The IX Operating System: Combining Low Latency, High Throughput, and Efficiency in a Protected Dataplane
引言
IX和Arrakis都是OSDI 2014上关于利用硬件虚拟化来提供系统IO性能的论文。IX和Arrakis在很多地方是相似的,比如Data Plane和Control Plane分离,比如使用虚拟化和硬件交互,比如都是用用户空间的网络栈等等。此外,IX实现基于之前的Dune Framework,一个利用虚拟化安全保留硬件功能的框架。IX的设计基于以下几个原则:
- Separation and protection of control and data plane,
- Run to completion with adaptive batching,
- Native, zero-copy API with explicit flow control,
- Flow-consistent, synchronization-free processing,
- TCP-friendly flow group migration,
- Dynamic control loop with user-defined policies。
基本设计
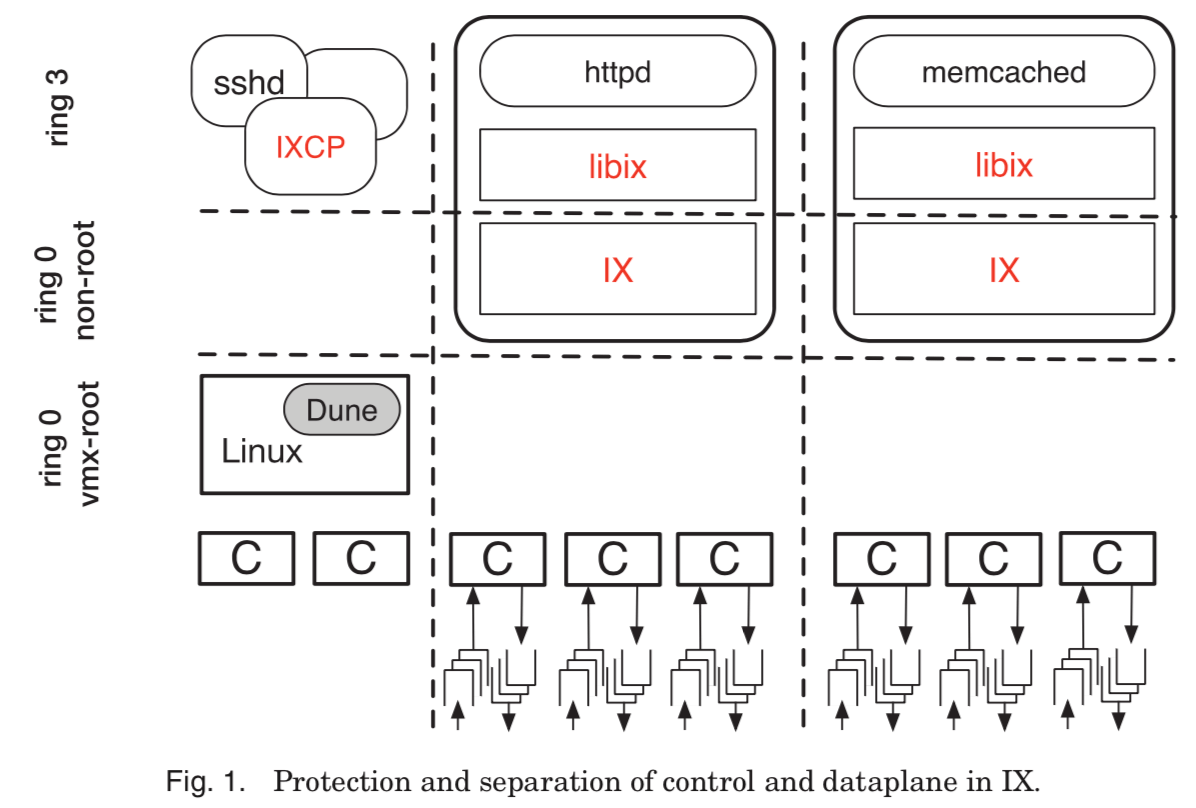
IX主要分为了3个部分,一个是运行在Linux内核里面的Dune模块,具体可以参考论文[2],IX的data planes可以看作是一个特殊的OS(application-specific OSs),运行在non-root的ring 0态中,最后的应用使用了libix的库,运行在ring 3中。这样的方式提供了一个安全的有效的直接访问硬件功能的方式。
This approach provides dataplanes with direct access to hardware features, such as page tables and exceptions, and passthrough access to NICs. Moreover, it provides full, three-way protection between the control plane, dataplanes, and untrusted application code.
