Scaling a file system to many cores using an operation log
0x00 引言
ScaleFS是前几天看过的OpLog的一个应用。ScaleFS一个创新的地方就是将文件系统分为in-memory的部分核on-disk的部分。ScaleFS使用pre-core的operation logs,可以将一些操作实际完成的时间推迟[2]。通过诸多的优化措施,ScaleFS消除了文件系统中在并行情况下大部分的冲突,
... ScaleFS show that its implementation has no cache conflicts for 99% of test cases of commutative operations generated by Commuter, scales well on an 80-core machine, and provides on-disk performance that is comparable to that of Linux ext4.
0x01 基本思路 & 设计
ScaleFS由两个部分组成。一个在内存中的MemFS和一个磁盘上面的DiskFS。MemFS使用并发的数据结构来实现在内存中的可交换顺序的操作。DiskFS的作用和传统的文件系统一样,在磁盘上面构建一个文件系统的逻辑,保存数据。它们之间通过operations log结合到一起。不仅仅是OpLog的设计应对了频繁更新的操作,而且ScaleFS中MemFS也有利于提高读的性能。
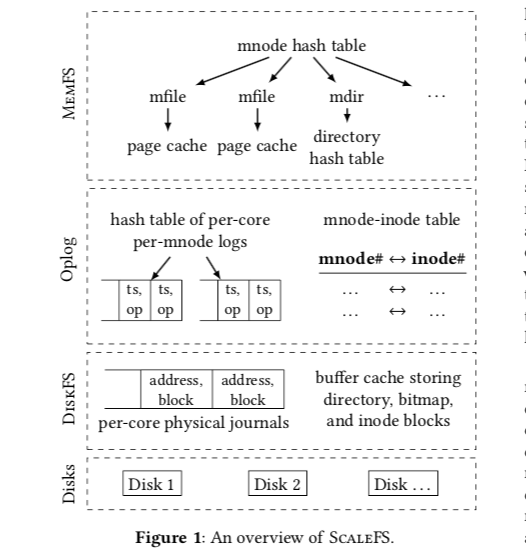
ScaleFS的基本设计如上如所示。在MemFS中使用的是mnode,而在DistkFS中使用通常的inode,而且在系统重启之后mnode的ID可以变化的。MemFS和DiskFS中间的重要部分就是OpLog,也是ScaleFS基本设计的一个基础。OpLog是一个per-core的结构,为了在并发的情况下减少冲突。在这样的结果设计下面一般的文件操作的实现思路,
- 文件创建,ScaleFS中创建文件会是先分配一个mnode和一个mfile结果。然后在mfile结构添加到mnode hash table中,再在目录的hash table添加一项。MemFS也会在OpLog中添加一项,记录下这个创建的操作的一些信息,比如文件的名字,文件的mnode;
- fsync,在一个目录上执行fsync操作的时候,MemFS会将每一个核心的Log项集中起来,根据Log项的时间戳信息来对其进行排序,更改的信息发送的DiskFS上面持久化,还会为文件分配mnode对应的inode。在一个文件上面执行fysnc操作是,会将这个文件相关的脏页写入磁盘,修改相关的元数据。在需要的时候还要为其分配inode。另外,ScaleFS也会周期性地将内存中积累的修改的信息持久化到磁盘上面;
- readdir,Reading a file。对于这些读取型的操作,都会引发MemFS的工作, 现在内存中查找相应的信息。在内存中没有的时候在到磁盘上面查找。由于mnode和inode的存在,在必要的时候相关的转化也是必须的;
- Writing to a file,和一般的PageCache机制类型,也是先将更改信息先积累在内存中,这里还要在必须的时候修改文件如文件长度之类的元数据;
- Crash recovery,很显然这里的基本的方式就是从之前的Operation Logs中恢复。这里还有另外一个孤儿inode的问题要处理,这个问题出现在应用调用fsync之后,然后这个操作还没有完成的时候系统就奔溃。想要修改的目录的信息没有得到修改(或者是相反的操作,一个unlink了一个文件但是保留了一个打开的文件描述符)。这里DiskFS会在启动时候扫描inodes,释放这些孤儿inode(会消耗多少时间?)。
在ScaleFS设计的过程中,要解决的两个主要的问题就是性能(P)和正确性(C)的问题。ScaleFS使用了这样的一些方法。使操作有序上,这里基本的方法就是利用现在的硬件提高的同步时间戳计数器来为操作分配时间戳,
ScaleFS orders in-memory directory operations by requiring that all directory modi- fications in the in-memory file system be linearizable. Moreover, ScaleFS makes the linearization order explicit by reading the timestamp counter at the appropriate linearization point, which records the order in which MemFS applied these operations.
