Masstree and Plam
引言
这篇总结介绍两中新型的数据结构,本质上来说,这两种数据结构都是B+-tree的变体。Masstree是一种结合了trie和b+tree的一种新型的数据结构,为内存数据库设计,被用在了silo这个内存数据库之中。之后又被其它一些相关的系统使用。Masstree的这篇paper中除了讨论Masstree的结构外,还讨论了一些关于其并发操作的内容。这里如果不是必要的话,会忽略这部分的内容,因为在SOSP‘13 silo的论文中有更加详细的讨论。这里只关注数据结构本身。PLAM则是基于Bulk Synchronous Parallel(BSP)编程模型的一种一种并发B+-tree的一种实现,BSP这种编程模型在一些图计算的系统中很常见,比如Google的Pregel[3]。
Masstree基本结构
Masstree可以看作是一棵trie,每个节点是一棵b+tree树。这样就是一种树套树的数据结构:
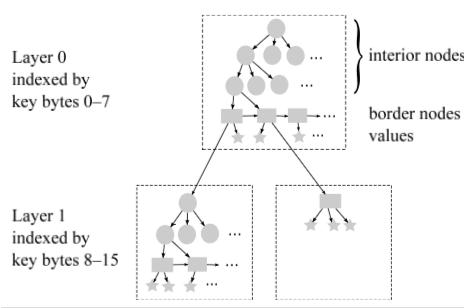
每一层Masstree的key长度是8bytes。至少包含了一个border节点和 0个or多个的interior 节点,前者和b+tree中的leaf节点相似,但不仅仅可以包含key values,还可以包含对下一层的指针。Masstree这样的结构能获得更加好的缓存性能。Key的保持有以下的规则
(1) Keys shorter than 8h + 8 bytes are stored at layer ≤ h.
(2) Any keys stored in the same layer-h tree have the same 8h-byte prefix.
(3) When two keys share a prefix, they are stored at least as deep as the shared prefix. That is, if two keys longer than 8h bytes have the same 8h-byte prefix, then they are stored at layer ≥ h.
基本的节点结构如下:

值得注意的是Masstree范围查询的成本比较高,因为要遍历每一层。
### Masstree的基本操作
Masstree的基本操作没有什么特殊的,就是trie和B+tree树的结合而已。Paper中的查找算法结合了并发处理的部分:

PALM
PALM的基本思路是批量的工作分配给一组的工作线程,给自完成任务达到一个同步点(BSP),通过将线程工作的节点分开来避免使用锁来保护树结构。Plam中有三种基本的操作R、I以及D分布代表查找、添加和删除。

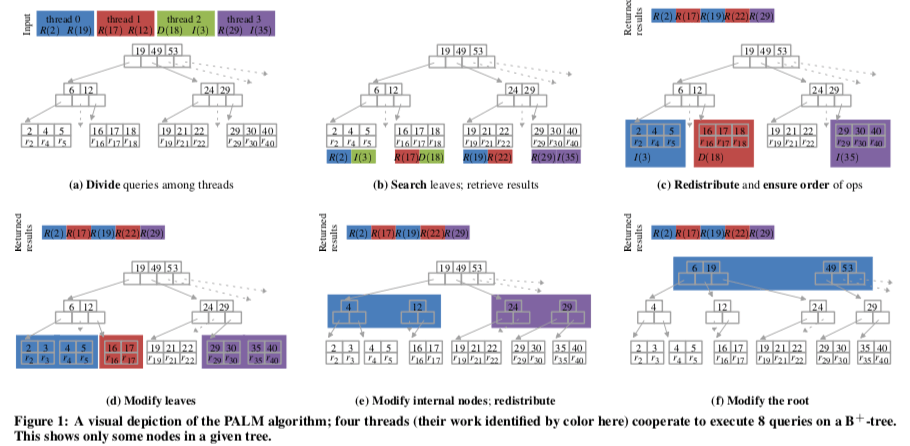
Plam的操作分为4个基本的步骤:1. 将批量的操作划分成几个部分,找到每一个操作的叶子节点;2. 重新分配操作,保证每一个叶子节点只会被一个线程操作;3. 使用同样的方法修改可能需要修改的内部节点;4. 可能需要修改root节点。这四步再可以细分为几个步操作,如下面的图所示,
- 将一个已经排序的操作序列平均分配给n给工作线程,图中使用R、L和D来表示不同的操作,如图a;
- 对于每一个操作查找对应的数据,找到对应的叶子节点,注意这里都是一个查找的过程,不需要锁,如图b;
- 一个BSP模式的同步点,等待到所有的操作都找到对应的叶子节点;
- 上一次的划分可以能操作不同的线程分配的工作要处理同一个叶子节点。这里需要重新分配工作来保证每一个叶子节点只会被一个线程操作。另外还要保证操作的顺序,确保顺序一致性,如图c;
- 对叶子节点进行操作,I和D操作会对节点进行修改,如图d;
- 又一次的BSP模型中一个同步点,等到所有的叶子节点的操作完成;
- 树的内部节点可能需要进行修改,这里可以将新的一层的内部节点看作是一层的叶子节点,和之前的方式一样处理,如图d;
- 根节点也可能需要修改,由于根节点只会有一个,这里就指定一个特定的线程处理即可。B树中根节点需要修改的概率还是很小的。
PLAM的几个优化
PALM中在基本的算法之上还使用不少的优化的措施,
- 前面就提到了批量的操作是排序序的,这样的话一个线程的处理的数据更加可能是“挨在一起”的,局部性更加好;
- 另外的一个优点也是先对操作进行排序带来的。操作排序的话,第一次同步的之后的重新分配工作之需要与一个线程相邻的线程即可;
- 负载均衡,PLAM这种根据操作数量来划分工作的一个好处就是简单方便实现,缺点就是很难处理每一个工作花费的时间不同导致的负载均衡的问题,另外一个就是发布在一个叶子节点上面的操作数量不均。PLAM使用了一些线程合作的方法[2];
- 使用一系列的缓存预取指令来减少查找过程中的Cache Miss导致的延迟;
- 使用SIMD指令来优化,这个是实现上的细节的优化。可以去看看PLAM开源实现的代码
评估
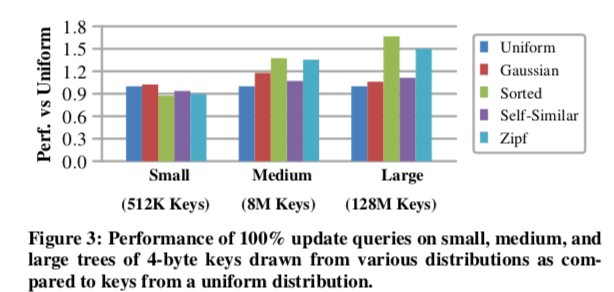
这里的信息可以参看论文[1,2]。在Paper 中,Masstree的速度要比PLAM快上不少。PLAM的一个性能信息:
参考
- Cache Craftiness for Fast Multicore Key-Value Storage, EuroSys’12.
- PALM: Parallel Architecture-Friendly Latch-Free Modifications to B+ Trees on Many-Core Processors, VLDB 2011.
- Pregel: A System for Large-Scale Graph Processing, SIGMOD 2010.
