PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs
引言
来看一篇关于图计算的Paper,这篇Paper来自上海交通大学。PowerLyra要解决的问题主要就是现在的一些图分区的方式不能很好地处理现实中的数据发布不均匀的问题。现在使用edge-cuts或者是vertex-cuts的方法均存在不足,PowerLyra提出了一种混合的分区的方式,利用好两种分区方式适应不同情况的优点。
背景
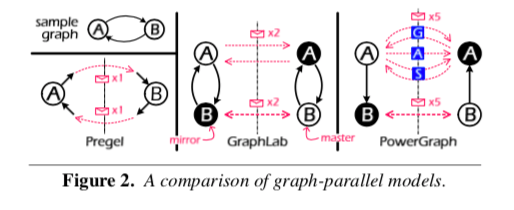
现在的图计算为了处理大规模的图,往往不可避免地要对图进行分区。分区的一个最直观的思路就是类型Pregel的方式,将顶点根据一定的规则划分到不同的分区,这样的一个效果就是有些边是跨越了分区。另外一种就是类似在GraphLab中采用的方法,分区的时候对于跨越了分区(机器)的边的顶点,就复制顶点一份,而且边也复制一份。PowerGraph的思路与前的两种存在又存在一些区别,它也存在顶点的副本,但是边没有。
存在的问题
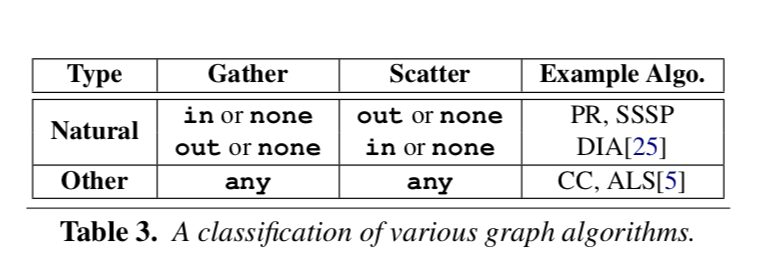
Pregel中和GraphLab中采用的方法被称为edge-cut的方法,它的优点就是有更加好的局部性。可以试图将可能地降低跨越了分区的边的数量,缺点就是由于顶点的度数在很多自然的数据中是发布不平衡的,少数的顶点拥有大量的边,而其它的部分的顶点的边的数量比较少,这种情况下就会导致负载不均衡的现象。而PowerGraph、GrpahX之类的系统采用的vertex-cut的方法好处就是解决了一些数据分布不均衡的问题,能获得更高的并行性。缺点就是会造成比较大的复制因子(the average number of replicas for a vertex),另外就是增加通信量,对于一些低度数的点这样的分区更多是无用的。所以,既然不同的分区方式有不同的优缺点,PowerLyra就应用一种混合的方法。
PowerLyra
PowerLyra是基于PowerGraph改进而来的。在图划分的时候,和PowerGraph一样,PowerLyra将一个顶点的副本中使用一种hash算法随机选择一个作为Master,其余的作为Mirrors,也同样适用GAS的编程模型。对于顶点计算的处理,PowerLyra采用了Hybrid的方法,处理high-degree的顶点时,为了获取更高的并行性,PowerLyra基本上采用的就是PowerGraph的方法,做了一些的修改。
* Gather, two messages are sent by the master vertex (hereinafter master for short) to activate all mirrors to run the gather function locally and accumulate results back to the master.
* Apply, the master runs the apply function and then sends the updated vertex data to all its mirrors.
* Finally, all mirrors execute the scatter function to activate their neighbors, and the master will similarly receive notification from activated mirrors.
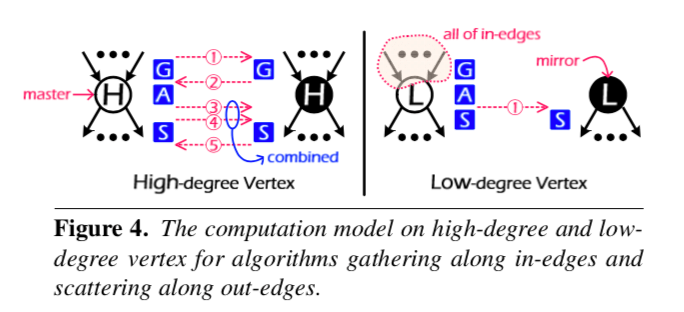
处理low-degree的顶点时,为了获取更好的局部性,PowerLyra又采用了类似GraphLab的方式,但是并没有想GrapgLab那些双向边都考虑,而是注意到实际的算法中,这个局部性往往只体现在一个方向,所以PowerLyra提出了一种单向的局部性。还有PowerLyra根据一个自适应的策略来处理不同算法在gathering和scattering数据的时候在应用在不同类型的边的问题(出边,入边),
As shown in the right part of Fig. 4, since all edges required by gathering has been placed locally, both the Gather and Apply phases can be done locally by the master without help of its mirrors. The message to activate mirrors (that further scatter their neighbors along out-edges) are combined with the message for updating vertex data (sent from master to mirrors).
