X-Stream: Edge-centric Graph Processing using Streaming Partitions
引言
Xstream是一个以边为中心的单机的图处理系统。同时支持Out-of-Core和In-Memory的处理方式。Xtream有以下的基本的特点:1. 使用scatter-gather的编程模型,将状态值保证到顶点之中;2. 不是以顶点为中心,而是以边为中心;3. 流式地处理无序的表,而不会是去执行随机访问,由于Xstream可能使用的Out-of-Core的方式,这个特性很重要,
We demonstrate that a large number of graph algorithms can be expressed using the edge-centric scatter-gather model. The resulting implementations scale well in terms of number of cores, in terms of number of I/O devices, and across different storage media.
编程模型
scatter-gather是图计算中一种常用的模型,能用来实现各种图算法。以顶点为中心的时候,一般的逻辑如下:
vertex_scatter(vertex v)
send updates over outgoing edges of v
vertex_gather(vertex v)
apply updates from inbound edges of v
while not done
for all vertices v that need to scatter updates
vertex_scatter(v)
for all vertices v that have updates
vertex_gather(v)
每一步的操作分为两个部分,每步都要遍历所有的顶点。在scatter阶段,使用scatter函数来传播信息到邻居结点。在gather阶段,使用gather函数来处理来自邻居结点的更新。而Xstream这里引入了一种以边为中心的scatter-gather模型,基本的处理逻辑如下:
edge_scatter(edge e)
send update over e
update_gather(update u)
apply update u to u.destination
while not done
for all edges e
edge_scatter(e)
for all updates u
update_gather(u)
以边为中心的一个好处就是避免了随机访问边的集合,特别是针对稠密的图,边数远多于顶点书的情况。但是,减少了边的随机范围之后,带来的一个负面的影响就是顶点的随机范围。为了处理这个问题,Xstream使用的是stream分区的方式来缓解这个问题。顶点被划分为适合符合适合缓存大小的分区(对于In-Mmeory来说是CPU Cache,对于Out-of-Core的来说,就是内存了)。同样的,Xstream也将边按照原顶点的方式进行分区,使得边和所属的顶点处在同一个分区之中。每次处理是以一个分区为单位,先读取它的顶点的结合,然后流式的处理边。而不用对边进行排序(与GraphChi的对比)。
Stream是Xstream中一个很核心的概念。Stream在Xstream中被分为输入Stream和输出Stream。Stream就一个主要的接口,就是获取下一个后者是添加一个新的数据。一个Stream会被分区。一个Stream分区主要由一个顶点集合、一个边的列表和一个更新边列表组成。边列表的源点都在这个分区的顶点集合中,而更新边列表的目的结点都在这个顶点分区中。分区的方式是静态的,在分区之后就不会改变。但是一个分区内的更新边列表可能会在计算的过程中变化。在加入了分区之后,接本的操作的处理方式如下:
scatter phase:
for each streaming_partition p
read in vertex set of p
for each edge e in edge list of p
edge_scatter(e): append update to Uout
shuffle phase:
for each update u in Uout
let p = partition containing target of u
append u to Uin(p)
destroy Uout
gather phase:
for each streaming_partition p
read in vertex set of p
for each update u in Uin(p)
edge_gather(u)
destroy Uin(p)
这里基本就是两点改变:1. 变成了底层为分区的两层循环;2. 加入了一个Shuffle操作,Shuffle操作就是将更新分法到对于的分区之中。分区的大小也是影响性能的一个重要因素,基本的方法如前面所言,顶点被划分为适合符合适合缓存大小的分区(对于In-Mmeory来说是CPU Cache,对于Out-of-Core的来说,就是内存了)。
