Write-Behind Logging
引言
继续讲WAL进化的文章。这次的Paper讲的是NVM上面的WAL应该如何设计。利用NVM掉电不丢数据的特点,这篇Paper描述了Write-Behind Logging。Write-Behind Logging,顾名思义就是在操作之后在写Log。
Using this logging method, the DBMS can flush the changes to the database before recording them in the log. By ordering writes to NVM correctly, the DBMS can guarantee that all transactions are durable and atomic. This allows the DBMS to write less data per transaction, thereby improving an NVM device’s lifetime.
基本思路
WAL应该都很熟悉了:
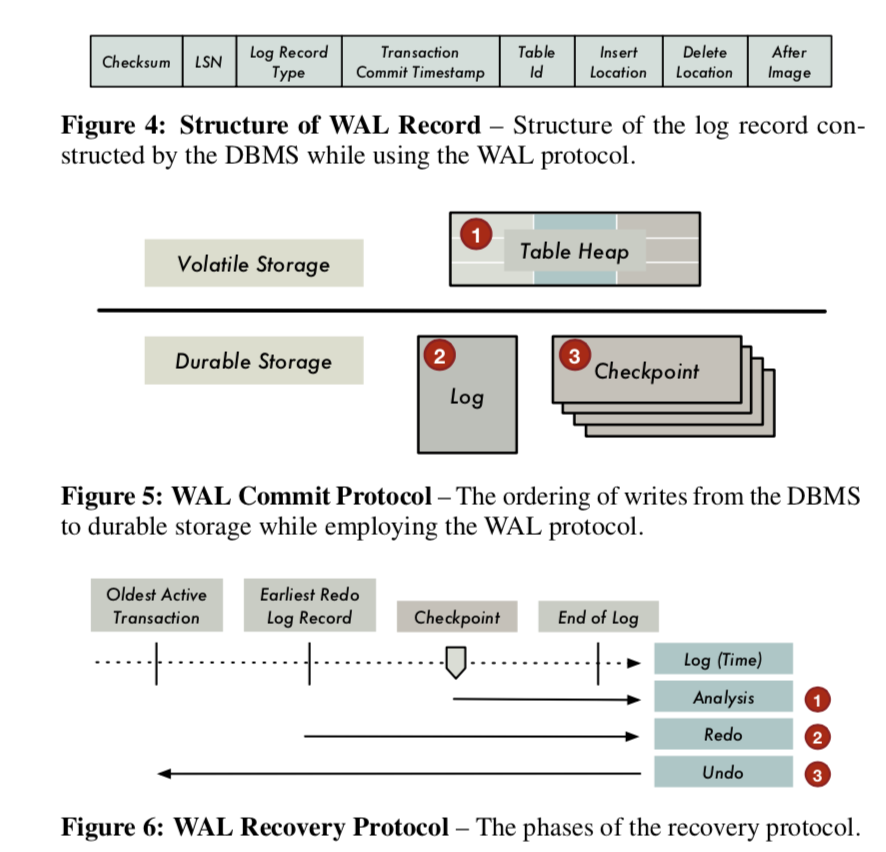
WBL和WAL有着非常大的区别,熟悉它利用的是NVM持久化保存数据和byte-addressable的特点。首先,WBL的日志记录不包含tuple的修改消息,因为事务的修改在事务提交之前已经持久化了。对于修改操作,DB生成一个dirty tuple table (DTT) 中的一条记录来保存修改的消息,这里的消息包含事务id,表修改和一些额外的元数据。对于insert和delete的操作,这个记录只包含了新的or被删除的tuple的位置消息。在MVCC的数据库中,update操作可以看作是delete的操作后面跟着一个insert操作,这些消息记录里面都包含了新的和旧的tuple的位置消息。都是DTT从来不保存inserted or deleteed的tuples本身。
As in the case of WAL, the DBMS uses this information to ensure failure atomicity. But unlike in disk-oriented WAL, the DTT is never written to NVM. The DBMS only maintains the DTT in memory while using WBL.
