mTCP: A Highly Scalable User-level TCP Stack for Multicore Systems
引言
mTCP是在用户态实现的TCP网络协议栈,目的是解决目前的内核网络栈存在的可拓展性的问题。具体的一些问题在前面的几篇文章中已经提到了。
- Lack of connection locality,Affinity-Accept[3]和MegaPipe[2]也尝试解决这个问题;
- Shared file descriptor space,VFS带来的overhead;
- Inefficient per-packet processing,低效的包处理;
-
System call overhead,系统调用的开销。
mTCP通过综合多中技术:1. 将昂贵的syscall转化为为一个简单的引用操作,2. 高效的流事件聚合,3. IO操作批量化处理等最终实现了性能的大幅提升:
Our evaluations on an 8-core machine showed that mTCP improves the performance of small message transactions by a factor of 25 compared to the latest Linux TCP stack and a factor of 3 compared to the best-performing research system known so far. It also improves the performance of various popular applications by 33% to 320% compared to those on the Linux stack.
用户态协议栈
这里与前面优化的最大的一个不同这个协议栈是实现中用户态的。个人觉得mTCP和MegaPipe有很多相似的地方,最大的不同就是协议栈的位置不同。mTCP通过将协议栈移到用户空间,释放了更多的潜力,还有一个优点就是完全去除了VFS的影响以及系统调用的开销。在Paper中也提到了在处理大量的网络流量的时候,大部分的时间都花在了内核的网络栈上,Affinity-Accept和MegaPipe做了一系列的优化之后,将协议栈做到用户态是一个优化点(接下来就是直接使用虚拟化访问硬件,接下来的OSDI 2014上面的两篇文章会将到):
Our results indicate that Linux and MegaPipe spend 80% to 83% of CPU cycles in the kernel which leaves only a small portion of the CPU to user-level applications. Upon further investigation, we find that lock contention for shared in-kernel data structures, buffer management, and frequent mode switch are the main culprits. This implies that the kernel, including its stack, is the major bottleneck.
...
We find that mTCP uses the CPU cycles 4.3 times more effectively than Linux. As a result, mTCP achieves 3.1x and 1.8x the performance of Linux 2.6 and MegaPipe, respectively, while using fewer CPU cycles in the kernel and the TCP stack.
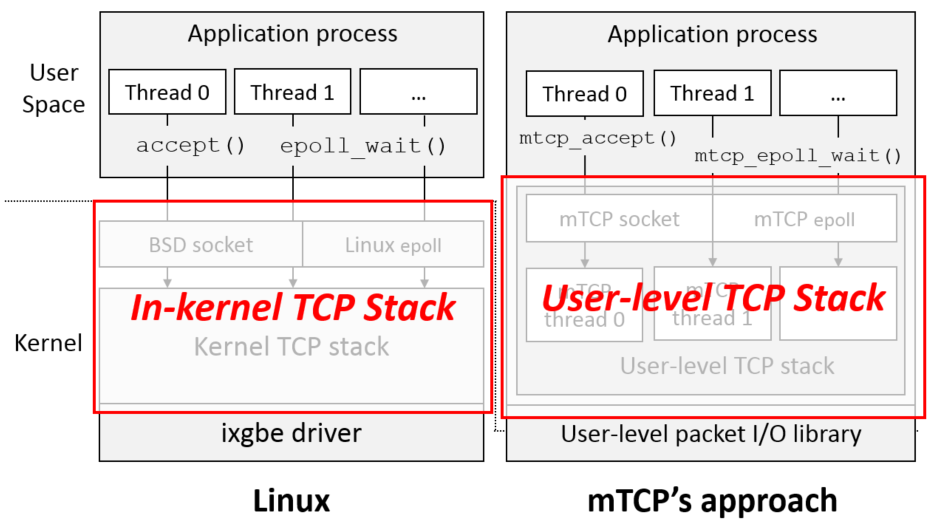
基本设计
mTCP主要有两个部分组成,用户态的包处理库和用户态的TCP协议栈。引用的每一个处理线程占用一个CPU核心,线程是通过使用用户态的包处理库直接从网卡放送和接收数据包。由于硬件的限制,这里支持一个一个应用一个网卡端口,这里将来可以用虚拟化解决(实际上后面的几个研究就是基于虚拟化硬件的)。
User-level Packet I/O Library
mTCP使用一个叫做PacketShader I/O(PSIO)(后面会有一篇来专门说说这一个PSIO库),库来实现事件驱动的包处理接口,PSIO通过使用RSS等技术来实现将包分发到对用的流里面,提供流级别的CPU核心亲和性,这样各自处理各自的包就减少了很多竞争。PSIO提供了ps_select() 这样的事件驱动接口,使用的方式和select()syscall相似,不够它操作的是网卡上发送、接收队列上面处理的数据包。
mTCP specifies the interested NIC interfaces for RX and/or TX events with a timeout in microseconds, and ps_select() returns immediately if any event of interest is available. If such an event is not detected, it enables the interrupts for the RX and/or TX queues and yields the thread context. Eventually, the interrupt handler in the driver wakes up the thread if an I/O event becomes available or the timeout expires.
