ZygOS: Achieving Low Tail Latency for Microsecond-scale Networked Tasks
0x00 引言
这篇Paper时前面的Dune Framework和IX的后续,主要是为了解决在多核系统下面的非常细粒度的网络任务的调度问题,
We evaluate ZYGOS with a networked version of Silo, a state-of-the-art in-memory transactional database, running TPC-C. For a service-level objective of 1000μs latency at the 99th percentile, ZYGOS can deliver a 1.63× speedup over Linux (because of its dataplane architecture) and a 1.26× speedup over IX, a state-of-the-art dataplane (because of its work-conserving scheduler).
0x01 背景和问题
IX是利用硬件虚拟化以及其它的一些技术。在IX中也存在一些问题,sync-free的控制面的设计要求每个线程只能处理它直接相关的网卡硬件(网卡队列?)。如何负载都分配均衡的话这个不会是什么问题。但是还是存在这样的一些情况导致系统负载不均衡的情况:1. 长时间的负载不均衡的现象出现在在一段较长的时间内一个网卡队列达到的数据包的速率不相等,这样很显然会导致一些CPU核心的负载就高于其它的。前面看过的一些KVS的系统MICA就采用了CREW机制来解决这样的一些问题;2. 短暂性的不均衡,在一个短时间内达到一个网卡队列的包突然增加;3. 不同的请求需要处理的时间不相同,一个线程可能遇上了需要较长时间处理的请求,导致了不平衡的现象。
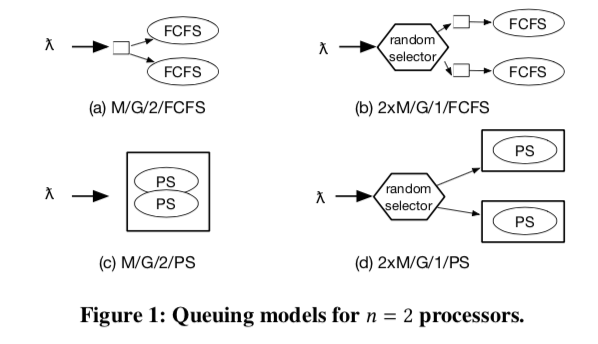
为了解决这样的问题,ZygOS试图在IX的基础上去加上一些调度,解决存在的负载均衡的问题,还有就是可以有哈low-tail的问题(tail-tolerance)。在进行具体的细节设计之前,ZygOS先提出4中模型,是两个方面个2种方式的组合(2*2=4)。Paper中使用A/S/n/K记号的表示方式。A代表任务达到的间隔的分布,S表示一个任务服务时间的分布,n表示worker的数量,K表示使用策略。这里就假达到间隔的分布服从泊松分布。K代表的策略可以是 first-come-first-serve (FCFS) o或者是processor sharing (PS),即是全局一个队列还是每个Core(or Thread)一个队列。这样就出现了Paper中比较4中方案,
* The centralized-FCFS model (formally M/G/n/FCFS),idealizes event-driven applications that process events from a single queue or that float connections across cores (e.g., using the epoll exclusive flag).
* The partitioned-FCFS model (formally n×M/G/1/FCFS),idealizes event-driven applications that partition connections among cores (e.g., libevent-based applications) and associate each core with its own private work queue.
* M/G/n/PS idealizes the thread-oriented pattern (1 thread per connection) deployed on time-sharing operating systems.
* n×M/G/1/PS similarly idealizes the thread-oriented pattern when the operating system does not rebalance threads among cores.
