netmap: a novel framework for fast packet I/O
引言
netmap是一个非常优秀的使用内核旁路的包处理的框架,可以在900MHz的一个CPU Core上面实现14.88 Mpps的处理速度。在这篇Paper中的数据指出可以在平摊地70cyles左右就处理一个数据包。
netmap has been implemented in FreeBSD and Linux for several 1 and 10 Gbit/s network adapters. In our prototype, a single core running at 900 MHz can send or receive 14.88 Mpps (the peak packet rate on 10 Gbit/s links). This is more than 20 times faster than conven- tional APIs. Large speedups (5x and more) are also achieved on user-space Click and other packet forward- ing applications using a libpcap emulation library running on top of netmap.
基本思路
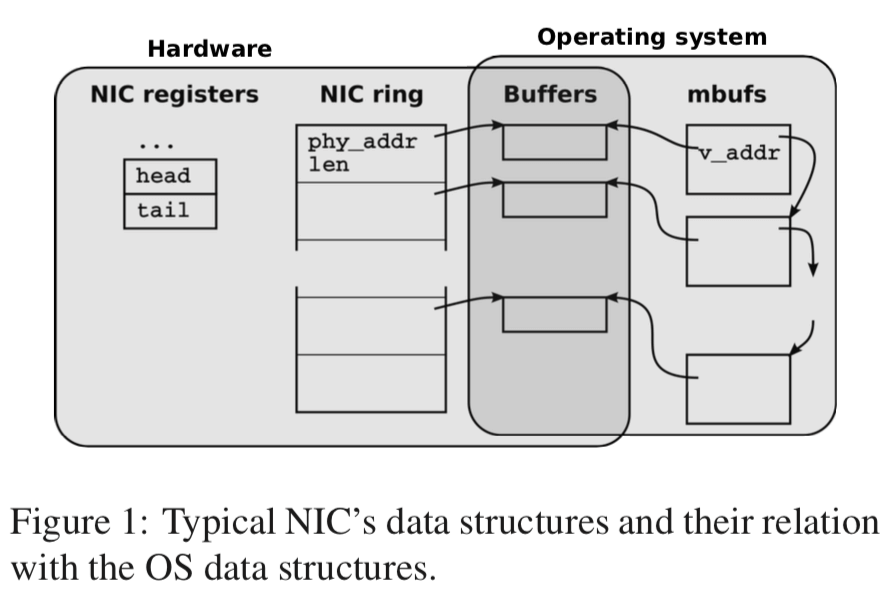
下面的图是一般的内核处理网络数据包的架构。网卡对发送的数据包和接受的数据包都使用一个环形的队列,队列里面的元素就是buffer的信息,包含了物理地址和长度等的信息。网卡处理接收的数据包是,它会选择在接收的这个ring queue下一个可用的buffer,在数据保存之后,改写这个slot里面的数据长度,状态等信息,然后使用中断来通知CPU处理这些数据。发送的时候,则是OS将这些buffer填充数据,然后通过OS对NIC registers进行操作来通知网卡来处理这些数据。在包到达的速率非常高的情况下,中断会给数据的处理造成很大的负担。目前的一些解决的办法就是使用轮询,或者是将这些工作分配到各个CPU核心之上。
