LITE Kernel RDMA Support for Datacenter Applications
引言
这篇Paper是SOSP‘17中关于利用RDMA构建数据中心应用的一篇文章,也是非常赞的一篇文章。在RDMA应用到数据中时,RDMA不够灵活、缺乏高层次的抽象的缺点不利于它的应用。为了解决这个问题,LITE提出了在Linux内核中构建一个RDMA的灵活的、高度的和易用的一个抽象,
... our implementation of graph engine has only 20 lines of LITE code, which encapsulate all the network communication functionalities. While using the same design as PowerGraph, this LITE-based graph engine outperforms PowerGraph by 3.5× to 5.6×. Our LITE-based MapReduce is ported from a single-node MapReduce implementation with 49 lines of LITE code, and it outperforms Hadoop by 4.3× to 5.3×.
LITE认为,现在在数据中心应用RDMA中,存在3个主要的问题,而LITE就是为了解决这些问题,
- Mismatch in Abstractions。不合适的抽象,RMDA提供两种类型的API,one-sided和two-sided。这两种API有各自的特点,现在一些关于利用RDMA做事务处理、KVS等都有提及到这两种API的取舍。而LITE在意的是它们都很难用;
- Unscalable Performance,By-pass Kernel的方式使得特权操作和一些数据结构被搬到了RNIC,RNIC上面的内存有限,它有承担了太多的功能。导致了拓展性不强。
- Lack of Resource Sharing, Isolation, and Protection,原始的RDMA没有提供各种资源共享的机制,缺乏全局的资源管理方法。另外 lkeys和 rkeys的保护机制也很灵活。
基本设计
而LITE解决这些问题的一个基本的思路是虚拟化和增加管理层,而且实现在内核中,与现在的流行的by-pass kernel的方式相比,LITE认使用内核间接的方式能同时获得灵活性和低延迟。LITE的基本架构的设计和传统的RDMA架构的一个对比。LITE使用一个在内核空间的间接层来虚拟化RDMA,管理和虚拟化RDMA的资源,同时向上提供高度抽象化、易用的API(对Kernel中的应用和Application都可以)。LITE支持3中类型的接口:类似内存使用的结构、RPC和消息,还有就是同步原语。
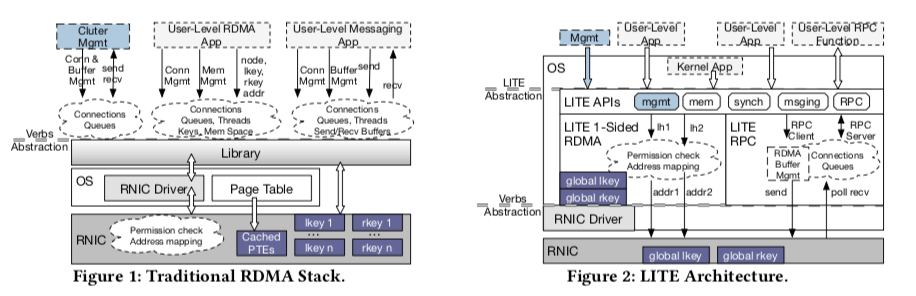
对于LITE来说,它主要就是2个部分的实现:一个就是利用RDMA one-sided定做的一些操作,另外一个就是利用two-sided实现的RPC功能和消息系统的操作。2个部分之间也关系一些如 QPs, CQs, 和 LITE内部线程这样一些资源。另外LITE不允许用户传递MR信息,从而避免了以明文形式传递rkeys而操作的安全的问题。
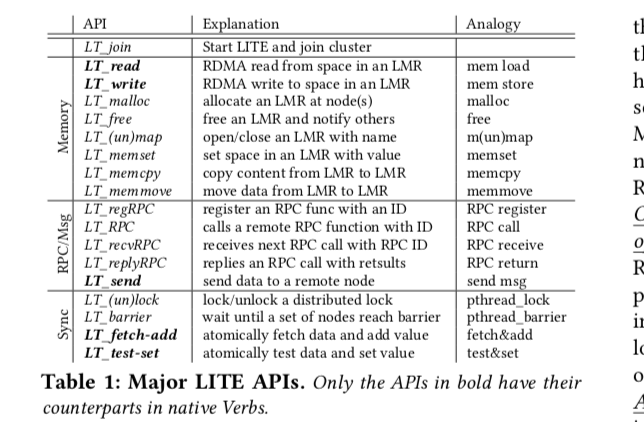
内存抽象和RDMA
LITE的内存抽象建立在RDMA的one-sided的API之上。和原生的RDMA一样,在LITE中的RDMA的one-sided操作也不会涉及到远程的CPU、内核甚至是LITE的参与。LITE的内存抽象基于Memory Regions (LMRs)(内存区域的)的概念。虚拟的内存区域由LITE管理并暴露给应用使用,可以任意的尺寸并对不同用户有不同的权限。一个LMR可以映射到一个or多个实际的物理内存区域,可用于负载均衡。LITE会隐藏底层的消息,交给应用的是LMR handler(lh),应用利用这里lh和LITE提供的API进行操作。从上面的表中提供的API可以看出,这些API很像是一般的内存操作(上面这个表没有指出操作的参数)。LITE管理lh到物理内存映射的具体信息,并在操作的时候检查权限。
Unlike native RDMA which lets users pass rkey and MR virtual memory address across nodes to access an MR, LITE prevents users from directly passing lhs to improve security and to simplify LMR’s usage model. All lh acquisition has to go through LITE using LT_map. LITE always generates a new lh for a new acquisition.
