Fast Databases with Fast Durability and Recovery Through Multicore Parallelism
引言
这篇Paper主要讨论的是Silo内存数据库数据快速持久化和快速恢复的问题。SiloR的基本的思路和RAMCloud数据持久化和恢复是一样[4],都是通过使用堆上大量的磁盘来实现的,
We design throughout for parallelism: during logging, during checkpointing, and during recovery. The result is fast. Given appropriate hardware (three SSDs and a RAID), a 32-core system can recover a 43.2 GB key-value database in 106 seconds, and a > 70 GB TPC-C database in 211 seconds.
写日志
关于Silo的一些基本的信息可以参看[2,3]。SiloR中基本的工作方式是工作线程产生日志记录,工作线程将这些记录交给日志线程,日志线程将这些日志记录批量地写入到磁盘,并使用fsync确保持久化,之后通知工作线程完成工作。这个时候工作线程就可以回复客户端了。在SiloR中,使用的是Value Logging的方式,次方式的缺点是日志的大小会大于Operation Logging,优点是恢复的时候处理的速度快,而Operation Logging日志在恢复的时候就是重新运行一次,会导致恢复的速度比较慢。SiloR在设计的时候要求快速地恢复能力,因而使用了Value Logging的方式。在工作线程和日志线程的对应关系上面,SiloR将工作线程分组,一组对应一个日志线程。在NUMA架构的机器上面,SiloR会让一组的工作线程和日志线程运行在同一个Socket上面,避免读写远程内存带来的性能损失。另外的两个部分,
-
缓冲区管理,系统运行的理想的情况就是Logging不会运行到工作线程处理事务。但是实际的系统中还是要考虑的,日志线程在一些情况下要限制工作线程产生日志数据的量,这里使用的方式就是背压(RxJava中的一些类似的概念)。这里是通过缓冲区管理来实现背压的。日志线程会被每个工作线程分配一定数量的buffers。工作线程向其中添加日志记录,在一个buffer满了的时候or一个新的epoch开始的时候(参考Silo的日志提交的方式),会被flush给日志线程,buffer大小的选择是一个权衡的问题(SiloR中选择的是512KB)。另外,SiloR通过及时写入Logging数据和开辟主管数量的Buffer避免不必要的背压产生。
-
文件管理,Silo中的每一个日志线程会将日志数据写入到最新的日志文件data.log,还会周期性地将这个问题命名为old_data.e,e是这个文件中最近的epoch的值。日志文件中的数据不是严格排序的,但是保证一个文件的后缀e就是这文件里面的最大的e。SiloR另外使用一个pepoch线程来保证小于pepoch都以及持久化,这个epoch的值计算也比较麻烦,Paper中将其分为6步,
1. Each worker w advertises its current epoch,ew,and guarantees that all future transactions it sends to its logger will have epoch ≥ ew. It updates ew by setting ew ← E after flushing its current log buffer to its logger. 2. Each logger l reads log buffers from workers and writes them to log files. 3. Each logger regularly decides to make its writes durable. At that point, it calculates the minimum of the ew for each of its workers and the epoch number of any log buffer it owns that remains to be written. This is the logger’s current epoch, el. The logger then synchronizes all its writes to disk. 4. After this synchronization completes, the logger publishes el. This guarantees that all associated transactions with epoch < el have been durably stored for this logger’s workers. 5. The distinguished logger thread periodically computes a persistence epoch ep as min{el}−1 over all loggers. It writes ep to the pepoch file and then synchronizes that write to disk. 6. Once pepoch is durably stored, the distinguished logger thread publishes ep to a global variable. At that point all transactions with epochs ≤ ep have become durable and workers can release their results to clients.
