Anna: A KVS for any scale
0x00 引言
Anna是发表在ICDE 2018上的一篇关于KVS的文章。不同于前面的一些KVS,Anna的两个最主要的特点一个就是就是它的分区的方式,使用了Coordination-free Actors的模型,另外一个就是Lattice-Powered, Coordination-Free Consistency的一致性模型。Anna的标题就”非常厉害“的样子,for any scale!怎么实现?Paper里面列举的Anna要实现的目标:
... providing excellent performance on a single multi-core machine, while scaling up elastically to geo-distributed cloud deployment. In addition to wide-ranging architectural flexibility, we wanted to provide a wide range of consistency semantics as well, to support a variety of application needs.
这里和之前看过的一些单机的KVS不同,Anna除了要在单机上面实现很高的性能,能够充分利用多核机器外,还要能实现分布式的部署,并为此实现了多种类型的一致性语义,以此满足不同应用的要求。未来实现这些目标,Anna主要使用了这些方式:
- partition,不仅仅是在结点直接分区,还要在结点的core上分区,这个分区也是实现Anna 的Coordination-free actor模型的一个基础,这个分区也是其它的KVS很常用的套路,一般都是基于hah的分区方式;
- multi-master replication, 未了实现可伸缩性,Anna使用了multi-master的副本的方式,这样就可以在多个线程之间并发地对一个key进行get put操作,这样要解决的一个问题就是如何保持数据一致性的问题;
- wait-free execution,未来重复的利用每一个线程,Anna要实现线程都是在做有用的工作,不要有在等待之类的行为。Anna可以实现不会出现一个线程因为一致性之类的原因等待其它的线程的情况。
- coordination-free consistency models,这里就是未来实现广范围的语义,主要就是指一致性。