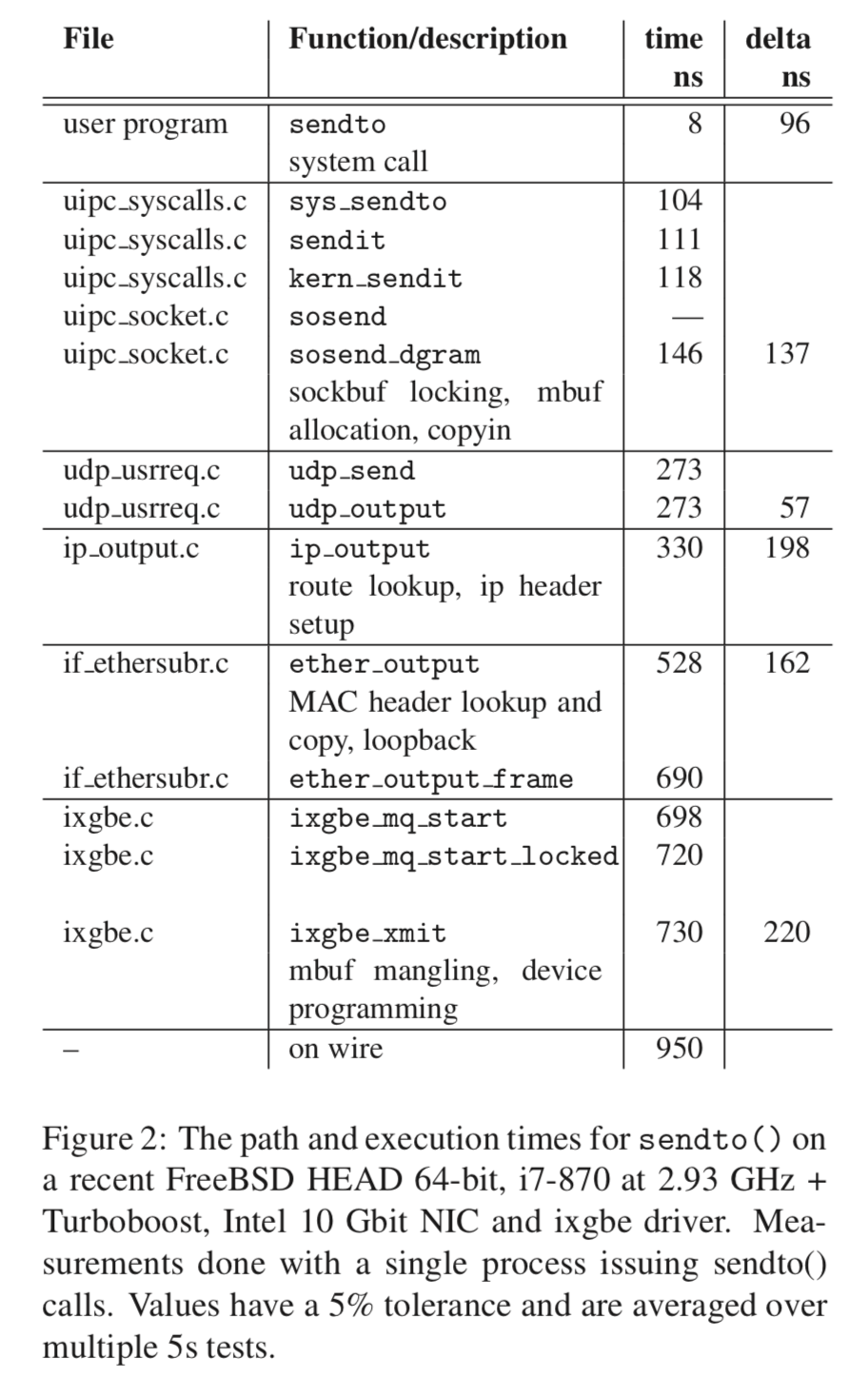
下面的图显示了FreeBSD内核在处理数据包的时候的时间消耗:
netmap向前面的mTCP一样,也是将工作移到user-space来处理,主要的目的在消除or减少数据复制,元数据管理和系统调用带来的开销。这里不想mTCP是一个完整的TCP协议的实现,这里的netmap只是一个包处理的框架。netmap实现高性能主要源于使用了一下的技术:
- 轻量级的包的元数据,易于使用,隐藏了设备的具体信息。还支持在一个syscall中处理多个包,用于平坦开销;
- 预先分配的固定大小的包buffer,避免的buffer分配、回收的开销;
- 应用可以直接安全地访问包buffer,避免了数据复制。这里同样地机制可以用来实现接口之间的zero-copy;
- 支持多队列网卡等的技术。
程序要使用netmap的功能是,要先让一个网络接口进入netmap的模式,这里可以就是一个网卡的一个接受队列。在设置了之后,在这里接收到的数据包就会不交给kernel的网络栈来处理,而是会被放到一个基于共享内存的netmap rings`的结构中,这个实际上也是一个环形队列。这里在设置了netmap的模式之后,可以使用常见的select/poll系统调用来处理,下面是一个netmap的例子:
fds.fd = open("/dev/netmap", O_RDWR);
strcpy(nmr.nm_name, "ix0");
ioctl(fds.fd, NIOCREG, &nmr);
p = mmap(0, nmr.memsize, fds.fd);
nifp = NETMAP_IF(p, nmr.offset);
fds.events = POLLOUT;
for (;;) {
poll(fds, 1, -1);
for (r = 0; r < nmr.num_queues; r++) {
ring = NETMAP_TXRING(nifp, r);
while (ring->avail-- > 0) {
i = ring->cur;
buf = NETMAP_BUF(ring, ring->slot[i].buf_index);
// ... store the payload into buf ...
