MICA: A Holistic Approach to Fast In-Memory Key-Value Storage
0x00 引言
这篇paper是关于KVS里面一篇非常好的文章。个人觉得里面很多东西都设计的很赞。此外,作者还有一篇指导如何设计一个QPS 为Billion基本的论文[2],也很值得一看(不过好像里面做的并没有实际到达1billion,倒是SOSP 2017 上的一篇文章到达了[3],之后加上这篇论文的blog)。MICA一个目的就是旨在解决之前类似系统只为read-mostly场景设计,希望能适应各种各样的场景,并提供很好的性能:
Under write-intensive workloads with a skewed key popularity, a single MICA node serves 70.4 million small key-value items per second (Mops), which is 10.8x faster than the next fastest system. For skewed, read-intensive workloads, MICA’s 65.6 Mops is at least 4x faster than other systems even after modifying them to use our kernel bypass. MICA achieves 75.5–76.9 Mops under workloads with a uniform key popularity.
0x01 采用的技术和目标
MICA主要使用了一下的一些技术来达到设计目标:
-
Fast and scalable parallel data access,同时使用数据分区和开发cores之间的并行性来提高数据范围的性能。MICA使用了2中模式:
Its EREW mode (Exclusive Read Exclusive Write) minimizes costly inter-core communication, and its CREW mode (Concurrent Read Exclusive Write) allows multiple cores to serve popular data. -
Network stack for efficient request processing,MICA使用bypass kernel的网络栈来提高性能。
-
New data structures for key-value storage,使用新的内存分配方法和indexing,分别为存储和缓存优化。
MICA的具体目标和一些类似的系统没有多大的区别:
- High single-node throughput;
- Low end-to-end latency ;
- Consistent performance across workloads;
- Handle small, variable-length key-value items;
- Key-value storage interface and semantics;
- Commodity hardware;
简而言之就是高吞吐,低延时,稳定的性能表现,兼容性良好的借口,无需特殊硬件。
0x02 MICA Design
Parallel Data Access
MICA使用了基于Keyhash的数据分区方式。这样分区可能造成的问题就是在数据范围严重倾斜的情况下可能导致的系统inblance。一个缓解这个情况的原因是热点数据被频繁访问,这样的话这些数据在cache中的可能性就比较高。此外MICA还使用了一些别的解决办法,之后会提到。
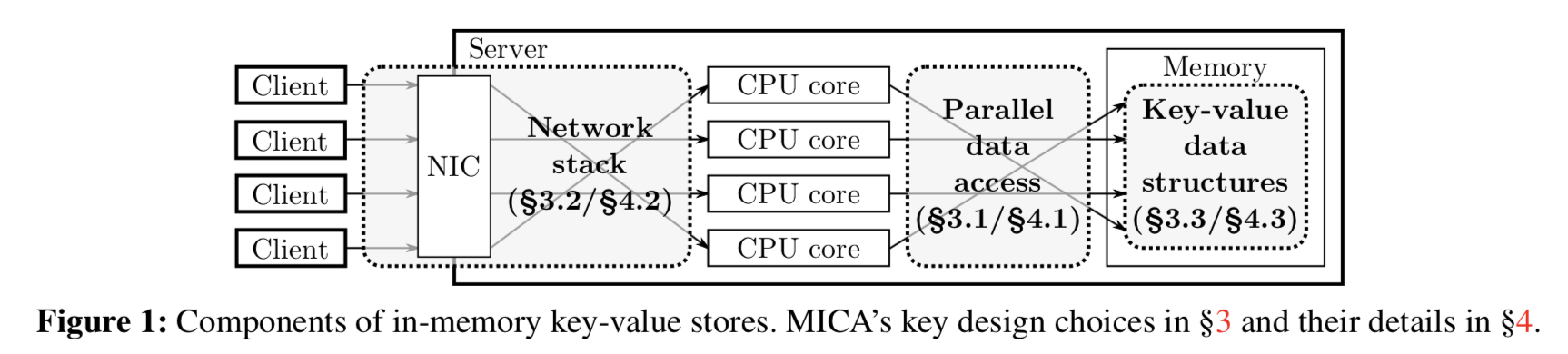
主要的情况下,MICA只会有一个线程访问本线程的partition(Exclusive Read Exclusive Write),这样可以去除core间通信的成本,避免巨大的同步开销。而在数据访问严重倾斜的情况下,可以使用Concurrent Read Exclusive Write的访问方式。MICA会总是避免concurrent write。
CREW allows any core to read partitions, but only a single core can write. This combines the benefit of concurrent read and exclusive write; the former allows all cores to process read requests, while the latter still reduces expensive cache line transfer. CREW handles reads efficiently under highly skewed load, at the cost of managing read-write conflicts.
Network Stack
Network I/O 是现在KVS中最昂贵的操作,在一些KVS中,TCP的处理消耗刘大约70%的时间。由于内存的key-value大多的时候的key value对象都比较小,这里MICA使用了UDP而不是TCP来提高性能。此外,MICA使用了DPDK加快网络传输处理。利用DPDK的Burst packet I/O来平摊packet的处理成本,使用Zero-copy processing 避免不必要的内存分配和加快数据处理。
Client-Assisted Hardware Request Direction
现在的NIC支持 RSS和FDir 来讲packets分配到不同的core上,但是这个不能根据packet的内容来决定分配到哪一个core。所以MICA使用了一种client和server协作的方法,client缓存了server的一些信息,如operation mode,core的数量,NUMA,网卡和分区等的信息。利用这些信息计算出分区or core index,将其作为UDP数据包的目的端口。server使用FDir机制使用destination port,这个port被映射到一个RX queue,这样包就被传输到了正确的分区。
The client then embeds the request direction information in the packet header: If the request uses exclusive data access (read/write on EREW and write on CREW), the client calculates the partition index from the keyhash of the request. If the request can be handled by any core (a CREW read), it picks a server core index in a round-robin way (across requests, but in the same NUMA domain (Section 4.2.1)). Finally, the client encodes the partition or core index as the UDP destination port.