IX的control plane由Linux内核和一个用心在用户态IXCP程序组成,Linux提供资源管理与分配等的功能,提供基本的系统接口,IXCP负责监控资源使用情况、dataplane的性能状况、以及实现资源的分配策略。每一个IX dataplane的实例支持运行一个多线程的应用程序,可以看作是一个单一地址空间的特殊OS。在这里面有两种类型的线程,一是elastic threads负责与dataplane交互,处理网络IO,二是background threads。elastic threads不掉用可能导致阻塞的接口。为了实现高性能和可预测的延时,每一个elastic thread都独享一个硬件线程,而多个background threads可能共享一个硬件线程。
For example, if an application were allocated four hardware threads, it could use all of them as elastic threads to serve external requests or it could temporarily transition to three elastic threads and use one background thread to execute tasks such as garbage collection. When the control plane revokes or allocates an additional hardware thread using a protocol similar to the one in Exokernel, the dataplane adjusts its number of elastic threads.
IX Dataplane
Dataplane管理着自己的虚拟地址空间,这个地址空间是单一的,同时使用大的内存页来提到TLB的性能,不支持swap。为了提高内存分配的性能,接受一定的internal memory fragmentation(内部碎片),hot-path的数据对象都是从per-thread一个的内存池中分配的,内存池分配固定的特定大小的对象,同时为网络传输的特点做了优化,比如考虑到MTU的大小。
Each memory pool is structured as arrays of identically sized objects, provisioned in page-sized blocks. Free objects are tracked with a simple free list, and allocation routines are inlined directly into calling functions. Mbufs, the storage object for network packets, are stored as contiguous chunks of bookkeeping data and MTU-sized buffers, and are used for both receiving and transmitting packets.
Dataplane提供的一些API:
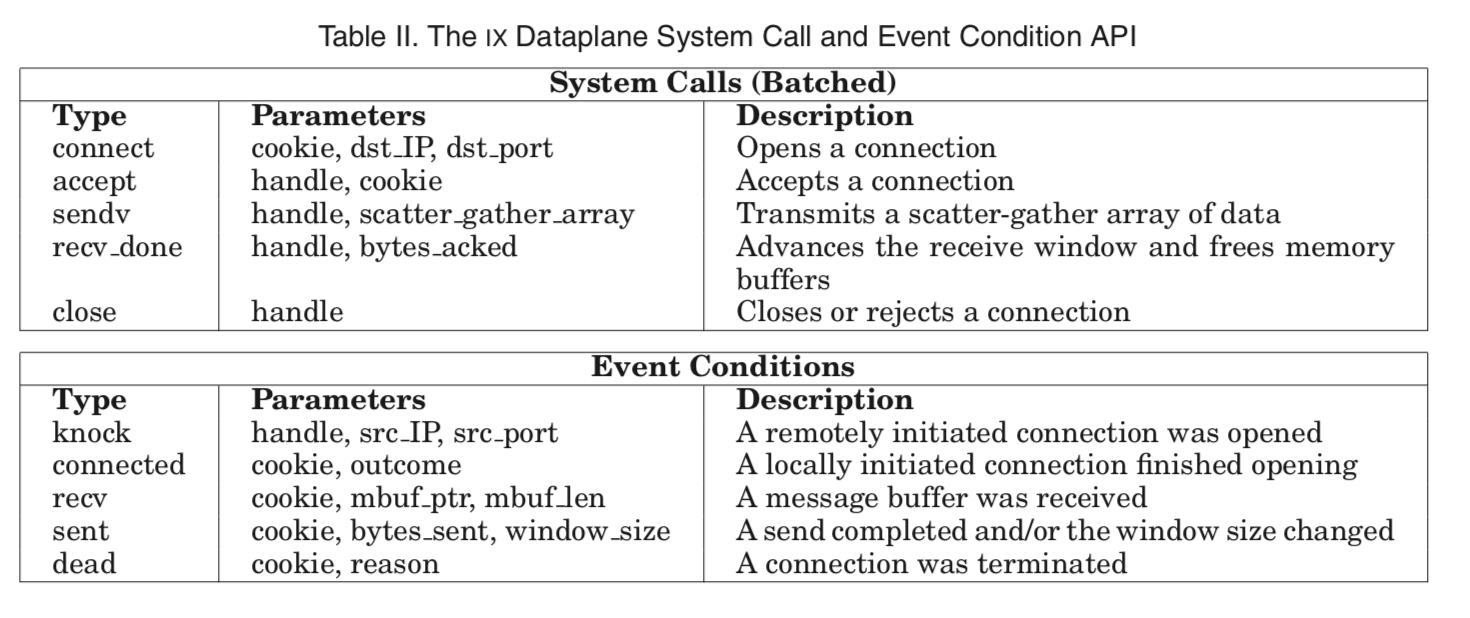
Elastic threads使用了3中异步非阻塞的机制和dataplane交互:
- 向dataplane发出批量的 system calls;
- 消费由dataplane产生的event conditions;
- 可以直接安全地分为保护内接收的数据包的mbufs。这是为了提供zero copy的api。
Batched system calls和event conditions都是使用由共享内存的,这样提高性能。
IX provides an unbatched system call (run_io) that yields control to the kernel and initiates a new run-to-completion cycle. As part of the cycle, the kernel overwrites the array of batched system call requests with corresponding return codes and populates the array of event conditions. The handles defined in Table II are kernel-level flow identifiers. Each handle is associated with a cookie, an opaque value provided by the user at connection establishment to enable efficient user-level state lookup.
