MegaPipe: A New Programming Interface for Scalable Network I/O
引言
网卡性能的提高,自然对kernel的网络栈的性能也提出了更加高的要求。网络栈的一些缺点在这些高性能的网卡中也会体现地更加明显。目前系统存在的一些问题:
- Contention on Accept Queue(accept队列上的竞争): accept queue只有一个,操作加锁,这样就导致了CPU核心之间的竞争。影响了kernel添加连接和application接受一个新的连接。此外,这样的设计也是缓存不友好的;
- Lack of Connection Affinity(缺乏连接亲和性): 在Linux中,已经存在了RSS、RPS等机制将接受的数据包分发到每个CPU核心上。一个CPU核心上接受的新连接的数据包可能是另外一个CPU核心接受的。
- File Descriptors :POSIX中一个很差劲的设计,但是可能没想到对以后的系统会有这么大影响。每次分配的fd必须是最小的,这个在实际中是没有这个需要的,标准中确加了进去。(the cost of allocating a single FD is roughly 16% greater when there are 1,000 existing sockets as compared to when there are no existing sockets. )
- VFS: UNIX中一切皆为文件的设计思想,将socket和VFS耦合到了一起,每个socket关联了一个file instance, inode, and dentry data structures,只从网络栈的角度来看,这些都是没有必要的。
- System Calls ,大量的syscall的overhead也不容小视。(linux 新加了系统调用sendmmsg之类的来优化性能)
基本架构
不同于Accept Affinity[2]和Fastsocket[3],MegaPipe是更加完整的解决方案(虽然它出现的时间早,emmmm,和Accept Affinity一样发表在2012年),不过缺点就是与现在的系统不兼容。
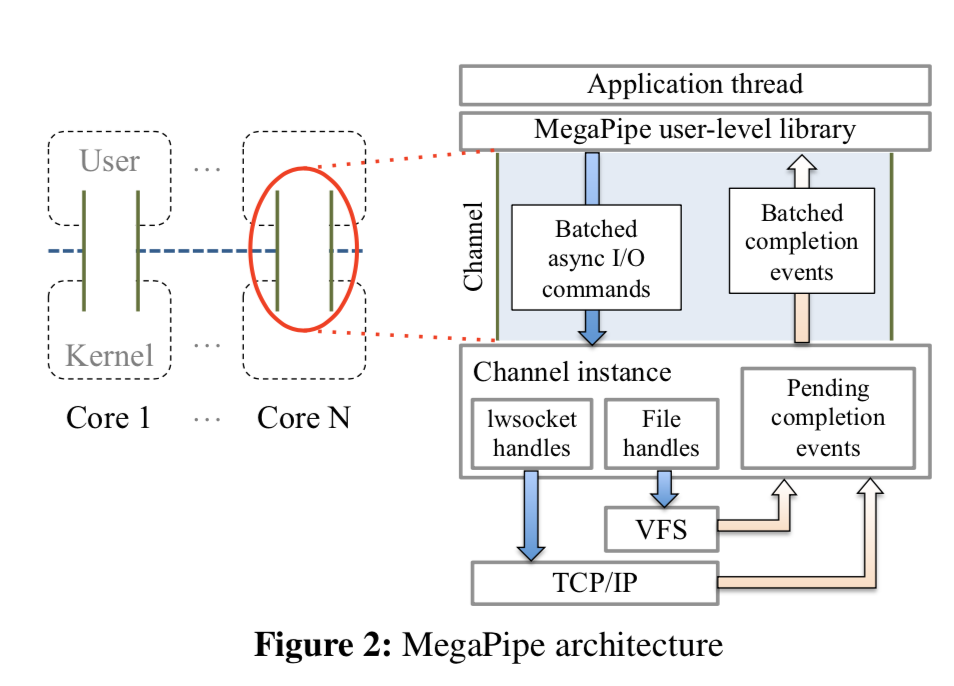
MegaPipe主要通过使用三种方法解决上面提到的问题:
- Partitioned listening sockets,不同于现在的系统的在一个共享的listening socket接受连接,MegaPipe允许应用克隆一个listening socket,将对应的结构分区,减少在共享结构直接的竞争,提高性能。
- Lightweight sockets,之前的socket和VFS是紧耦合的,这里MegaPipe使用了一种lwsocket,不在于文件相关的结构相关。
- System Call Batching,将异步IO的syscall批量处理,然后通知通过channel通知处理的情况(有点Windows上面的IO Completed Port 的味道),平摊syscall的开支(Linux最近的一些优化也是添加了类似的syscall,比如sendmmsg的syscall,可以将多次sendmsg组合在一次发送)。
Listening Socket Partitioning
这里是[1,2,3]都讨论要优化的地方,这里MegaPipe的解决方案和Accept Affinity的有些不同。Accept Affinity使用的方式是每个core一个accept queue,应用线程优先在本地的core上的accept queue来处理连接。MegaPipe使用的方式是一个应用线程在创建了一个listening socket并将其与一个channel关联之后,MegaPipe会产生一个新的listening socket,这个新的socket有自己的accept queue,而且只处理特定的被显示指定的CPU上面的连接请求。
After a shared listening socket is registered to MegaPipe channels with disjoint cpu_mask parameters, all channels (and thus cores) have completely partitioned backlog queues. Upon receipt of an incoming TCP handshaking packet, which is distributed across cores either by RSS or RPS , the kernel finds a “local” accept queue among the partitioned set, whose cpu_mask includes the current core.