Data Structure
Circular Log
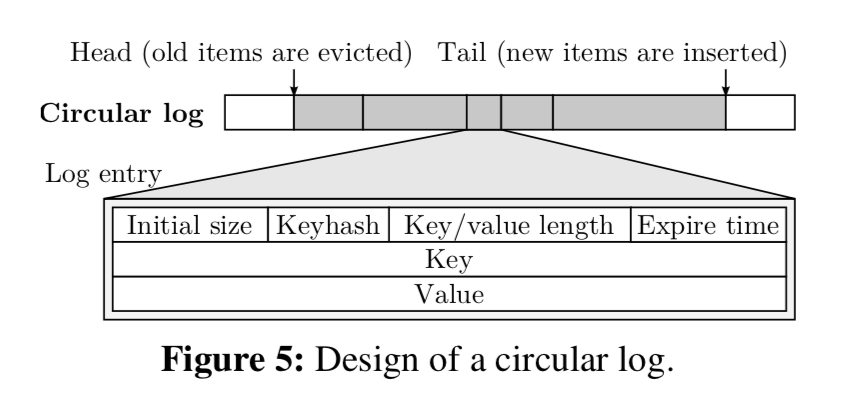
MICA使用的内存分配方式不同与Log-Structure 和malloc 的方式。新添加的数据项被直接添加到log的后面,这点与Log-Structure是相同的,更新的时候,只要新的数据大小不超过原来的大小,就是就地更新,这点上与Log-Structure不同。Circular Log的大小是固定的,使用log满的时候就会驱除最老的数据项来获取内存空间。此外,MICA还使用了hugepages 和 NUMA-aware的分配方法。
Without explicit range checking, accessing an entry near the end of the log (e.g., at 234 − 8 in the example below) could cause an invalid read or segmentation fault by reading off the end of the range. To avoid such errors without range checking, MICA manually maps the virtual memory addresses right after the end of the log to the same physical page as the first page of the log, making the entire log appear locally contiguous: Our MICA prototype implements this scheme in userspace by mapping a pool of hugepages to virtual addresses using the mmap() system call.
Lossy Concurrent Hash Index
MICA 的index的设计和MemC3的设计有很多相似的地方,这里就只看看它不同的地方了:
-
为了加快insert操作的速度,一个key-value结构插入到一个满了的bucket的时候,与MemC3不相同的是它不使用类似cuckoo hash的方式,而是直接根据数据项的年龄来进行回收操作。
-
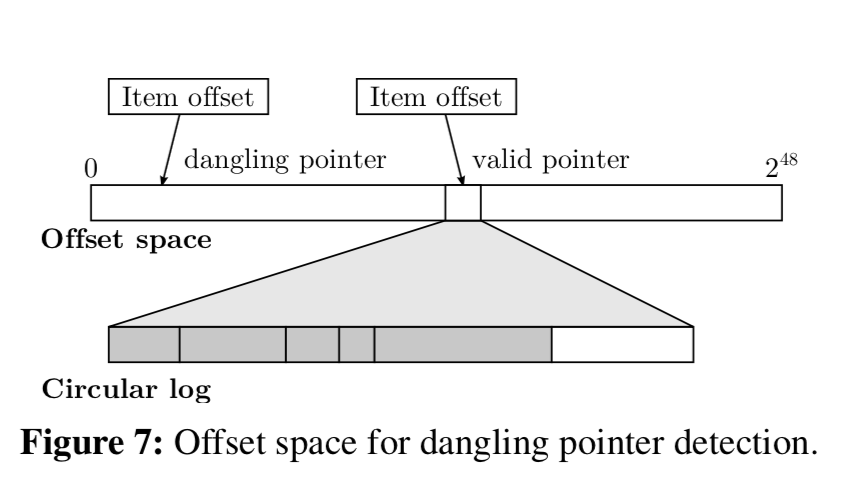
当一个数据项从log中删除的时候,它的index项并没有删除,这样可能造成数据访问的问题。MICA解决这个问题的方式是:
To address this problem, MICA uses large pointers for head/tail and item offsets. As depicted in Figure 7, MICA’s index stores log offsets that are wider than needed to address the full size of the log (e.g., 48-bit offsets vs 34 bits for a 16 GiB log). MICA detects a dangling pointer before using it by checking if the difference between the log tail and the item offset is larger than the actual log size.5 If the tail wraps around the 48-bit size, however, a dangling pointer may appear valid again, so MICA scans the index incrementally to remove stale pointers.
其它
MICA具体使用的优化方法很多,这里只说了其中几个,想详细研究的话看看[1],[2].
0x03 评估
这咯具体信息可以参看[1],吊打其它系统的表现(MICA-c MICA-s性能几乎一样)。
参考
- MICA: A Holistic Approach to Fast In-Memory Key-Value Storage, NSDI‘14.
- Full-Stack Architecting to Achieve a Billion-Requests-Per-Second Throughput on a Single Key-Value Store Server Platform, TOCS 2016.
- KV-Direct: High-Performance In-Memory Key-Value Store with Programmable NIC, SOSP 2017.
