The Multikernel: A new OS architecture for scalable multicore systems
引言
这篇Paper针对的是现在的系统越来越多样,CPU的核心数量越来越多。一种内核为多样的环境和多样的任务都优化得很好是不可能的。为了适应未来的挑战,Paper提出了一种叫做multikernel的新的OS架构,这种内核架构最大的一个特点就是将机器看着是一个由cores组成的一个网络,core之间没有底层的共享结构,将传统的OS的功能转移到通过消息通信的分布式系统之中。促使设计multikernel这样一种kernel 架构的动机:
- 系统变得越来越多样化;
- core也在变的多样化;
- 现在系统的内部连接存在很多问题;
- 消息通信的代价要小于共享内存;
- 缓存一执行不能解决所有的问题(不是万能药);
-
消息通信在变得更加简单;
文中认为现在系统中存在的问题与现在的内核存在很多由共享锁保护的数据结构有很大的关系,这里multikernel则引入分布式系统中的概念,将操作系统的功能分解为分布式的功能单元来重新思考。这里的设计遵循了以下的原则:
- 显式的core间通信;相比于传统的隐式的core间通信,这种方式使得OS可以保持良好的隔离性,以及有利于管理各种各样的核心。此外,这使得在任意的核的拓扑关系间调度任务变得更加有效(虽然我也不知道为什么,反正他就是这么说的),没有缓存一致性,没有共享内存。
- 保持硬件中立性;multikernel的一个设计思想就是尽可能的将OS架构和硬件分离开,这主要来消息传递的原理和硬件接口两个方面,这有利于适应新的研究而不用做出很多的修改,也有利于将方法和具体的实现分离开来。
- 复制状态而不是共享状态;系统中总是存在许多的状态,常见的使用共享数据结构,然后使用锁保护的方式使得系统变得更加复杂而去难以拓展。复制状态也是现在的系统提高性能常用的一种办法,常见的就是per-core的结构。复制也对在运行时改变cores很有用,比如CPU的热拔插。
The contributions of this work are as follows:
• Weintroducethemultikernelmodelandthedesignprinciples of explicit communication, hardware-neutral structure, and state replication.
• We present a multikernel, Barrelfish, which explores the im- plications of applying the model to a concrete OS implemenation.
• We show through measurement that Barrelfish satisfies our goals of scalability and adaptability to hardware characteristics, while providing competitive performance on contemporary hardware.
基本架构
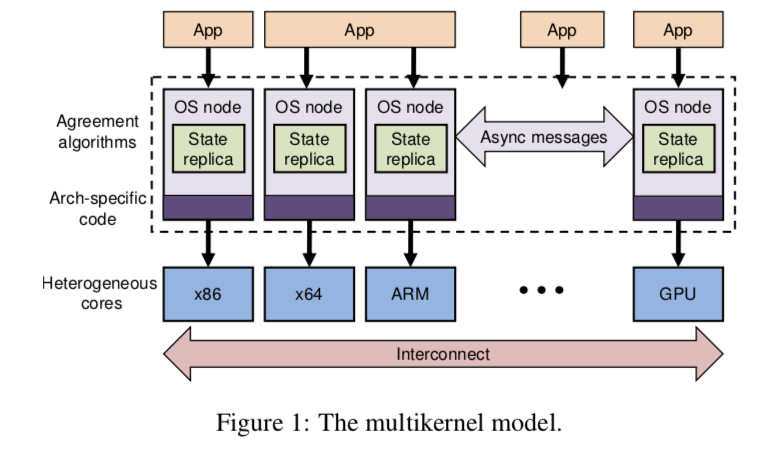
设计实现
Barrelfish系统是在multikernle model下面设计的一个OS。基于显式的消息通信是Barrelfish设计的一个核心之一,
The multikernel model calls for multiple independent OS instances communicating via explicit messages.