下面这个表对比了WAL和WBL的区别:

Commit Protocol
NVM的一个特点就是byte-addressable,使用CPU直接寻址里面的数据的时候,这些数据也被CPU缓存了的。但是NVM来说,这个在一些情况下可能就是个问题。因为这里是把NVM当中可持久化保存数据的设备来使用的,数据在缓存行里面没有刷洗到NVM里面的话,就会带来数据一致性的问题。
This is because the DBMS is unable to prevent the CPU from evicting data from its volatile caches to NVM. Consequently, the recovery algorithm must scan the entire database to identify the dirty modifications, which is prohibitively expensive and increases the recovery time.
为了避免这里的问题,在log中,记录了两个额外的时间戳,第一个是时间戳是最后一个事务将它的数据都安全持久化到NVM上面的时间,第二个是一个提交时间戳,在随后的事务组提交之前,这个时间戳由DB保证不会赋予给给其它任何的事务。基本log结构如下:

当DB失败重启之后,它就认为时间戳早于C-p的已经提交,而在C-p和C-d之间的相关操作和数据会被忽略,也就是认为这些都是失败的事务。
In other words, if a tuple’s begin timestamp falls within the (cp , cd) pair, then the DBMS’s transaction manager ensures that it is not visible to any transaction that is executed after recovery.
对于DTT中的每一次的记录修改,DB使用设备的sync原语来保证已经被持久化。然后构造一个包含了C-p和C-d的日志项,用于指示在下一个组提交之前不会提交任何C-d更晚的事务。在提交之前,DB会保证在C-p之前的事务已经持久化。对于那些跨越了一个组提交时间窗口的长时间事务,DB也会在日志中记录它的提交时间,没有这个信息,DB就不能在这个事务提交指针增加C-p(这里可以想到,如何增加了这个C-p的值的话,就可能把一些没有提交的事务当作是已经提交的了,所以要加上一个额外的信息来指明)。在恢复的时候,用这些信息来指明哪些修改是没有被提交的事务操作的。 此外,这里还有跨设备的问题:
With WBL, the DBMS writes out the changes to locations spread across the durable storage device. For example, if a transaction updates tuples stored in two tables, then the DBMS must flush the updates to two locations in the durable storage device. This design works well for NVM as it supports fast random writes.
对于abort的事务,DB使用DTT里面的记录来查明这个事务做了什么样的修改,它会撤销这些修改然后回收空间。
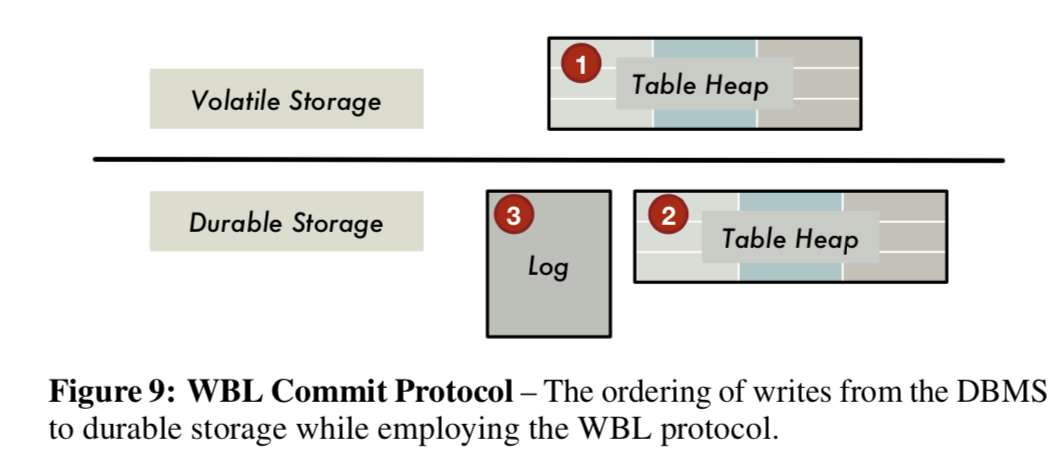
所以这里的基本过程是:DB先将修改在易失性存储(DRAM)上面的table heap,然后在提交的时候,将这些修改刷到非易失的设备上(NVM),最后,记录log。
Recovery Protocol
这里要先注意一个叫做commit timestamp gap的问题,指的是在(C-p, C-d) 之间的时间戳,DB必须忽略这些时间戳在这一个gap之内事务的影响,相当于一个undo的过程。一个后台线程会周期性地扫描然后回收这些脏的修改。
Once all the modifications in a gap have been removed by the garbage collector, the DBMS stops checking for the gap in tuple visibility checks and no longer records it in the log.