// ring->slot[i].len = ... // set packet length ring->cur = NETMAP_NEXT(ring, i);
}
}
}
Data structures
下面的图就基本上显示了netmap使用的数据结构,
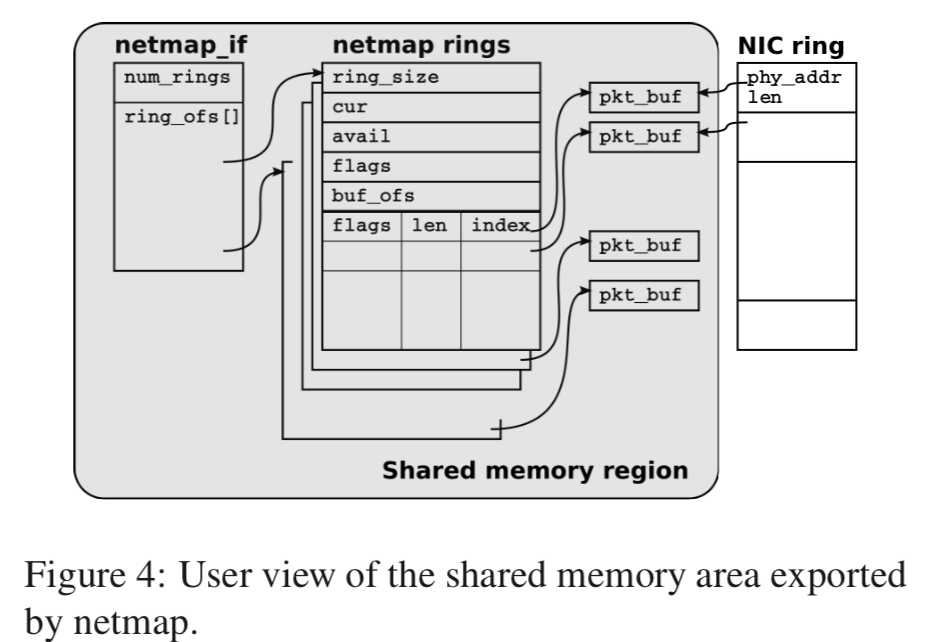
对于每一个网络接口,都维持了以上的结果,这里主要就是三个:packet buffers,netmap rings和 netmap_if。弄清楚这些结构的用途和工作方式基本就明白了netmap的原理。所有的这些结构都保存在一个内存区域内,这里的内存区域由kernel分配在一个不可分页的区域。而且这些所有的进程和网络接口都是用这些分配的内存(这里改成不使用相同的也是很简单的)。这里单个区域的设计有利于不同的网络接口之间的数据转发(很显然的,这里这样就可以避免数据拷贝了)。这些共享内存有mmap之类的API映射到用户进程之中,在kernel的线程和用户进程看到的虚拟地址是不同的,也是有这个原因,引用这里里面的数据的时候要使用相对的地址,即相对于一个基地址的偏移值。
-
Packet buffers,每一个buffer有固定的大小,这里默认是2KB,由网卡和用户进程贡献,每一个buffer有一个唯一的index,很方便的用于地址的转换(用户进程的地址,kernel的地址和NIC用的物理的地址),这里的这些buffer都是预先分配的,使用的时候直接使用。每一个buffer还有相关的元数据,
The metadata describing the buffer (index, data length, some flags) are stored into slots that are part of the netmap rings. Each buffer is referenced by a netmap ring and by the corresponding hardware ring. -
netmap ring,一个netmap ring 是一个与设备无关的由 NIC 实现的循环队列的副本。包括了一下的信息,
