OpLog: a library for scaling update-heavy data structures
0x00 引言
OpLog是为频繁更新的数据结构设计的一个库。基本思想就是推迟真正的更新操作,直到下一次读取操作(or达到其它的一些条件)得时候,一次性应用这些更新操作,使用批量的方式来降低成本,这样还大大地减少在多核情况下的数据竞争。
... OpLog achieves generality by logging operations without having to understand them, to ease application to existing data structures. OpLog can further increase performance if the programmer indicates which operations can be combined in the logs.
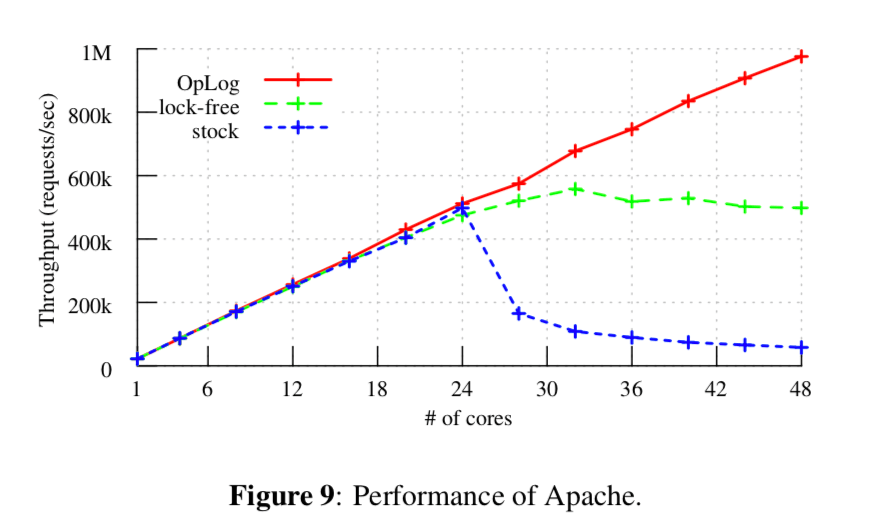
An evaluation shows how to apply OpLog to three update-heavy Linux kernel data structures. Measurements on a 48-core AMD server show that the result significantly improves the performance of the Apache web server and the Exim mail server under certain workloads.
Paper中讨论了几个适合使用OpLog的数据结构的例子,详情可以参看[1].
0x01 基本原理
OpLog将每一个操作都赋予一个timestamp。这些更新的操作不会被马上实际地执行,而是会被保存在一个pre-core的log里面。在下一次读取操作的时候,将这些根据时间戳代表的先后顺序来将这些操作合并,然后执行实际的更新操作,最后在执行读取操作。这里可以看出来更新操作会是很快的,因为就是一个添加log的操作而已,而且还是pre-core的,不会存在数据竞争。但是对于一个读取的操作来说,它可能需要的时间就比较长,因为需要合并处理这些log,还是执行真正的更新操作,当然连续的读取的话,只有第一个需要这样做。
OpLog不用关系低层的数据结构具体是如何实现的。这里可以看出来,这里的原理是比较简单的,理解起来也很容易。关键是在一个具体的数据结构上是如何实现的。这里还使用了几个优化:
-
Batching Updates,统一处理更新会获取更加好的局部性,对缓存友好;
-
Absorbing updates,这些操作里面包含了添加之后又删除的话,这对操作就可以之间忽略了;
-
Allocating logs,对于避免没有什么数据冲突的操作进行log,带来额外的开支。如果一个对象最近没有被更新过,就直接应用,
If an object has not been updated recently on a given core, OpLog applies all updates to that object from other cores’ logs (if any), and then frees the local log space.
基本操作接口:
Method call: Semantics:
Object::log(Op* op) add op to a per-core log, implemented by a Log object,
Object::synchronize() acquire a per-object lock, and call apply on each per-core Log object,
Object::unlock() release the per-object lock acquired by synchronize(),
Log::push(Op* op) insert op into a per-core Log object,
Log::apply() sort and execute the operations from Log,
Log::try_absorb(Op* op) try to absorb an op,
Op::exec() execute the operation,
0x02 几个例子
使用OpLog转化一个数据结构为OpLog的工作的,一个interval tree的例子:
struct Rmap : public Object<Log> {
public:
void add(Mapping* m) {
log(AddOp(m));
}
void rem(Mapping* m) {
log(RemOp(m));
}
void truncate(off_t offset) {
synchronize();
// For each mapping that overlaps offset.. interval_tree_foreach(Mapping* m, itree_, offset)
// ..unmap from offset to the end of the mapping.
unmap(m, offset, m->end);
unlock();
}
private:
struct AddOp : public Op {
AddOp(Mapping* m) : m_(m) {}
void exec(Rmap* r) {
r->itree_.add(m_);
}
Mapping* m_;
};
struct RemOp : public Op {
RemOp(Mapping* m) : m_(m) {}
void exec(Rmap* r) {
r->itree_.rem(m_);
}
Mapping* m_;
};
IntervalTree<Mapping> itree_;
};
将实际的操作包装到一个继承了Op类的操作中即可,需要的时候要加锁。下面一个计数器的例子也差不多:
struct Counter : public Object<CounterLog> {
struct IncOp : public Op {
void exec(uint64_t* v) { *v = *v + 1; }
}
struct DecOp : public Op {
void exec(uint64_t* v) {
*v=*v-1;
}
}
void inc() {
log(IncOp());
}
void dec() { log(DecOp()); }
uint64_t read() {
synchronize();
uint64_t r = val_;
unlock();
return r;
}
uint64_t val_;
};
struct CounterLog : public Log {
void push(Op* op) { op->exec(&val_); }
static void apply(CounterLog* qs[], Counter* c) {
for_each_log(CounterLog* q, qs)
c->val_ += q->val_;
}
uint64_t val_;
};
0x03 评估
这里的详细信息参看[1],
参考
- OpLog: a library for scaling update-heavy data structures, Silas Boyd-Wickizer, M. Frans Kaashoek, Robert Morris, and Nickolai Zeldovich
