Full-Stack Architecting to Achieve a Billion-Requests-Per-Second Throughput on a Single Key-Value Store Server Platform
0x00 引言
这篇文章时对如何实现一个超高性能的单机key-value的一个总结,很值得一看。文章对比现在的对个KVS系统,并对它们的具体技术做了分析。结合这个团队之前发的KVS相关的几篇论文,总结出对于一个KVS来说,最重要的几个方面就是:
- The networking stack,由于这里讨论的是单机的KVS,所以这里网络这里主要是server和client之间的通信,client发送请求,然后server回复response。一些追求高性能的系统一般都不直接使用OS提供的网络栈,而是使用DPDK or RDMA之类的技术;
- Concurrency control,这里值得就是如何解决多线程访问的问题,支持并行访问的同时保持一致性,这里存在诸多的方式,比如传统的mutex,或者其它种类CC的技术。另外一个在这里,分区也是减少并发控制操作的重要方式,一般高性能的KVS系统都会采用分区的方式;
- Key-value processing,这里将的就是如何实现put,get的功能,还有就是如何优化这些操作,以及缓存替代策略等;
- Memory management,这里将的就如如何管理内存了,常见的有直接使用malloc的,还有就是使用slab之类技术的,另外一种方式就是 log-structured方式的。
下面的表是一些KVS的例子,这些在论文中是测试的对象:

网站很多事从MICA这个系统出发讨论的,使用最好先阅读一下[2]。
0x01 The Road To 120 Million RPS Per KVS Server
这里讨论的事如何使得MICA得到120M的RPS的,这里使用客户端批量执行的话可以达到160M PRS。
系统平衡优化
这里主要讨论的是计算、内存和网络等资源的配比,在Paper中使用的网络硬件中,NIC的速度为10GbE,使用的CPU为Intel Xeon E5-2697v2 (12 core, 30MB LLC, 2.7GHz),两个Socket,一共 24 Cores,这样的CPU一个核心无法让一个10GbE的网络链路全速工作,当使用2个核心,一个10GbE的端口的利用率可以做到9.76Gbps(约为97.4%),继续加多核心,使用3个的时候能够压榨出最后的一点点剩余,但是这个已经没有太多的意义了。所以Paper中使用的core-to-network-port的比例为2:1。
- 当使用16个核心和8个10GbE的端口是,能够实现的速度为80MRPS。然鹅继续增加资源的时候并不能继续提高速度,反而会有下降。
- 开始系统的设计为核心和网络端口之间么有绑定,需要的网卡队列为NumCores × NumPorts,这个造成了大量的内部流量,另外就是不利于DDIO技术的发挥。之后系统优化为核心与端口存在绑定的关系,一个网络端口的数据由指定的核心处理,这样的优化可以使得系统在20个核心10个10GbE网卡的时候达到100MRPS的速度。在这个速度上面又遇到了瓶颈。
- 然后使用Systemtap分析系统运行时的情况,发现一些NIC和处理器的一些信息的收集导致了比较大的overhead,通过降低这个统计信息收集的频率,系统可以实现RPS随着核心数量的增加接近线性增长。在24个核心的时候达到120 MRPS。
