Speedy Transactions in Multicore In-Memory Databases
引言
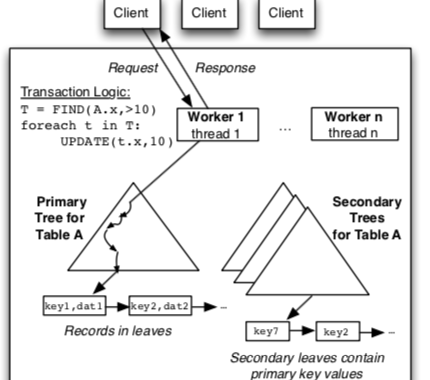
Silo是一个MIT做的一个内存数据库,使用一种OCC并发控制协议,主要的index结构是Masstree,一种为内存数据库设计的B+tree和trie的结合体。
Silo achieves almost 700,000 transactions per second on a standard TPC-C workload mix on a 32-core machine, as well as near-linear scalability. Considered per core, this is several times higher than previously reported results.
基本架构
Silo本质上还是一个关系型数据,只不过数据都保存在内存。当然Silo也有数据备份到磁盘上面的一个版本SiloR。
Epoch
Epoch是Silo中一个很重要的内容,Silo使用epoch机制来实现serializable recovery,垃圾回收,以及read-only snapshots。Epoch就是一段时间。系统换维护一个全局的Epoch,使用E表示。每一个Epoch会由一个epoch number来标示,一个指定的线程会周期性地去更新这个值,每一个在提交事务的时候都必须去参看这个值。Epoch改变的周期设计到事务提交的延迟和系统的一些的overhead,这是一个权衡的问题,在Silo中,这个周期为40ms。另外,每一个worker维护一个本地的Epoch,记为ew,这个值可以滞后于全局的E,但是不能超过1。本地的Epoch用来什么时候可以进行垃圾回收,
... Silo requires that E and ew never diverge too far: E −ew ≤ 1 for all w. This is not usually a problem since transactions are short, but if a worker does fall behind, the epoch-advancing thread delays its epoch update. Workers running very long transactions should periodically refresh their ew values to ensure the system makes progress.
在快照事务中还会有其它的一些内容。
另外几点
Silo设计中另外的几点,
-
事务ID,Silo中使用一个事务ID来唯一表示一个事务或者是一个记录的版本,也用来作为锁和探测数据冲突,一个记录中记录的TID为最佳修改这个记录的事务ID。这些和一些基于MVCC方式的系统一样。在Silo中,TID使用一个64bit的整数值来表示,TID的高位就是Epoch的值,它会等于提交的时候全局的E的值。中间的一些bits用于唯一标识这个Epoch内的一个事务,最低位的几个bits是一些状态信息位(status bits)。
-
TID中的状态信息为包括了: 一个lock bit, 一个latest-version bit, 和一个 absent bit。lock bit用作为latch。latest-version bit用作表示这条记录是不是对应的Key最新版本的数据,absent bit标记不存在的Key。
-
Silo使用一种非中心化的方式来分配这个TID,一个事务在验证可以提交之后才会分配一个TID。它会选择一个满足下面条件的最小的一个数作为TID:大于这个事务读取or写入记录的TID;大于这个Worker最近选择的TID;组合全局的E构建TID。在Silo中的TID并不能严格地反映顺序。提交的时候事务会写入这个TID到每一条修改的记录中。
-
Silo中的一条的记录的基本结构是TID + 上一版本记录的指针 + 数据。
-
Silo中的次级索引使用同样的数据结构Masstree,次级索引的key会映射到主键,在通过主键来操作数据;
-
Silo需要回收的垃圾来自不在使用的Masstree的节点和数据记录两个部分。Silo使用前面的Epoch机制来实现了一个类似RCU的垃圾回收的方式。reclamation epoch对应的是不在可能去访问的数据,到达了这个阶段时候垃圾对象就可以安全回收了,
Thanks to the way epochs advance, no thread will ever access tree nodes freed during an epoch e ≤ min ew − 1. The epoch-advancing thread periodically checks all ew values and sets a global tree reclamation epoch to min ew − 1. Garbage tree nodes with smaller or equal reclamation epochs can safely be freed. -
