovery
NVM-InP只需要处理没有提交的事务就可以了,不用重放Log。由于没有提交的txn并不能保证数据已经被持久化到NVM上面了,所以NVM-InP需要做undo的处理。方法就是使用WAL里面的消息恢复指向以前数据的指针,此外还要释放相关的NVM空间。对于删除操作,只需要修改索引的指针指向原来的数据即可。
To handle transaction rollbacks and DBMS recovery correctly, the NVM-InP engine releases storage space occupied by tuples or non-inlined fields only after it is certain that they are no longer required.
这里可以看到, NVM-InP revery是没有redo处理过程的。
Copy-on-Write Updates Engine (NVM-CoW)
NVM-CoW的优化点在于:
- 使用一种使用分配器接口的non-volatile copy-on-write B+tree(用一个类似使用内存的方式,之前的方式的 copy-on-write B+tree是保存在文件系统里面的,也就只能利用文件的方式).
- 直接持久化tuple副本,只在dirty directory保留tuple的指针;
- 使用一种轻量化的持久化的机制来持久化 copy-on-write B+tree的更改。
Storage
类型NVM-InP 的方式,存储空间被分为一些固定长度的blocks,和一些变长的blocks。相关的copy-on-write B+tree也保存在NVM中,不在保存到文件系统里面。
We modified the B+tree from LMDB to handle modifications at finer granularity to exploit NVM’s byte addressability. The engine maintains the master record using the allocator interface to support efficient updates. When the system restarts, the engine can safely access the current directory using the master record because that directory is guaranteed to be in a consistent state.
Recovery
不需要处理Recovery,只需要异步地将没有提交的数据回收即可。这个是最有趣的了。
Log-structured Updates Engine (NVM-Log)
同样,类似前面的,在WAL中只保留指向tuple的指针。MemTable也不用在flush在磁盘上面,只需要标记为不可变然后开启一个新的MemTable就可以了。也优化了compaction的策略,一次性可以合并多个。
Storage
这里没有MemTable和SStable的区别,只是不同level和可变不可变的区别。
Like the NVM-InP engine, this new engine also stores the WAL as a non-volatile linked list of entries. When a transaction inserts a tuple, the engine first flushes the tuple to NVM and records the non-volatile tuple pointer in a WAL entry. It then persists the log entry and marks the tuple as persisted.
这里MemTable使用的是non-volatile B+trees。(思考:这里不可变的memtable可以采用一个比B+tree更加省空间和有利于查找的数据结构,反正它是不可变的).
Recovery
只需要处理在MemTable中没有提交事务的数据就可以了,也只会有undo操作。
During recovery, the NVM-Log engine only needs to undo the effects of uncommitted transactions on the MemTable. Its recovery latency is therefore lower than the Log engine as it no longer needs to rebuild the MemTable.
评估
具体的性能数据查看论文[1].
参考
- Let’s Talk About Storage & Recovery Methods for Non-Volatile Memory Database Systems, SIGMOD’15.