IX在user-level提供的是libix的库,对底层的api做了封装,它提高了非常类似libevent的api和非阻塞的Posix的socket的操作(没有说这里是完全兼容的),此外还提供了zero copy的API提高性能(这里和Arrakis很相似)。libix会自动合并多个写请求来实现批量处理(MegaPipe里面类似的操作)。
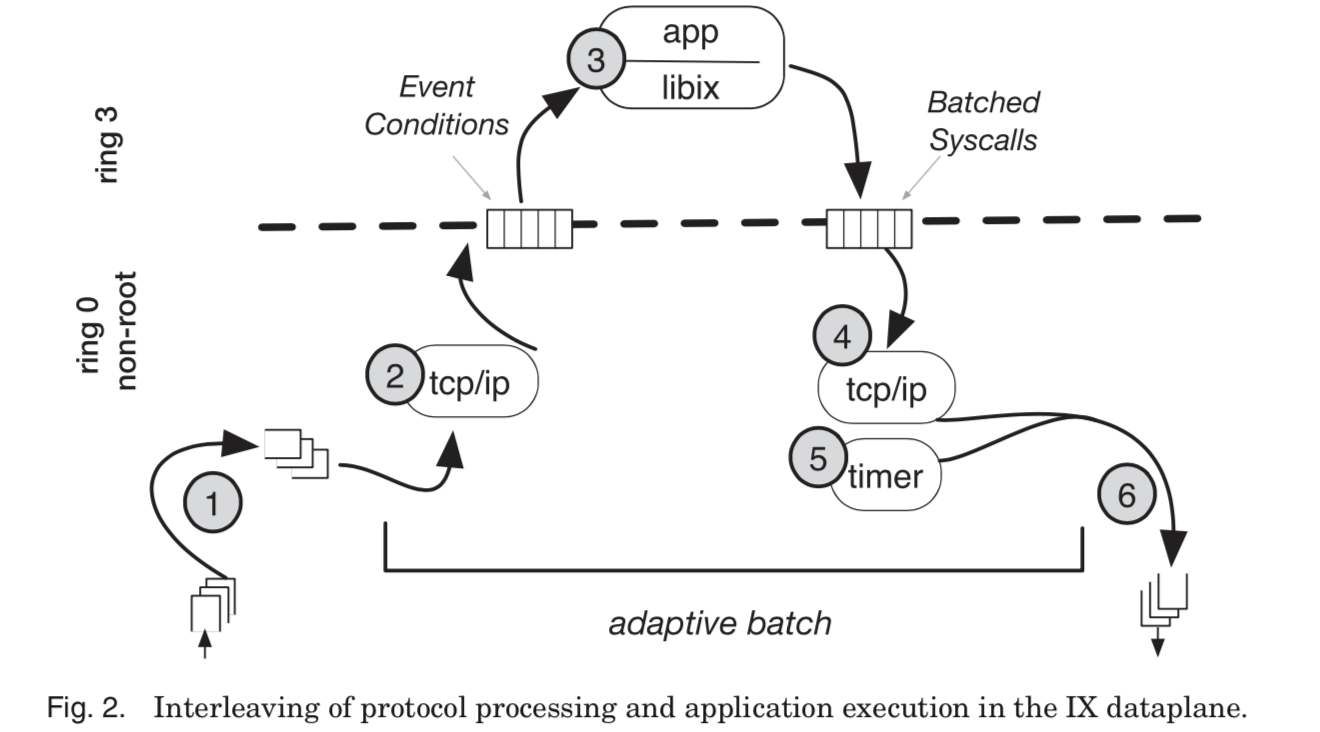
上面的图很好地体现了IX的数据包的处理过程,
- elastic thread轮询接收这一方descriptor ring,在这个过程中可能添加新的buffer用于容纳可能的以后接收的数据包;
- elastic thread然后处理一定数量的数据包,这里的网络栈是由lwIP更改而来的。网络栈在处理了这些数据包之后,产生event conditions;
- 线程切换到用户空间,消费这些数据。然后通过batched system calls回复;
- 在用户空间返回之后,线程处理这些batched system calls;
- 对于发送出去的数据,要有对应的处理方法,比如TCP就有注意设置定时器等的问题;
- 然后将发送出去的以太网帧放置到网卡的传送的descriptor ring,然后通知网卡启动传输。
这里面的操作过程中使用了各种办法来避免内存拷贝。
Multicore Scalability & Flow Group Migration
IX通过以下几点来实现多核的可拓展性,
-
IX的API在elastic threads之间都是可交换的,每一个elastic thread都有自己的流命名空间,不能访问直接其它线程的的流命名空间。(关于可交换的可以参考The Scalable Commutativity Rule这篇论文[3]).