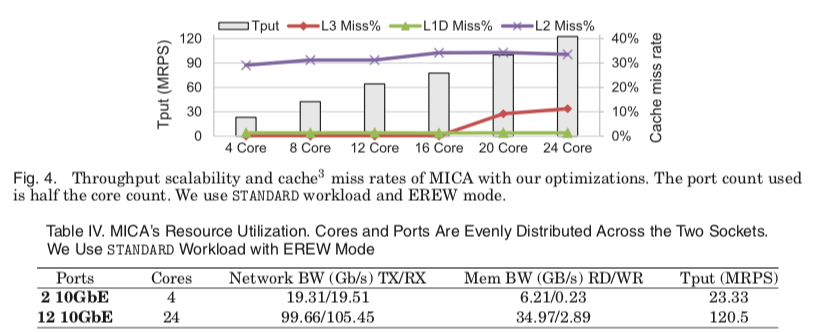
上面图中的一些关于这个性能的进步过程中的一些信息,
- 缓存的信息: 随着RPS的增加,L1D和L2缓存的缺失率变化很小,L1D一致保持在一个很低的水平,而L2的缺失率相对来说比较高,大约为32%。L1D保持低缺失率主要有几个原因:1. MICA实现的时候使用了软件预取的策略,2. 精心设计的buffer重用,比如零拷贝的RX-TX包处理。而L2缺失率较高时因为数据包的Buffers不能放进L1D中。得益于DDIO技术的应用和积极的预取策略,L3缓存的缺失率也保持在一个较低的水平,在后面RPS增大的时候有一个明显的缺失率的增加,这个主要原因是这个时候L3的大小有点不够用了,这里可以看出之后增大L3的大小对之后的性能很有利。
- 内存带宽。在使用2个10GbE的端口的时候使用的带宽为使用6.21GB/s。12个的时候为34.97GB/s。测试用的机器是DDR3 1600,单通道能够提供的带宽为12.8GB/s。
- 另外一个就是SMT,Intel现在的CPU都带有这个功能。在一般的情况下这个功能能够提高性能,但是在一些情况下却会降低(特别是负载较高的计算密集型的情况)。在这里的测试数据中,SMT会降低 24%的性能(24 cores+ 12 10GbE的时候)。
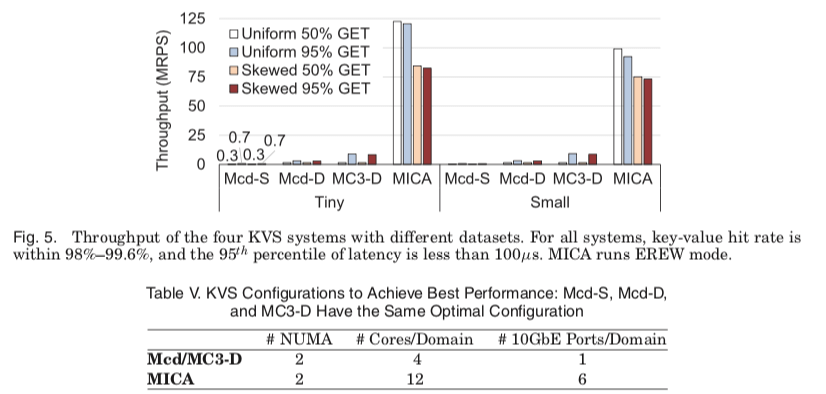
不同系统之间的对比
从下面的这个图看出其它的系统和MICA之间的差距是巨大的。
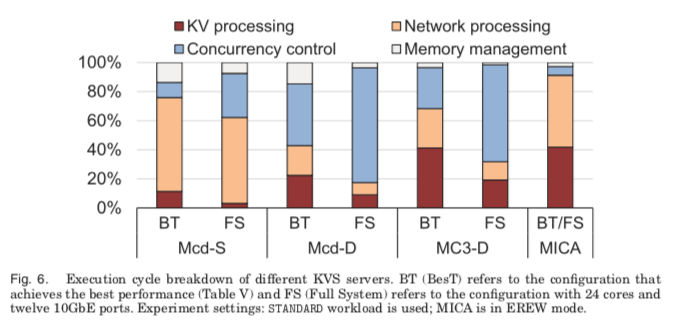
主要的原因分析从下面的这个时间消耗的比例图上面可以看出来,其它的系统实际花在处理请求的时间都只占一小部分。基本上使用内核网络栈和一般的Mutex的并发控制的方式都比较难实现高性能。
另外的几点
-
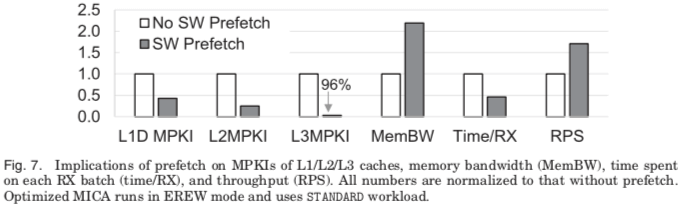
缓存预取,MICA这类KVS应用是对内存的性能方式敏感的应用。MICA在实现时采用了积极的缓存预取策略,数据表明,这个策略对降低缓存缺失率具有非常显著的效果,
... Because of the randomness in requested keys, LLC has a high cache miss rate without SW prefetch (57%), similar to that observed in other KVSs. SW prefetch reduces the LLC miss rate dramatically to 8.04% and thus frees may LLC-miss-induced stall cycles to do KV processing, which improves performance (RPS) by 71% and reduces LLC MPKI by 96%, as shown in Figure 7.另外,这个预取的策略会增加对内存带宽的要求,在实验数据中,这个增加了约17%内存带宽的使用。
- 另外,倾斜的数据对性能是很不利的,在其它的低性能的KVS中,比如Mcs-S中,这个数据倾斜带来的影响很小。但是在高性能的系统这个影响会被加大。MICA的EREW和CREW模式发布较均匀分布的120M降低到84M和108M。