另外Scale其它的多种的优化措施。
0x02 评估
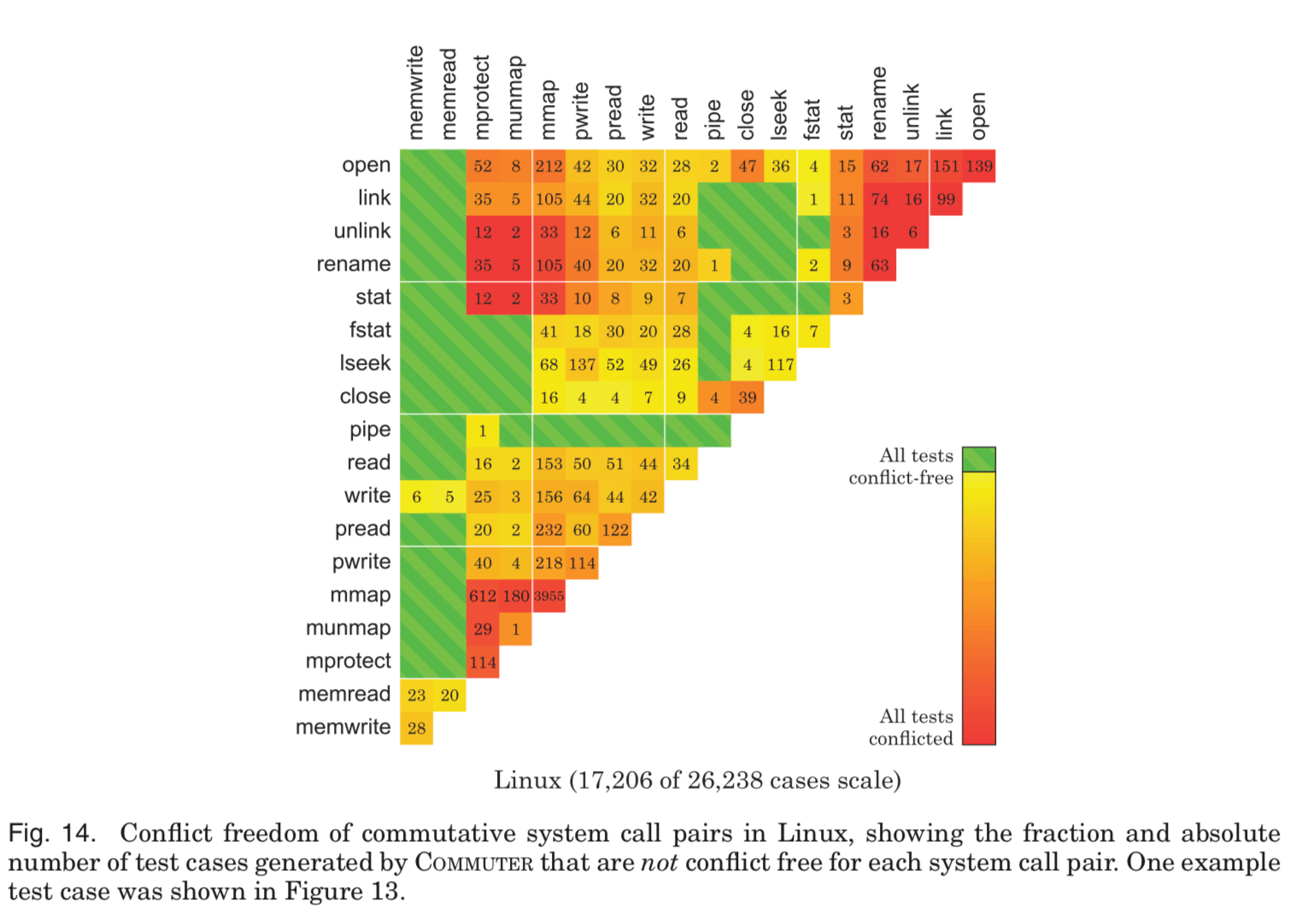
这里的具体的信息可以参看[1], 在现在的Linux中,
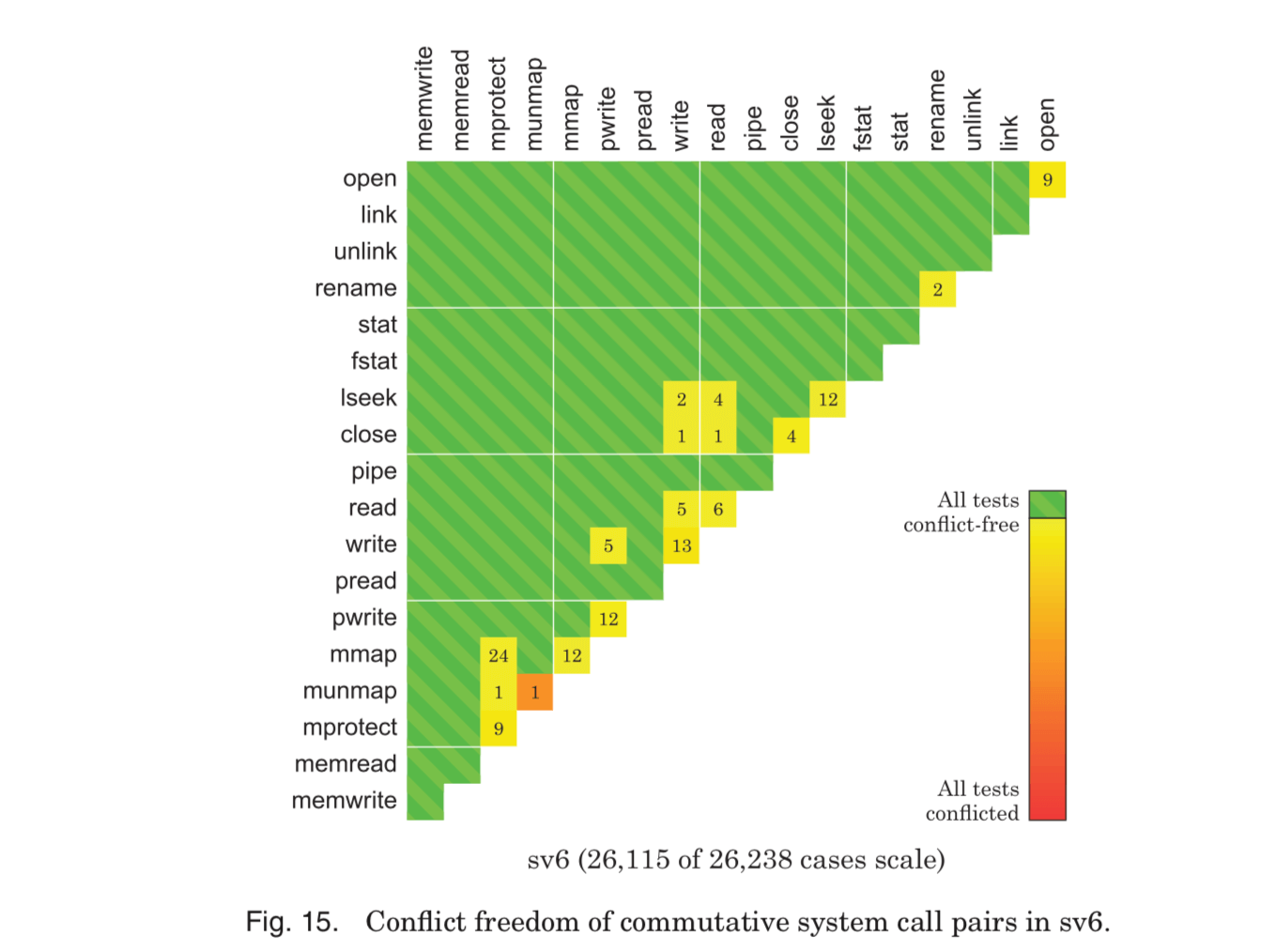
而在ScaleFS中,
参考
- Scaling a file system to many cores using an operation log, SOSP 2017.
- Austin T. Clements, M. Frans Kaashoek, Nickolai Zeldovich, Robert T. Morris, and Eddie Kohler. 2015. The scalable commutativity rule: Designing scalable software for multicore processors. ACM Trans. Comput. Syst. 32, 4, Article 10 (January 2015), 47 pages. DOI: http://dx.doi.org/10.1145/2699681.