分区
Balanced p-way Hybrid-Cut
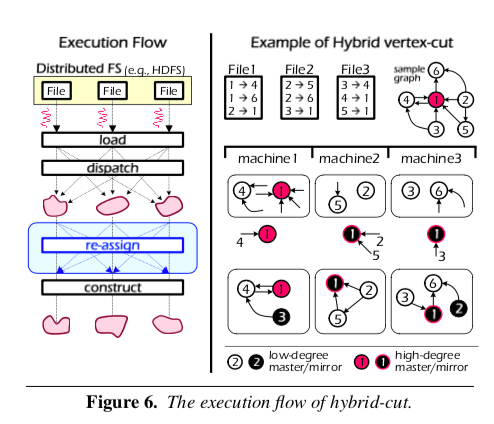
现在的vertex-cut的方式都注重减少顶点的复制因子,但是PowerLyra认为,这里的关键不在于减少所有顶点的复制因为,因为对于high-degree的顶点,它难免会被复制多次。所以PowerLyra不把减少这个复制因子的注意力放在High-degree的顶点上,而是low-degree的顶点上。PowerLyra中使用一种balanced p-way hybrid-cut的方法。PowerLyra这里使用了low-cut和hight-cut的概念。low-cut,就是对于low-degree的顶点,hybrid-cut 采用 low-cut的方式,通过利用目的顶点的hash来将顶点和它们的入边均匀分配。hight-cut,就是对于hight-degree的顶点,hybrid-cut的方式,通过利用源顶点的hash来将入边分配,之后PowerLyra会创建顶点的副本,创建本地的具体的子图,
- 对于low-degree的顶点,入边根据目的顶点分组,不同创建这些顶点的副本,这样就会有比较低的复制因子。对于high-degree的顶点,副本的数量取决于分区的数量;
- 对于low-degree的顶点,hybrid-cut提供单向访问的局部性;
- Low-degree和high-degree的结点都根据hash分区,在处理graph ingress的问题的时候效率较好;
- hybrid-cut能够很好地处理边和顶点的均衡性;
另外,为了进一步将少low-degree顶点的复制因子,PowerLyra还采用了Heuristic Hybrid-Cut的方法[1]。
构建
一个通用的结构hybrid-cut的方法就是在初始的streaming graph partitioning方法上加上一个re-assignment的步骤。一个用户定义的阈值来区分是low-degree还是high-degree。开始时使用low-cut的方式分区,之后对于识别为high-degree顶点的入边会被重新分区,最后创建顶点的副本。
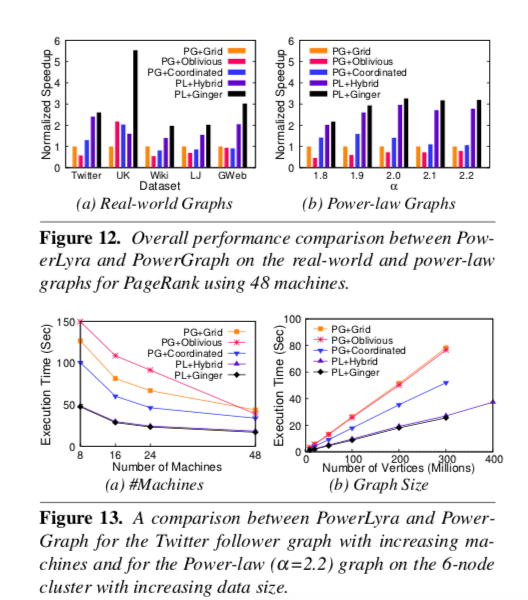
评估
这里的具体的信息可以参看[1].
参考
- PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs, EuroSys’15.