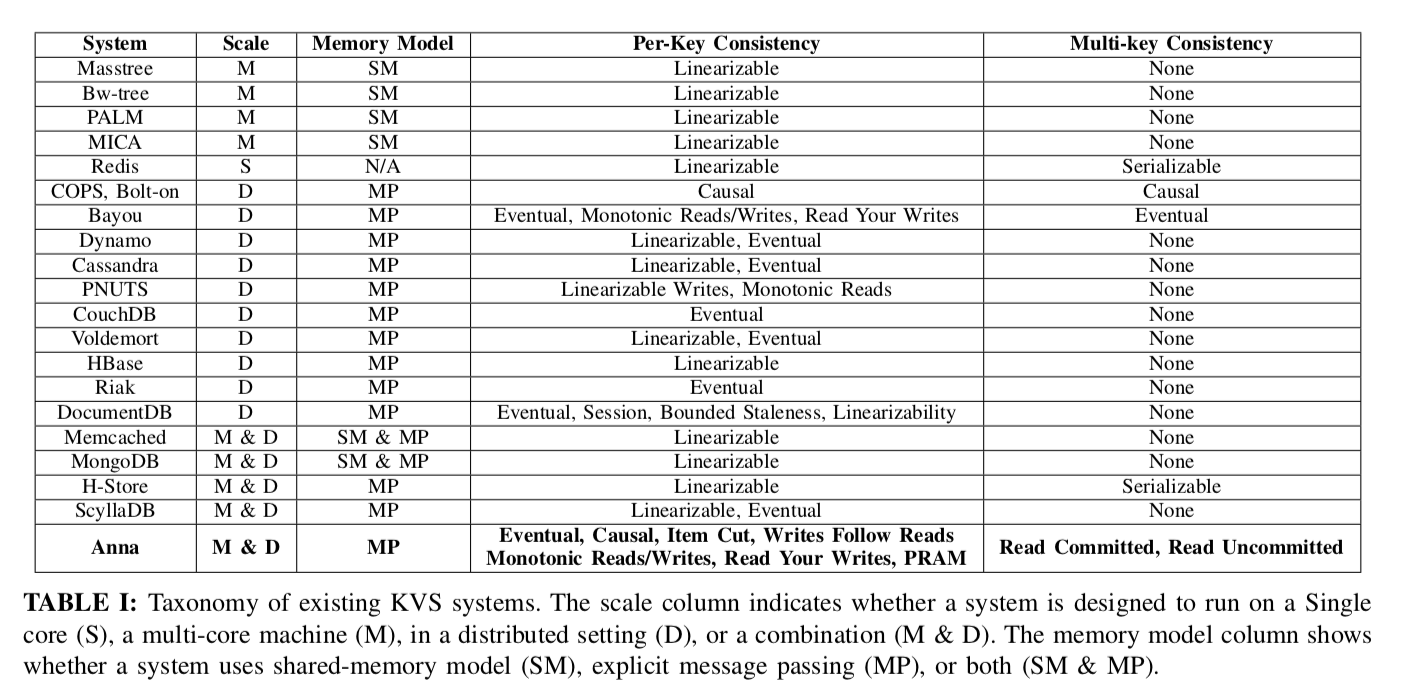
一些系统一致性的比较,这里就表现出了Anna可以支持多种类型的一致性。
0x01 基本技术
- Coordination-free Actors,Anna将一个数据分区上面的操作抽象为一个Actor,并通过实现Anna这个团队之前的一些研究,实现了Coordination-free的特点,关于这个Coordination-free具体的情况,应该参看具体的论文。
- Lattice-Powered, Coordination-Free Consistency, 这个技术也是基于之前的研究,将其用在了Anna之上,所以Anna这里其实是这个团队其它的一些研究的成果的综合,做出了Anna这个系统。想详细了解这个系统的话,还是要看一些相关的论文。
- Cross-Scale Validation,这个技术就是实现在单机上面的高性能的同时有可以实现跨地理复制的可拓展性。
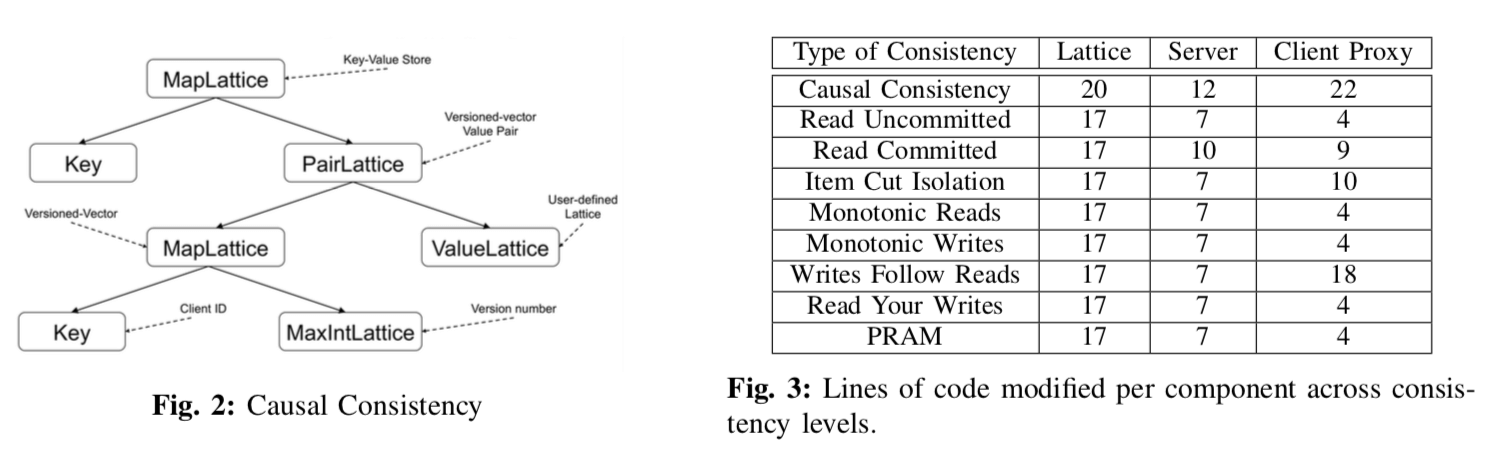
这里要具体说的就是LATTICES。前面提到了Anna实现了一种multi-master replication的方式,并发更新可以在多个线程上面更新同一个key,另外一方面,Anna又要实现wait-free,未了解决这个问题,Anna使用的是lattice。Lattice在Anna可以实现保存和异步地合并状态。Lattice是Anna中一个非常核心的功能,主要是一下两个原因:
-
在合并更新的时候,lattices多这些更新的顺序是不敏感的。这意味着actors可以在接收到的更新操作不相同的情况下吗依然实现要求的一致性;
-
第二个元素这个是Anna实现coordination-free consistency的基础了,Anna可以实现从linearizability or serializability之类的强一致性,也可以实现其它一些不这么”强”的一致性,比如causality 和 read-committed,
Our contribution is architectural: Anna shows that these many consistency levels can all be expressed and implemented using a unified lattice-based foundation.