• ring size, the number of slots in the ring; • cur, the current read or write position in the ring; • avail, the number of available buffers (received packets in RX rings, empty slots in TX rings); • buf ofs, the offset between the ring and the begin- ning of the array of (fixed-size) packet buffers; • slots[], an array with ring size entries. Each slot contains the index of the corresponding packet buffer, the length of the packet, and some flags used to request special operations on the buffer. -
netmap_if,这里的数据是只读的,包含的就网络接口的相关信息(if -> interface),比如rings的数量,还有就是前面说到的由于寻找的偏移量的信息。
a netmap if contains read-only information describing the interface, such as the number of rings and an array with the memory offsets between the netmap if and each netmap ring associated to the interface (once again, offsets are used to make addressing position- independent).这里的netmap ring除了在系统调用的期间,它的所有权总是属于用户进程的,用户操作这些结构和kernel里面操作这些结构总是在不同的时间,所以不会有data race的问题。cur到cur+avail-1表示这里已经保存了处理,属于用户进程来处理,其余的就是kernel来处理。这里关于netmap API的部分可以参看论文的4.2节。从这里就可以看出里netmap的基本思路就是使用共享内存使得用户进程可以安全的范围网络接收到的数据,从而实现在用户空间内的包处理。
评估
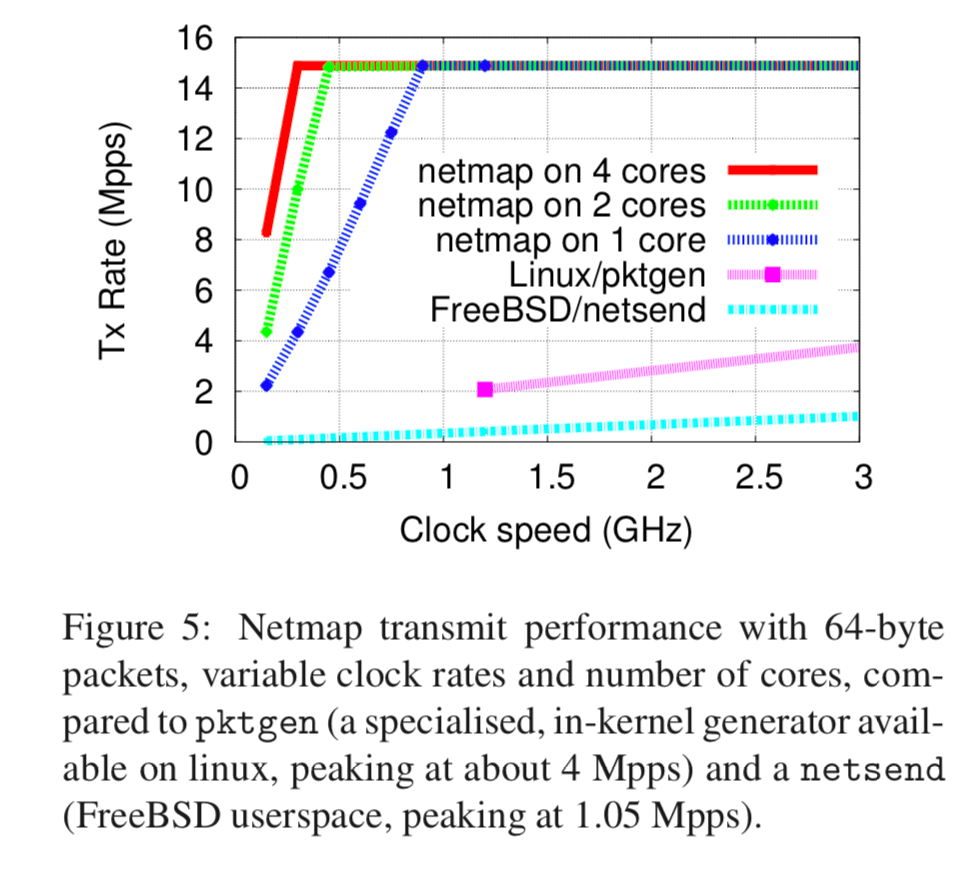
参考
- netmap: a novel framework for fast packet I/O,