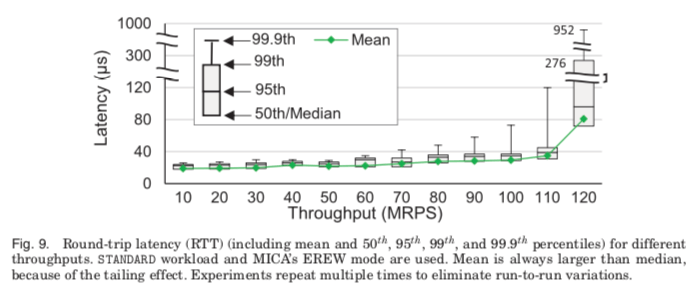
- 另外一个随着RPS提升变化的就是请求延迟,在小于100M的时候,这个延迟的值增长的比较慢,在这个100M之后快速增长。在120M的时候99.9线为952μs。随着增长了很多,还是一个很优秀的水平,
#### 客户端批量化处理
客户端批量化处理也是提高吞吐量的一个很有用的方法。基本的思路就是批量可以平坦网络带来的开销和提高通信的效率,特别是在请求数据包和返回的数据都比较小的情况下(根据Facebook使用Memcached的数据统计,实际的KV都很小)。由此带来的问题就是延迟的增加。通过客户端批量化请求的处理,MICA在测试的系统中每次处理1个请求优化为每次处理4个时,RPS从20.5MRPS增长到167.2MRPS,同样地,这样的优化也降低了网络的overead,因为数据包的数量减少了。批量化处理带来的延迟,
... As throughput increases from 120MRPS to 167MRPS, latency increases gracefully; the mean goes from 39 to 70μs and the 95th percentile from 58 to 112μs. As in the nonbatched case, higher system throughputs take a toll on tail latencies. At 167MRPS throughput, the 99th and 99.9th percentile latencies are 268μs and 824μs, respectively.
0x02 Achievng 1 Billion RPS Per Server
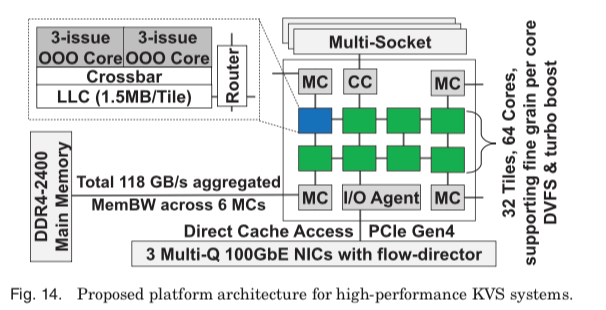
要实现1 Billion的RPS,Paper提出了这样的硬件要求。最重要的增加是在网络方面,有10GbB的网卡提升为100GbE,PCIe升级我哦4.0。另外就是内存,为了应付内存带宽需求地增长,选择了DDR4 2400。对LLC的要求为45MB。在模拟中可以实现超过1 Billion的RPS。从这些配置来看,估计19 or 20年能够提高这样的系统没有问题,在LLC和内存带宽上还可以更高一些。
参考
- Sheng Li, Hyeontaek Lim, Victor W. Lee, Jung Ho Ahn, Anuj Kalia, Michael Kaminsky, David G. Andersen, Seongil O, Sukhan Lee, and Pradeep Dubey. 2016. Full-stack architecting to achieve a billion-requests-per- second-throughput on a single key-value store server platform. ACM Trans. Comput. Syst. 34, 2, Article 5 (April 2016), 30 pages. DOI: http://dx.doi.org/10.1145/2897393.
- MICA: A Holistic Approach to Fast In-Memory Key-Value Storage, NSDI‘14.