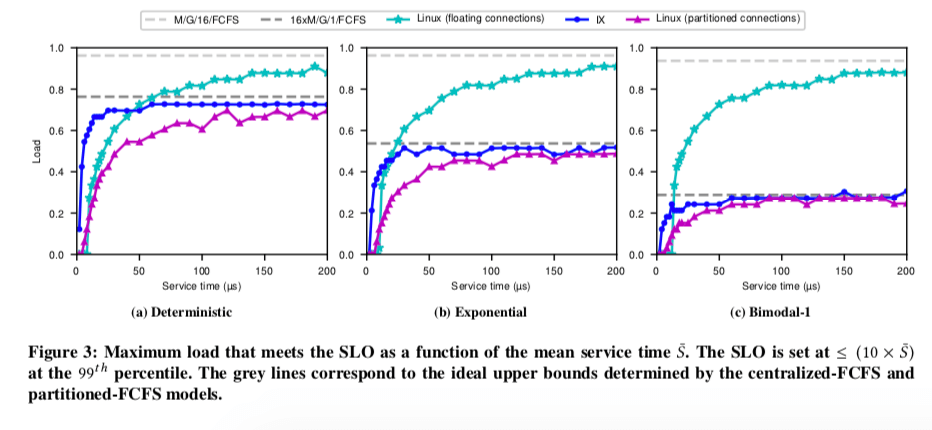
在这样理论上面,ZygOS在时间的系统上做了测试,测试中注重99th的尾延迟,得出了下面的一些结论,
- 单队列的系统(M/G/n/*)比多队列的系统表现出更加好的系统(n×M/G/1/*)。在对队列的系统中,即使是任务平均分配,也会受到暂时性的负载不均衡的影响。
- FCFS表现出更加好的尾延迟的性能。
0x02 基本思路
基于上面的一些分析的数据,sync-free的控制面的设计在处理tail latency时不能提供一个很健壮的解决方案。IX是围绕着 coherency-free这样一种执行模型的设计,一个原因就是在多核下面的可拓展性,它希望尽量减少在处理任务是由于cache-coherence带来了流量。而ZygOS使用任务窃取的方式,就必可避免的带来不同核(线程)之间的通信。为了实现任务窃取,ZygOS实现了intermediate buffering(中间缓冲)的机制,这里业余IX利用网络栈的一些优化来批处理不需要缓冲的方法不同。ZygOS任务的执行分为3层,
- networking layer,在独立的核心上面执行,这里应该就是利用了IX的实现;
- shuffle layer,中间的这一shuffle layer是ZygOS添加的。ZygOS在shuffle layer上了一个单生产者多消费者的模型。shuffle queue上面保存的就是准备好的连接,生产者就是下面这个Core的networking layer。消费者就是上面的application execution layer。
- application execution layer,感觉这里和IX也多大的变化。应用和Kernel之间也是通过事件和批量的syscall交互。在这一层,每一个核心都自己的独立的数据结构,独立地执行任务。下面的图就是一个基本的任务的执行过程:
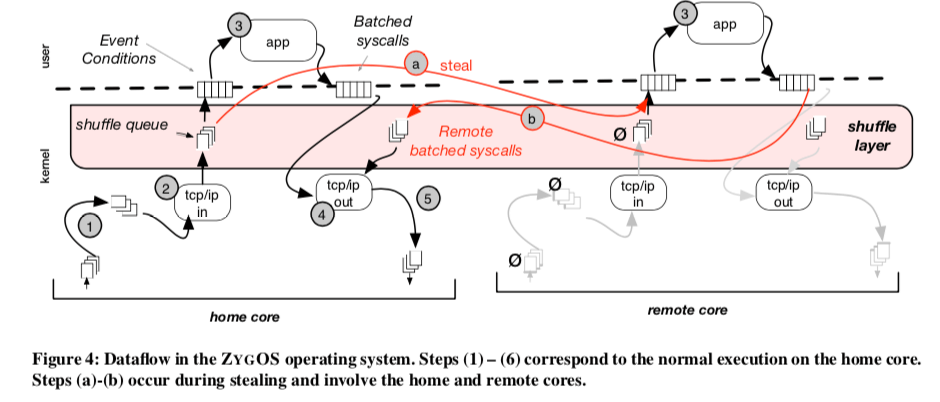
在做了这样的一个基本的设计之后,ZygOS还有另外的几个问题需要处理,
-
多线程应用中的顺序语义,在IX中这里没有问题。在ZygOS中由于一个socket的处理可能在不同的核心(线程)上面处理,就会有问题,一个例子:
Consider the case of back-to-back messages sent to the same socket (e.g., two distinct RPC of the memcached protocol) for a multi-threaded application that uses the Linux-floating model. Unless the application takes additional steps at user-level to synchronize across requests, race conditions lead to broken parsing of requests, out-of-order responses, or worse, intermingled responses on the wire.这里其实也就是一个同步的问题,ZygOS的解决方案就是一种所有权的机制,实现一个线程对一个socket的独占访问。
-
消除Head-of-Line阻塞,由于顺序语义的原因,shuffle layer的设计变得更加复杂。这里处理shuffle queue的时候要注意到任务分配的问题,
ZYGOS eliminates head-of-line blocking by grouping events in the home core by socket. The shuffle queue has the ordered subset of sockets that are (a) not currently being processed on a core and (b) have pending data. -
Inter-processor Interrupts,核间中断机制为了处理这样的几种情况;1. 在网卡中已经有数据了,但shuffle queue位空,这个时候可以通过中断来强制网络栈开始处理;2. 另外一个就是强制来处理一个remore的批量syscall的返回。
ZygOS就实现在IX的基础知识,主要添加or修改了这样的一些东西,The shuffle layer,Idle loop polling logic、Exit-less Inter-processor Interrupts以及Control plane interactions等。
0x03 评估
这里的详细的信息可以参看[1].

参考
- ZygOS: Achieving Low Tail Latency for Microsecond-scale Networked Tasks, SOSP ’17.