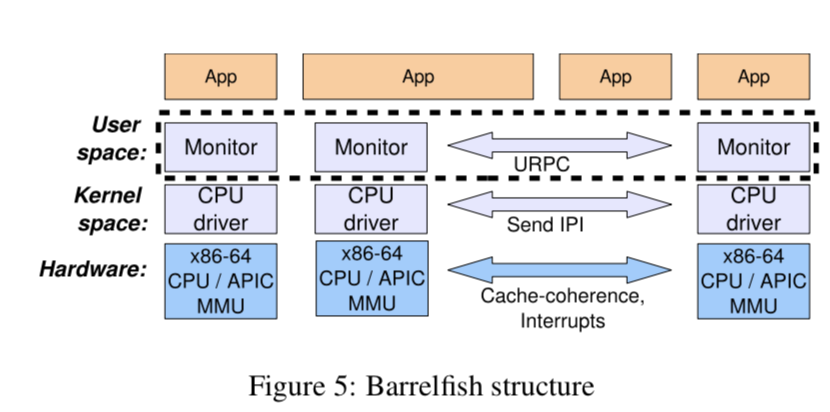
在Barrelfish系统中,一个OS的实例是主要的部分是一个运行在特权态的CPU driver和一个运行在用户态的Monitor组成的, CPU driver运行在一个特点的核心之上,核心之间的通信都是有Monitor来完成的。这些分布式的Monitor和它们对应的CPU driver包含了在传统的monolithic microker-nel的功能,比如调度,通信,底层资源分配等。除此之外,Barrelfish还包含了一些设备驱动和系统服务(如网络栈,内存分配等),这些部分都像微内核一样运行在用户态。设备驱动被发送到相关的核心,由CPU driver多路分解,然后作为一个消息发送给对应的驱动进程。
CPU drivers & Monitors
CPU drivers协调核心和相应的硬件的访问(比如MMU, APIC)。每一个CPU driver和其它的之间没有任何的共享状态,所以它可以是一个完全事件驱动、单线程、不可抢占的。它按顺序处理来自用户进程的trap(这个用中文怎么说比较好??) 、硬件或者其它核心的中断。这个的特性让CPU driver相比于传统的kernel来说就是一个很简单的东西。CPU driver的系统是只在同一个核心之内的:
The CPU driver implements a lightweight, asynchronous (split-phase) same-core interprocess communication facility, which delivers a fixed-size message to a process and if necessary unblocks it. More complex communication channels are built over this using shared memory. As an optimization for latency-sensitive operations, we also provide an alternative, synchronous operation akin to LRPC or to L4 IPC.
Monitors则统一的协调系统范围内的状态,封装了很多在传统的OS中可以见到的机制和策略。
The monitors are single-core, user-space processes and therefore schedulable. Hence they are well suited to the split-phase, message-oriented inter-core communication of the multikernel model, in particular handling queues of messages, and long-running remote operations.
在每一个核心上,复制的数据结构,比如内存分配表、地址空间映射,都由mintors通过一个达成一致的协议来保证一致性。应用程序访问全局状态都得通过mintos来进行。它负责进程间通信的设置,在必要的时候唤醒被阻塞在等待其它核心信息响应的进程。
A monitor can also idle the core itself (to save power) when no other processes on the core are runnable. Core sleep is performed either by waiting for an inter-processor interrupt (IPI) or, where supported, the use of MONITOR and MWAIT instructions.
Process structure & Inter-core communication
Multikernel模型上面的process抽象和在传统的内核上的有所不同。在Barrelfish中,一个进程代表来一个dispatcher对象的集合,可以在任意的一个核心上运行。实际上,在Barrelfish中,通信实际发生在dispatcher之间,而不是进程之间。一个核心上面的dispatchers有在那个核心上面的CPU driver调度,主要这里与传统的调度方式不相同,这里由dispatcher提高的upcall接口唤起,这里具体的方式可以参看Paper给的参考文献,
Dispatchers on a core are scheduled by the local CPU driver, which invokes an upcall interface that is provided by each dispatcher. This is the mechanism used in Psyche and scheduler activations, and contrasts with the Unix model of simply resuming execution. Above this upcall interface, a dispatcher typically runs a core-local user-level thread scheduler.