检查点
和其它的数据库系统中一样,Silo中也使用检查点加快恢复的速度。设置检查点的工作有检查点线程完成,checkpoint manager会分配给每个检查点线程数据库的一部分(即拆分大约为n份,n为磁盘的数量)。每一个检查点会有一个[el , eh ],表示这个检查点的工作从epoch = el开始,在epoch = eh结束。SiloR中检查点的数据写入的时候保证都是已经提交的。另外,还有处理设置检查点的时候并发更新的问题,
However, concurrent transactions continue to execute during the checkpoint period, and they do not coordinate with checkpointers except via per-record locks. If a concurrent transaction commits multiple modifications, there is no guarantee the checkpointers will see them all. SiloR checkpoints are thus inconsistent or “fuzzy”
Silo为了避免使用快照事务来设置一致性检查点,因为这种方式检查点的设置可以花费很长的时间。由于上面描述中的产生的不一致的检查点虽然存在一些缺点,却比一致性的容易处理。一个重要的优化就是检查点线程会跳过epoch >= el的记录,因为记录epoch >= el的记录也是一种不必要的操作,因为从这个点开始的事务会重放日志恢复。关于检查点另外的节点,
- 写入,SiloR中的每一表会被划分为n给部分,每一部分有一个检查点线程处理,每一个线程又将它们的部分分为m个文件,m为恢复的时候使用的核心的数量。这么做是为了加快恢复的速度。另外,checkpoint manager会等到eh <= ep的时候才算完成这个检查点,避免一些数据没有持久化。这里的ep为persistence epoch。
- 对于保护的epoch都小于el的日志文件,在这个检查点完成之后就可以删除了。
恢复
SiloR恢复的机制也是从最近的检查点恢复。Silo通过使用大量的高性能的磁盘来实现快速地恢复。SiloR中的一个表会被checkpo到n块磁盘上面,每一块磁盘上面m个文件,SiloR就使用n*m个线程去恢复,
Processing is straightforward: for each key/value/TID in the file, the key is inserted in the index tree identified by the file name, with the given value and TID. Since the files contain different key ranges, checkpoint recovery threads are able to reconstruct the tree in parallel with little interference;
在所有的线程处理完checkpoint恢复的工作之后,另外还有一部分的日志要处理。这里需要从prepoch文件中获取ep。比这个大的epoch的时候都是没有成功提交的,不用恢复。接下来的操作就是根据前面写入的格式恢复的工程,SiloR这里的设计利用了大量磁盘带来的并发性。
评估
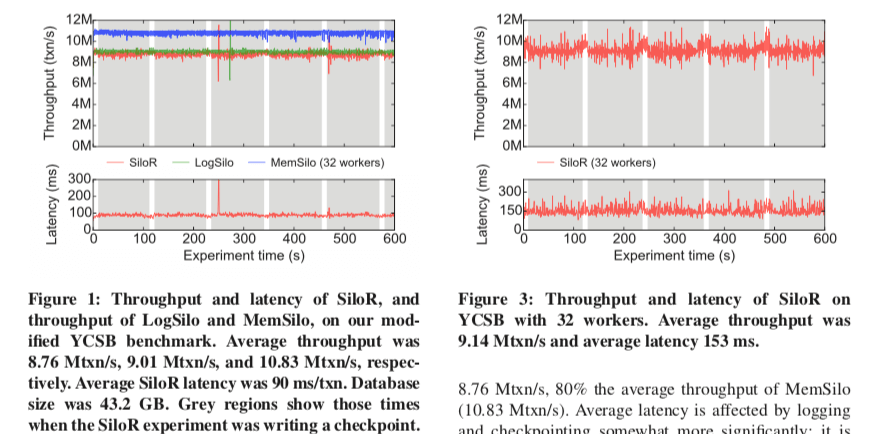
这里的具体可以参看[1].
参考
- Fast Databases with Fast Durability and Recovery Through Multicore Parallelism, OSDI’14.
- Cache Craftiness for Fast Multicore Key-Value Storage, EuroSys’12.
- Speedy Transactions in Multicore In-Memory Databases,SOSP’13.
- Fast Crash Recovery in RAMCloud, SOSP ‘11.