PSIO也给mTCP提供了平摊系统调用和上下文切换开销的机会,在PSIO中包的处理都是批量的,这样就平摊来很多传输的开销。
User-level TCP Stack
用户态的协议栈是的消除了很多应用必须经过Liunx内核处理包带来的开销。在线程模型上面,使用的是一个TCP线程对应一个应用线程,这两个线程时分开的(separate-TCP-thread-per-application-thread model)。应用线程通过关系的buffer和mTCP的TCP线程进行交会,访问这些buffer都是通过mTCP提供的API进行的。这里将不将mTCP线程和应用线程合并为一个线程处理主要就是因为TCP的处理是很依赖时间上的准确性的,比如TCP的超时重传等,如果线程阻塞在应用的代码中的话,TCP逻辑的部分就可能出现不正确的行为,所以,这里只能将其分开。
However, the fundamental limitation of this approach is that the correctness of internal TCP processing depends on the timely invocation of TCP functions from the application.
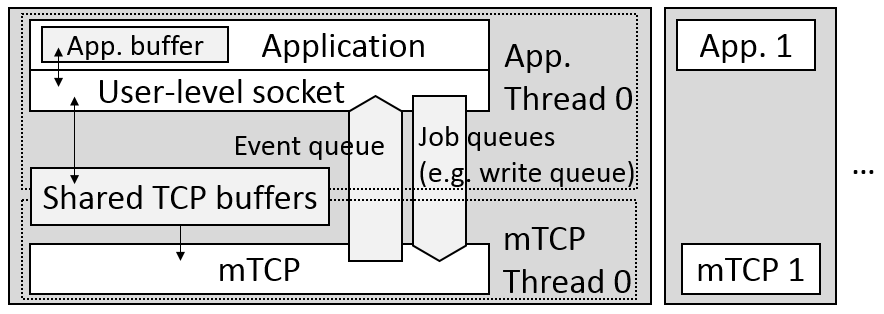
上面的TCP线程和应用线程交换的方式也带来了额外的overhead,比如并发数据结构以及线程的上下文切换。为了解决这些问题,mTCP使用了以下的解决办法:
Lock-free, Per-core Data Structures
对于mTCP线程直接来说,数据结构都是每一个线程有自己的一份,所以不会产生竞争的为你。对于应用线程和mTCP线程之间的交互,这里使用了精心设计的lock free的数据结构。此外,这些数据结构的设计充分考虑到了现在CPU的特点,特别是针对缓存做了很多优化,
In addition, we keep the size of frequently accessed data structures small to maximize the benefit of the CPU cache, and make them aligned with the size of a CPU cache line to prevent any false sharing.
不过这些没有什么特别的,设计的比较好的系统都会使用类似的方法,Linux内核中这样的套路非常常见。此外,mTCP线程和应用线程会被放在相同的CPU核心上运行,加上使用RSS等的技术,实现了流级别的CPU亲和性。
Batched Event Handling
这里可以分析,虽然将mTCP线程和应用线程能带来一些好处,带来的一个问题就是mTCP线程和应用线程之间争用CPU核心。批量处理处理可以平摊overhead之外,也可以缓解这个问题。和其它的一些系统和MegaPipe一样,这里的批量处理也是透明的,有mTCP自己处理,应用就像正常一样使用即可,
the mTCP library transparently batches the write events into a write queue. While the idea of amortizing the system call overhead using batches is not new, we demonstrate that benefits similar to that of batched syscalls can be effectively achieved in user-level TCP.