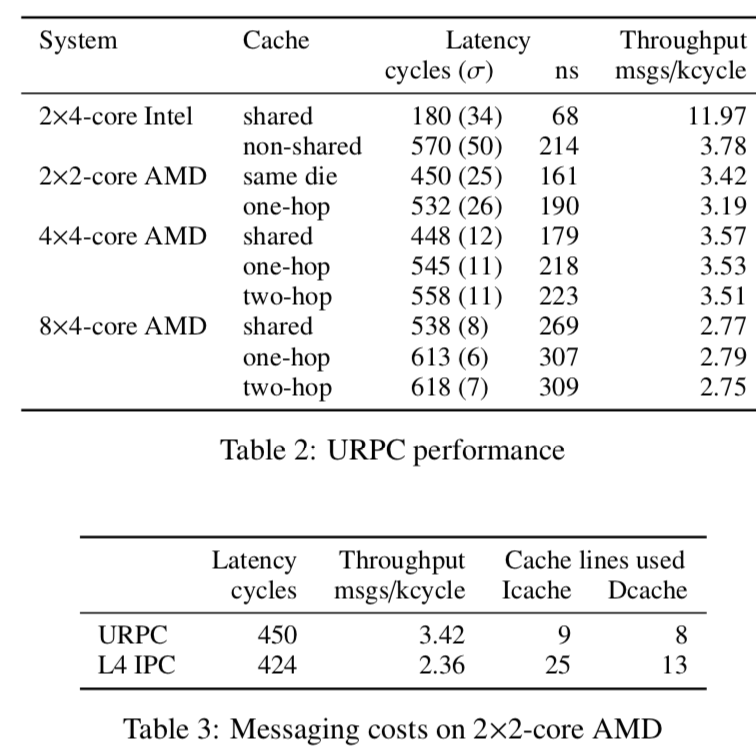
Barrelfish也提供了一个线程的库,接口和Posix的线程库的接口很相似。前面说过了Barrelfish是显式的通信的,以及通信实际上发生在dispatcher之间。系统使用消息的方式,为了兼容各类型的硬件,这里使用时一种user-level RPC: 使用一段共享内存当作是点对点传输信息的通道。由于消息通信在Barrelfish是至关重要的一个部分,它使用了多种的优化方式来提高性能(优化通信的性能在很多微内核的设计中也做了很多的尝试,可以参考相关的论文):
系统的接口设计也是一个很重要的部分,
All message transports are abstracted behind a common interface, allowing messages to be marshaled, sent and received in a transport-independent way. As in most RPC systems, marshaling code is generated using a stub compiler to simplify the construction of higher-level services. A name service is used to locate other services in the system by mapping service names and properties to a service reference, which can be used to establish a channel to the service. Channel setup is performed by the monitors.
Memory management & Shared address spaces
虽然一个multikernel把机器当作是一个分布式的系统,它也还是要管理一些全局的资源,比如内存。Barrelfish使用的内存管理方式和seL4(雾,又要级联地去看论文)类型,都是使用显式的系统调用来管理,这种方式使得在用户层面引用内核对象和物理内存的区域(没怎么看懂,为什么会有这些好处,这里需要去读一读L4之类微内核相关的东西,雾):
The model has the useful property of removing dynamic memory allocation from the CPU driver, which is only responsible for checking the correctness of operations that manipulate capabilities to memory regions through retype and revoke operations.
虚拟内存的管理,包含内存分配和操作页表,都是由运行在内核空间的程序来完成的。虽然将一些编程语言的运行时改为multi-kernele的模型很有趣,但是对于大部分的情况来说,兼容一下传统的办法也是一个很好的选择。这里Barrelfish也支持传统的基于一个进程内多个共享内存空间线程的模型。前面说过,dispatcher时进程里面的一个核心概念,这里这个模型也是基于dispatcher来实现的,
Barrelfish supports the traditional process model of threads sharing a single virtual address space across multiple dispatchers (and hence cores) by coordinating runtime libraries on each dispatcher. This coordination affects three OS components: virtual address space, capabilities, and thread management, and is an example of how traditional OS functionality can be provided over a multikernel.
共享的虚拟地址空间可以通过共享一份page table实现,也可以通过复制这个page table来实现,这个各有不同的取舍。核心之间的线程的管理也是通过用户空间的代码进程的,线程调度器通过消息来创建、unblock线程,也可以通过消息来在dispatcher之间迁移线程。
Barrelfish is responsible only for multiplexing the dispatchers on each core via the CPU driver scheduler, and coordinating the CPU drivers to perform, for example, gang scheduling or coscheduling of dispatchers.
评估
具体数据参看论文。
We make stronger claims for the microbenchmarks. Barrelfish can scale well with core count for these operations, and can easily adapt to use more efficient communication patterns (for example, tailoring multicast to the cache architecture and hardware topology). Finally we can also demonstrate the benefits of pipelining and batching of request messages without requiring changes to the OS code performing the operations.
参考
- The Multikernel: A new OS architecture for scalable multicore systems, SOSP 2009.