Out-of-Core流引擎
这里要处理的一个最大的问题就是Shuffle阶段会导致的随机访问的问题,实现的时候将scatter操作和shuffle操作合并到了一个步骤。Shuffle操作使用了一个内存中的buffer,在buffer满了的时再更新到磁盘上面去。

将数据load到内存之后,在内存中操作的时候为了避免动态分配内存,使用了称为Stream Buffer的结构来保存。如上面的图所示,一个Stream Buffer由一个保存变长的item和一个索引的数组组成。这里使用了两个buffer,一个用来保存Scatter阶段的结果,一个用来保存Im-Memory Shuffle的结果。操作的过程如上面的如所示,大概就是在前面添加了分区的基本算法上面添加了buffer的逻辑。
磁盘IO
对于Out-of-Core的情况,处理好磁盘的IO性能的影响就比较大了。Xstream使用的是异步的、diract的IO,避开OS的Page Cache。Xstream的数据预取是它自己完成的,而不是利用OS的相关的特性。此外,Xstream也充分考虑了如何利用RAID实现更高性能的读取和利用好SSD之类新型硬件的特性。
X-Stream’s sequential writes can be a considered a best case for such firmware. In addition, we always truncate files when the streams they contain are destroyed. On most operating systems, truncation automatically translates into a TRIM command sent to the SSD, freeing up blocks and thereby reducing pressure on the SSD garbage collector
分区的数量
对于能最好利用带宽的分区大小为S bytes,对于K个分区。如前面所言,每个分区使用了2个流,加上预取,就是4个,再加上shuffle所使用的就是5个。设N为顶点占用的总空间,M为能够使用的最大的内存空间,则可以得到 \(\\ \frac{N}{K} +5 \cdot S\cdot K \leq M \\ 在很大的图之中,可以近似地表示为: K = \sqrt{\frac{N}{5S}}\)
For an I/O unit of S=16MB the minimum amount of main memory required for a graph with total vertex data size as large as N = 1TB is therefore only M = 17GB with under K = 120 streaming partitions. This ignores the overhead of the index data which would have come to an addi- tional 5KB in our design.
In-Memory流引擎
In-Memory流引擎主要用来处理小规模的图。它的分区大小的考虑主要是根据CPU Cache的大小。由于CPU Cache的比较小,可以要处理的分区就比较多。In-Memory的引擎要使用3个Stream Buffer,与Out-of-Core的情况相比,它不需要预取的空间。另外几个设计:
-
并行Scatter-Gather,不同的Stream分区市可以并行处理的,这里要考虑的主要是两个问题,一个是并行处理和Cache的相互影响。另外的一个问题就是负载不均衡的问题,Xstream使用的是任务窃取的方法来处理这个问题;
-
并行多阶段的Shuffle,In-Memory的分区比较多,带来的问题就是不能很好的利用Cache和硬件预取的功能。Xstream使用的解决办法就是一个多级的多阶段的Shuffle,使用分区的ID来维护一个层次结构数,
We then do one shuffle step for each level in this tree. The input consists of a stream buffer with as many chunks as nodes at that level in the tree. Each input chunk is shuffled into F output chunks. Given a target of K partitions, the multi-stage shuffler can therefore shuf- fle the input into K chunks in⌈log_f{K}⌉ steps down the tree.
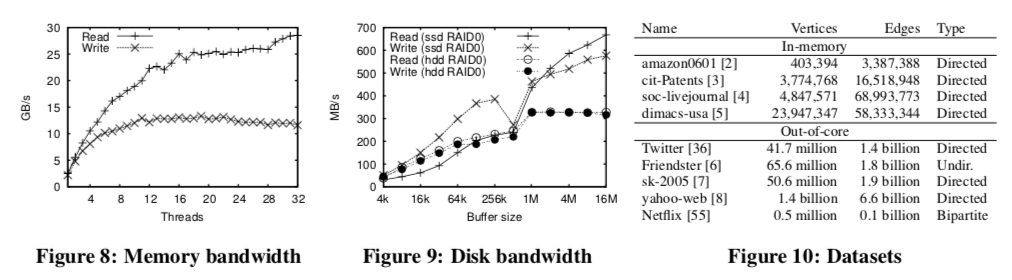
评估
这里的具体信息可以参看[1].
参考
- X-Stream: Edge-centric Graph Processing using Streaming Partitions, SOSP’13.