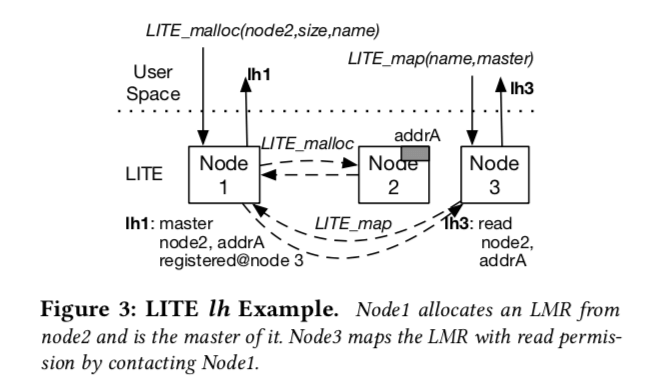
在LITE还有一个Master role的概念。LITE将创建这恶搞LMR的用户称为Master role,这个Master role可以选择在哪一个结点上分配这个LMR,也可以支持注册一个已经分配的内存区域位一个LMR。Master可以将一个LMR从一个结点移动到另外一个结点。另外需要使用这个LMR,必须向Master申请,这个在上面的图中有体现。使用Master会保存了一个映射到了这个LMR的一个结点的列表。在Master移动这个LMR时,其它的结点都会收到通知。每一个LMR可以有不止一个Master。 一个应用想使用一个LMR的时候,得先向Master申请一个lh(使用LT_map接口) 。Master的LITE会进行权限检查然后保存这个结点的信息,最后向这个结点返回一个新的lh。相关的元数据会被结点保存起来,之后就可以利用LITE提供的API对其进行操作了。当想要解除映射的时候,需要通知Master来解除。
在LITE管理来LMR的地址映射和权限检查之后,LITE就试图在RNIC中去掉一些不需要的结构来减少其内存压力。 但是没有修改硬件,LITE就只能用实际的MR执行原始的 RDMA操作,而这些信息就是保存在RNIC中,造成了RNIC的压力。这里LITE利用一个巧妙的方法解决这个问题,LITE利用RDMA一些不常用的API(没有具体提到时什么样的API),在内核空间,LITE可以直接使用物理地址直接向RNIC注册MR。 LITE利用这个不常用的API注册一个覆盖整个物理内存的的MR(?),这个MR被称为 global MR。LITE利用这个 global MR的方法消除了很多overhead。在做了以上提到的一些优化(以及这里没有提到在Paper中说明的一些优化之后),LITE还保留了RDMA零拷贝的特点以及 LT_read 和 LT_write API也可以避免了应用轮询的操作。LITE的优点体现在以下的几个方面,
- LITE的内存抽象在LMR的物理位置、命名以及权限上有很大的灵活性。LITE这层间接也很“透明”,但是仍然实现了很好的内存管理和负载均衡;
- LITE不需要其它任何的修改,它就是内核中的一个模块;
- LITE解决了原生的RDMA存在的可拓展性的问题,在大规模的情况下期望它有更加好的性能(为什么是期望,23333);

RPC
RPC时LITE实现的更加high-level的接口。LITE的RPC的实现主要有2点,
- 基于write-imm的通信。LITE的使用两次的write-imm的verbs来实现RPC的通信,而不是是直接使用RDMA中的send/recv的接口。write-imm中write中添加了一个32bit的一个数。LITE在使用一个write-imm完成RPC调用的输入传输之后,对方使用write-imm来实现返回。这里方法类型一些基于RDMA操作的KVS的做法。和前面的内存的抽象一样,LITE也是使用一个共享的线程来轮询;
- RPC处理,LITE的基本的操作流程,类似于一个生产者消费者的模型,没有特别特殊的地方。处理的流程如下面的如所示,