处理流程
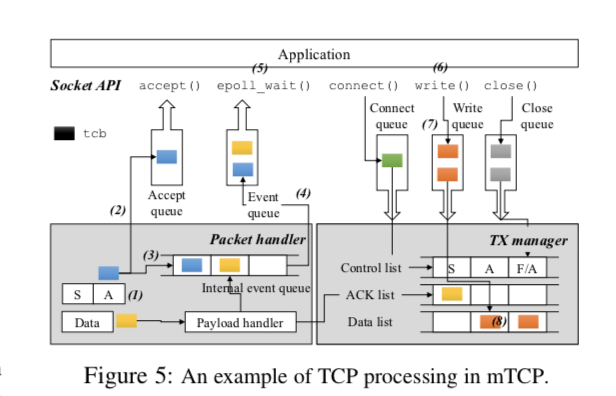
- mTCP从网卡的接收队列只能够批量取回数据包,对于每一个包,先在hash table中查找(or 创建,如果之前没有的话)对于流的TCP控制块(tcb)。如果服务器发收到了一个对其SYN/ACK包 的ACK,那么对个代表了新的连接的tcb将会进入aceept queue,然后会对应用的listening socket产生一个读的事件;
- 对于新来的数据包,拷贝其中的payload到socket的读缓冲中,如何发出在内部的事件队列中撒入一个事件。此外,会对其产生一个ACK的包。
- 当结束到一批这样的包时,mTCP将这些事件刷到应用的事件队列中,然后唤醒应用的线程;
- 应用线程使用event loop的方式处理这些数据;
- 应用在处理了这些数据之后,写会响应。这里只是写到buffer里面,不会引起上下文的切换,同时会在写入队列中加入tcb,用于下一步的处理;
- 然后,mTCP收集这些tcbs,批量地传输这些里面需要传输的数据;
实现
为了保证对最大的对现在的API的兼容性,mTCP的接口和现在的socket, epoll之类的接口非常相似,应用可以容易地就迁移到mTCP上面。虽然它们很相似,当时并不是完全兼容的。
We provide a BSD-like socket interface; for each BSD socket function, we have a corresponding function call (e.g., accept() becomes mtcp_accept()). I
...
Applications can fetch the events through mtcp_epoll_wait() and register events through mtcp_epoll_ctl(), which correspond to epoll_wait() and epoll_ctl() in Linux. Our current mtcp_epoll() implementation supports events from mTCP sockets (in- cluding listening sockets) and pipes.

从这个使用mTCP的mtcp_epoll一段代码可以看出,这里的使用方法和Linux的epoll接口时很相似的。
评估
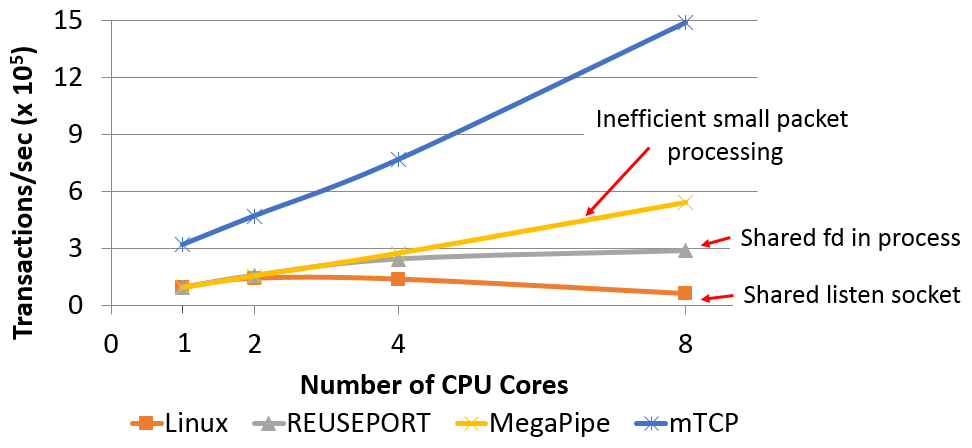
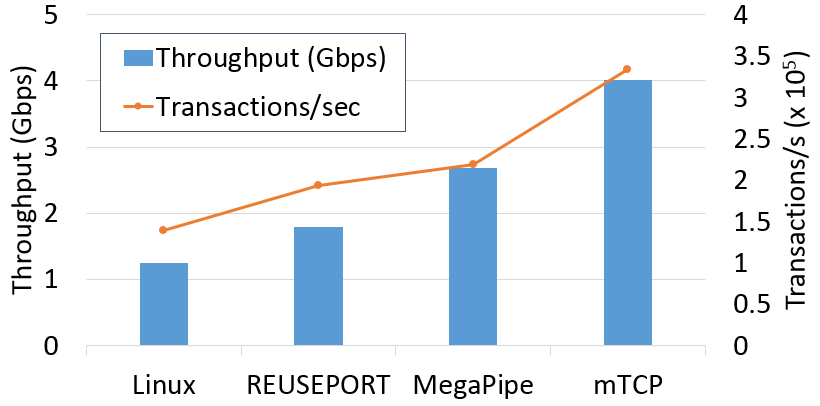
mTCP对小消息有着非常好的性能:
在lighttpd上面的测试结果也非常优秀:
参考
- mTCP: A Highly Scalable User-level TCP Stack for Multicore Systems, NSDI’14.
- MegaPipe: A New Programming Interface for Scalable Network I/O, OSDI 2012.
- Improving Network Connection Locality on Multicore Systems, EuroSys’12.
- http://shader.kaist.edu/mtcp/, website of mTCP.