关系型数据库在一些隔离级别下面时候要处理phantom的问题,为了必须对read-set进行加锁,Silo利用它底层使用的Btree的变体来实现,Silo中的Btree实现可以保证在对树结构修改的时候会修改参与到的节点。范围查询的时候,Silo会另外维持一个node-set,用于去检查这些版本信息以确保没有新的数据添加到这个范围or从这个范围内删除。由于Key的不存在,导致查找or删除失败的时候也可能出现Phantom现象,这个在提交的时候也必须保证这些Key不在数据库里面,这个时候可能会添加这些缺失的Key的节点也会添加到node-set中。
提交协议
在Silo中,事务的提交主要分为三步。一个事务的执行的过程中,事务会读取的记录会记为一个read-set,会写入的记录会记录为一个write-set,一般而言在write-set中的记录也会在read-set中。在Phase 1,事务会测试是由要读取的记录并尝试加锁,加锁使用记录的地址排序来避免死锁。在加锁完成的时候,读取全局的E保存到本地。在Phase 2,测试read-set中的记录是否被更新,或者是被其它的事务加锁了,事务就得abort。完成检查之后就可以产生commit-tid了。在Phase 3,事务写入新记录,更新TID,释放锁。
Data: read set R, write set W, node set N, global epoch number E
// Phase 1
for record, new-value in sorted(W) do
lock(record);
compiler-fence();
e ← E;
compiler-fence();
// Phase 2
for record, read-tid in R do
if record.tid != read-tid or not record.latest or (record.locked and record ̸∈ W )
then abort();
for node, version in N do
if node.version != version
then abort();
commit-tid ← generate-tid(R, W , e);
// Phase 3
for record, new-value in W do
write(record, new-value, commit-tid);
unlock(record)
在执行事务提交的时候,如果一个事务发现一个版本的记录可以覆盖的时候,会直接修改。如果不能直接修改,就创建一个新的版本。删除的时候不能直接就删除数据,而是使用前面提到的标记位。
Snapshot Transactions
Silo支持快照事务(只读),引入了其它的一些机制。管理快照主要要解决2个问题:一个是确保快照一致性和完整,另外一个是确保这些内存最终被回收。Silo引入来Snapshot Epochs。它的边界和Epoch是系统的,但是更新的频率会远低于Epoch更新的频率,Silo的设置中大约慢25倍,即Snapshot的Epoch snap(e) = k · ⌊e/k⌋, k=25。大约为1s。更新全集的E的线程也会周期性地更新全局的snapshot epoch,表示为SE,SE ← snap(E − k)。同样的,每一个Worker会维护一个本地的sew。在每一个事务开始的时候,会设置sew = SE。快照事务会使用这个值去发现正确版本的数据。快照事务提交的时候不需要坚持,也不会abort。要保证快照的一致性除了要找到正确版本的数据之外,还是保证读写事务不回去覆盖这些数据,所以这里就是前面将的有些情况下读写事务不能直接去覆盖之前的数据,而是去创建新的数据版本。同样地,对于快照事务中的垃圾回收,也是使用基于Snapshot Epoch的方式,存在些许区别但是没有什么本质上的不同,
When a transaction committing in epoch E allocates memory for a snapshot version, it registers that memory for reclamation with epoch snap(E). The epoch-advancing thread periodically computes a snapshot reclamation epoch as min sew − 1. Snapshot versions with equal or smaller reclamation epochs can safely be freed. The reclamation process need not adjust any previous-version pointers: the dangling pointer to the old version will never be traversed, since any future snapshot transaction will prefer the newer version.
另外关于Silo持久化的机制在另外一篇Paper里面[2].
评估
这里的具体信息可以参考[1]。在这篇Paper中的数据是非常好的,但是在另外一些关于内存数据库的Paper里面,认为Silo的OCC的方式在写入冲突一多的时候事务abort的概率会快速增长,
参考
- Speedy Transactions in Multicore In-Memory Databases,SOSP 2013.
- Fast Databases with Fast Durability and Recovery Through Multicore Parallelism, OSDI’14