对于一个应用线程来说,它就处理自己本地的accept queue,避免的竞争。这里和Accept Affinity最大的一个不同点在于,Accept Affinity的分区处理是透明的,而MegaPipe要应用来显式的处理这个问题。两种方式个有利弊。此外Accept Affinity处理了负载均衡的问题,MegaPipe在论文中暂时没有处理。
The downside is that legacy applications do not benefit. However, explicit partitioning provides more flexibility for user applications (e.g., to forgo partitioning for single-thread appli- cations, to establish one accept queue for each physical core in SMT systems, etc.)
lwsocket: Lightweight Socket
这里简而言之就是想办法将socket和VFS分离开,当然也不会有必须是最小的整数的要求。lwsocket一个设计的激进但合理的就是彻底地将lwsocket和VFS相关的分开,将file instance, inode, dentry这些都从实现中取出来,好处就是最有利于提高性能,缺点就是会操作兼容性的问题,也会使得一些工具不可用,比如lsof这类的。这里的做法就有其它的方式,比如fastsocket的方式就是将这部分在不影响兼容性的情况下就可以的去除这些东西。
we propose lightweight sockets – lwsocket. Unlike regular files, a lwsocket is identified by an arbitrary integer within the channel, not the lowest possible integer within the process. The lwsocket is a common-case optimization for network connections; it does not create a corresponding file instance, inode, or dentry, but provides a straight shortcut to the TCB in the kernel. A lwsocket is only locally visible within the associated MegaPipe channel, which avoids global synchronization between cores.
System Call Batching
大量的syscalls也会带来不小的开支,批量处理是一个常见的策略,MegaPipe这里的的方式就是将一些请求打包在一起,发送给内核空间,然后在完成请求的时候通知。应用不用显式的处理,这个由user-level的库处理的。所以这里要有一个什么时候将这些积累的请求发送给那个的机制:
When i) the number of accumulated requests reaches the batching threshold, ii) there are not any more pending completion events from the kernel, or iii) the application explicitly asks to flush, then the collected requests are flushed to the kernel in a batch through the channel.
API
MegaPipe最大的一个缺点就是与现在的API不兼容,这也就导致了MegaPipe不太可能得到实际的应用(不过作为研究还是非常不错的,里面的解决方案也可用来改进现在的系统)

参考
- MegaPipe: A New Programming Interface for Scalable Network I/O, OSDI 2012.
- Improving Network Connection Locality on Multicore Systems, EuroSys’12.
- Scalable Kernel TCP Design and Implementation for Short-Lived Connections, ASPLOS ’16.