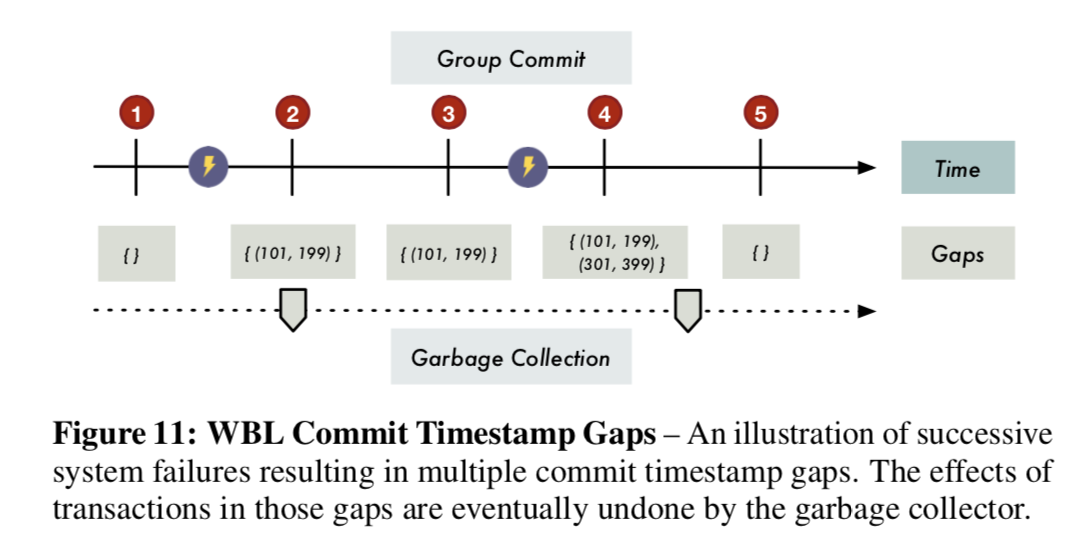
在WBL中,不必要想在WAL中一样周期性的创建checkpoint。因为在WBL的日志记录中包含了足够多的信息实现类型的功能。
This is because each WBL log record contains all the information needed for recovery: the list of commit timestamp gaps and the commit timestamps of long running transactions that span across a group commit operation. The DBMS only needs to retrieve this information during the analysis phase of the recovery process. It can safely remove all the log records located before the most recent log record. This ensures that the log’s size is always bounded.
Replication
WAL除了作为持久化的一个保证之外,还用来做replication,由于WAL的log里面是包含了所有需要的消息的,所以这个很显然。对于WBL来说,由于里面不包含replication需要的所有消息,所以稍微不那么显然了。
But since WBL’s log records only contain timestamps and not the actual data (e.g., after-images), the DBMS has to perform extra steps to make WBL compatible with a replication protocol.
为了解决这个问题,WBL就必须构建另外一个包含了所有需要信息的记录发送个其它服务器。这里认为瓶颈在于网络,这一步对性能的影响不大。
评估
详细数据参看论文[1].
参考
- Write-Behind Logging, VLDB 2016.