-
每一个elastic thread管理自己的内存池,硬件队列,event condition数组,和batched system calls数组.
The implementation of event conditions and batched system calls benefits directly from the explicit, cooperative control transfers between IX and the application. Since there is no concurrent execution by producer and consumer, event conditions and batched system calls are implemented without synchronization primitives based on atomics. -
IX使用网卡的flow-consistent hashing功能来保证elastic thread是处理的不同的数据流,所以处理接收的数据就避免了很对同步之类的操作。对于应用发送出去的数据包,由于不能逆向使用RSS,这里使用的就是端口范围区分的方法。
Since we cannot reverse the Toeplitz hash used by RSS, we simply probe the ephemeral port range to find a port number that would lead to the desired behavior. Note that this implies that two elastic threads in a client cannot share a flow to a server.
对于添加和移除一个线程时,control plane的IXCP就会产生流迁移的请求,具体可参看论文。
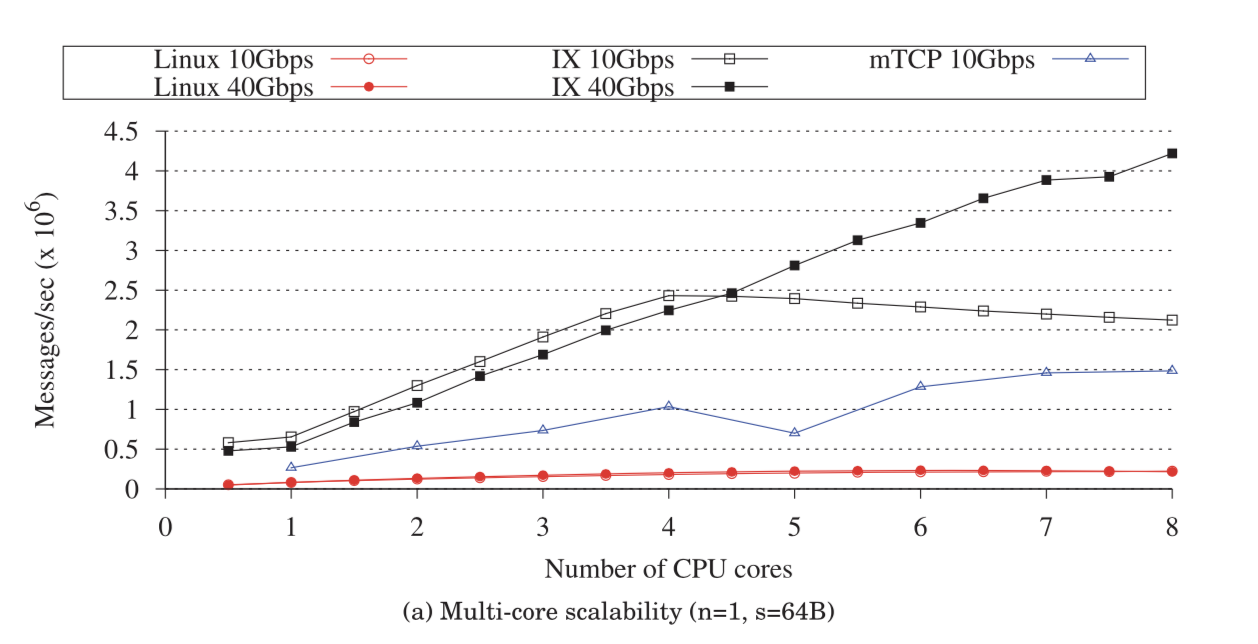
Evaluation
参考
-
Adam Belay, George Prekas, Mia Primorac, Ana Klimovic, Samuel Grossman, Christos Kozyrakis, and Edouard Bugnion. 2016. The IX operating system: Combining low latency, high throughput, and efficiency in a protected dataplane. ACM Trans. Comput. Syst. 34, 4, Article 11 (December 2016), 39 pages. DOI: http://dx.doi.org/10.1145/2997641 .
-
Dune: Safe User-level Access to Privileged CPU Features, OSDI 2012.
-
Austin T. Clements, M. Frans Kaashoek, Nickolai Zeldovich, Robert T. Morris, and Eddie Kohler. 2015. The scalable commutativity rule: Designing scalable software for multicore processors. ACM Trans. Comput. Syst. 32, 4, Article 10 (January 2015), 47 pages. DOI: http://dx.doi.org/10.1145/2699681.