这里另外一个重要的概念就是convergent and commutative replicated data-types (CRDTs),具体的可以参考论文[2],
A *bounded join semilattice* consists of a domain S (the set of possible states), a binary operator ⊔, and a “bottom” value ⊥. The operator ⊔ is called the “least upper bound” and satisfies the following properties:
Commutativity: ⊔(a, b) = ⊔(b, a) ∀a, b ∈ S
Associativity: ⊔(⊔(a, b), c) = ⊔(a, ⊔(b, c)) ∀a, b, c ∈ S
Idempotence: ⊔(a, a) = a ∀a ∈ S
Together, we refer to these three properties via the acronym ACI. The ⊔ operator induces a partial order between elements of S. For any two elements a, b in S, if ⊔(a,b) = b, then we say that b’s order is higher than a, i.e. a ≺ b. The bottom value ⊥ is defined such that ∀a ∈ S, ⊔(a,⊥) = a; hence it is the smallest element in S. For brevity, in this paper we use “lattice” to refer to “bounded join semilattice” and “merge function” to refer to “least upper bound”.
上面这一段话的描述了lattice的一些定义,lattice这里实际只的就是“bounded join semilattice”。这里定义了在这状态上面的交换律、结合律和幂等,这里简称为 ACI (Associative, Commu- tative, Idempotence) 。CRDT满足了上面的Commutativity,Associativity,Idempotence属性之后,就意味着处理这些操作不用考虑它们之间的顺序关系,Idempotence的特性使得这里执行多次也会得到的是执行一次的结果,这就个实现这个一致性很大的空间。如何实现上面的这些属性呢?这个事客户端定义的,也只能这样了,emmmmmmmm。
0x02 Anna架构
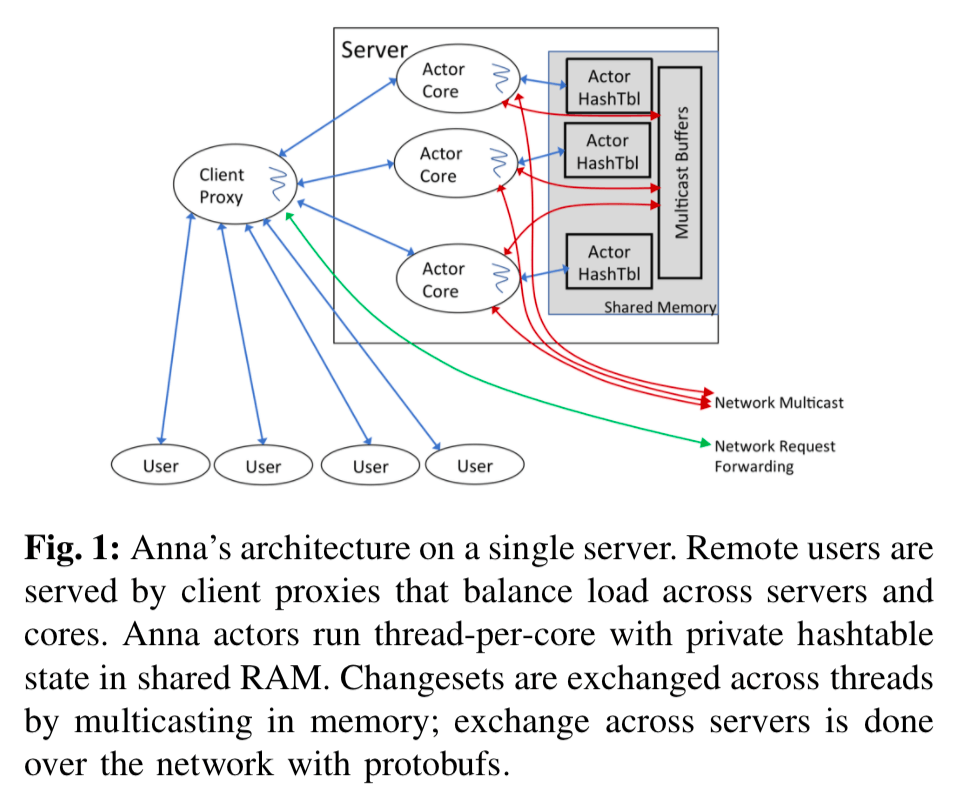
Anna在架构上没有上面特别的,在一个单机上面,每一个核心一个线程,数据被分区保存。同一个结点之间的通信通过内存进行,不同结点之间的通信通过网络进行。Anna数据的分区方式也就是常用的一致性hash,数据会在不同的actor上面保存副本。在这里,lattice是关键:
Anna actors engage in epoch-based key exchange to propagate key updates at a given actor to other masters in the key’s replication group. Each actor’s private state is maintained in a lattice-based data-structure, which guarantees that an actor’s state remains consistent despite message delays, re-ordering, and duplication.
这里将每一个工作的线程抽象为actor不是重点。这里存在一个问题就是,更新操作可能在多个结点上面进行,那么查找操作如何保证看到这些更新操作产生的结果。
Actor这里分工作方式就是类似于event loop。它不同的检查达到的请求,然后处理这些请求。不过这里的更新操作不会马上就被传播到其它副本上面的去,而是等待在一个epoch的末尾,然后才将这些更新操作的传播给其它的副本。而这个时候也要处理来自其它副本的信息。由于这里的数据满足了前面提到的几个特点,只需要将这些操作在本地之间应用即可。这里批量处理的方式极大的减少了通信的成本和显著地提高了性能:
Hence batches of associative updates can be merged at a sending replica without affecting results; merging at the sender can dramatically reduce communication overhead for frequently-updated hot keys, and reduces the amount of computation performed on a receiving replica, which only processes the merged result of updates to a key, as opposed to every individual update.
Anna这里对per-core-per-thread-per-hash-table的抽象为actor是一个很好的方法,看起来很优美,但是上面特别的。Anna这里主要的就是如何在Lattices的基础之上实现这些一致性(这里具体怎么做没有详细说,还是总结在后面的关于这个的里面)。
0x03 评估
Anna这里评估数据的对比对象就是在耍流氓,在一个多核的机器上,用每一个核心一个线程,这个线程处理自己的hash table的数据。将这个和一个单一的运行在这么多核心上面的Masstree、TBB hash table比较。这个比较方式简直了,不超出很多倍才怪。
参考
- Anna: A KVS for any scale, ICDE’18.
- M. Shapiro, N. Preguic ̧a, C. Baquero, and M. Zawirski, “Conflict-free replicated data types,” in Symposium on Self-Stabilizing Systems. Springer, 2011.