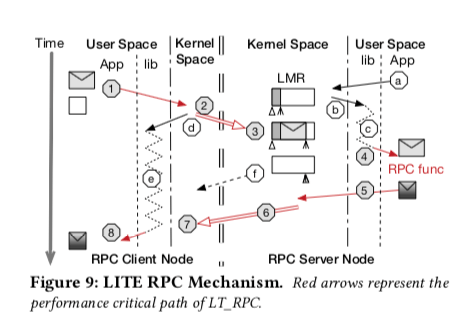
直接按照上面的思路实现的化,就会涉及到LT_RPC, LT_recvRPC,和 LT_replyRPC三次的调用,6次内核空间和用户空间的切换,在Paper中的测试环境中大约消耗0.9 μs,这个会是一个不小的overehad。为此,LITE的RPC实现采用了一系列的优化手段,
- 为了减少内核空间和用户空间切换带来的开销,内核中的LITE接收到 LT_RPC、LT_recvRPC系统调用时,它是直接而不同得到RPC调用完成,剩下来的事情有LITE的用户空间的库来处理。LITE使用一小块内核和用户共享的内存来实现结构返回;
- 使用可选的接口了 LT_replyRPC和 LT_recvRPC功能的API,在处理上一个结构是顺便处理下一个的输入,提高性能;
- LITE用户空间的库使用的线程在处理的实现会先忙检查一小段时间,在这段时间之后还没有结构就会进入睡眠,这个有点像一些锁的机制;
- 为了降低内存拷贝带来的开销,LITE使用直接寻址用户空间buffering的物理地址的方式避免绝大部分的内存拷贝。
性能表现
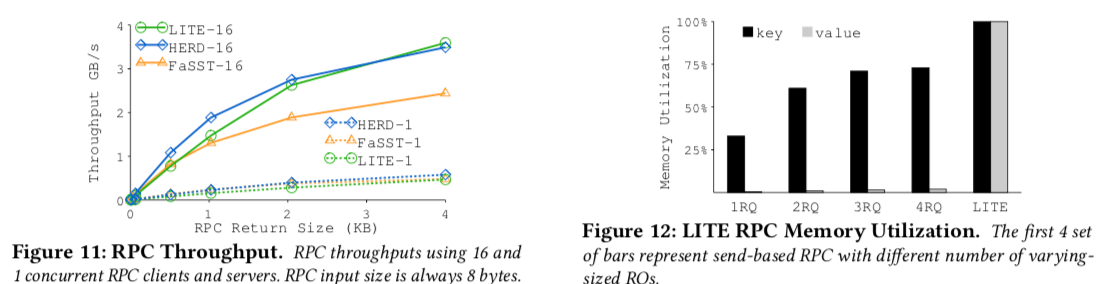
Paper中的数据表明LITE的性能是相当优秀了,
资源共享以及QoS
由于LITE是内核中在内核中的一个间接层,这个LITE的资源共享以及QoS的实现提供了方便,
-
对于资源共享来说。LITE可以看作是将之前每个应用单打独斗交给了LITE统一管理。这样实现资源共享就方便多了,
LITE uses K×N QPs and one busy polling thread for a shared receive CQ per node, where N is the total number of nodes. K is a configurable factor to control the tradeoff between total system bandwidth and total number of QPs;这里LITE使用了K*N QPs,而传统的方式实现就需要2×N×T个(T为每个节点的线程数)。
-
资源隔离和QoS上,LITE存在两种实现方式,基于硬件的和基于软件的。LITE在做了测试之后发现软件的方式优于硬件的方式。软件的方式使用了三种策略的组合来实现基于优先级的流控制和拥塞控制:1. 当高优先级作业负载高是限制低优先级的任务,2. 没有高优先级或者是只有负载很强的高优先级的任务是不同限制低优先级的任务,3. 高优先级任务的RTT增加时,限制低优先级的任务。
一些应用以及评估
Paper中讨论了利用lITE实现的一个如Distributed Atomic Logging、MapReduce和Graph Engine等的方便性和高性能。这里具体的信息可以参看[1]

参考
- LITE Kernel RDMA Support for Datacenter Applications, SOSP’17.
