Mega-KV: A Case for GPUs to Maximize the Throughput of In-Memory Key-Value Stores
Mega-Key的基本思路就是使用GPU来做Key-Value的索引,GPU上面的显存有限,数据不保存在GPU上面。它号称可以,
Running on a commodity PC installed with two CPUs and two GPUs, Mega-KV can process up to 160+ million key-value operations per second, which is 1.4-2.8 times as fast as the state-of-the-art key-value store system on a conventional CPU-based platform.
使用GPU来实现KVS的优点:GPU高度的并行性,可以批处理大量的请求;GPU显存的带宽比内存的带宽高上一个数量级;不够使用GPU实现KVS的问题也很多:
- GPU的显存很有限,而且数据传输的成本比较高;
- GPU的显存虽然带宽很高,但是延时也很高;
- 为CPU+内存设计的数据结构不适应GPU+显存的工作环境;
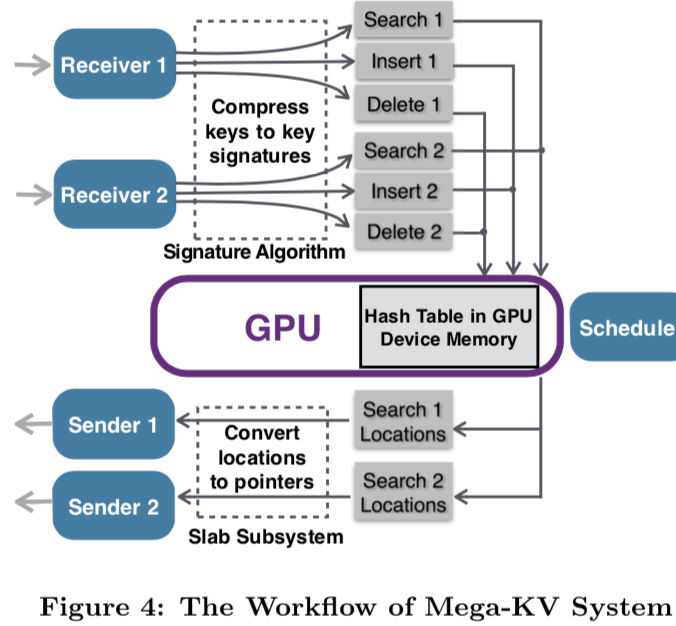
这里就从这三个方面出来来看如何解决这几个问题并利用好GPU的优点:
- Decoupling Index Data Structure from Key-Value Items,Mega-KV只在GPU上面保持index数据结构。这样大大减少了GPU和内存之间的数据传输的量和显存的使用。而且在一般情况下,就算把数据都保存到显存上面,就get操作的时候还是要拷贝到内存之后才能恢复客户端。
- GPU-optimized Cuckoo Hash Table as the Index Data Structure。index结构使用的在KVS中很常见的Cuckoo Hash Table。为了简化index,这里不会直接保存完整的key到GPU上面,而是使用一个32bits的签名信息,外加上一个内存上面的location ID,后者是内存上面的位置信息,保存了具体的数据。这里index的设计充分利用的GPU的并行特性,具体的信息可以参考[1].
- Periodic GPU Scheduling for Bounded Latency,这里就是如何在批处理数量和延时之间的取舍,这里基本的方式是延时调度,下面的图是一个Batch Size和延时时间的一个关系图,
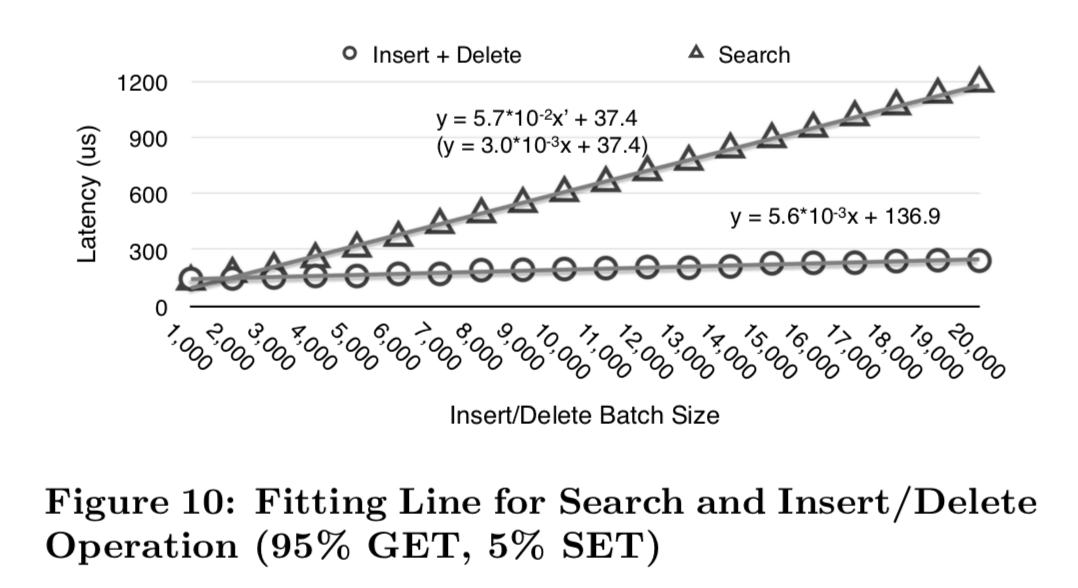
从吞吐的性能数据来看,Mega-KV还是很不错的,
... For the 95% GET 5% SET skewed workload, Mega-KV achieves 110 MOPS, 55 MOPS, and 34 MOPS with get query, and achieves 139 MOPS, 60 MOPS, and 30 MOPS with getk query. For the 100% GET skewed workload, Mega-KV achieves 107 MOPS, 56 MOPS, and 36 MOPS with get query, and achieves 144 MOPS, 62 MOPS, and 33 MOPS with getk query, respectively.
MemcachedGPU: Scaling-up Scale-out Key-value Stores
这篇Paper也是关于如何在GPU上面实现KVS的Paper,不够侧重掉不相同。Mega-KV强调的是KVS的索引、批处理请求等方面的设计。这篇Paper提出的GNoM框架侧重点在网络方面,
We introduce GNoM, a software framework enabling energy-efficient, latency bandwidth optimized UDP network and application processing on GPUs.
...
MemcachedGPU achieves ∼10 GbE line-rate processing of ∼13 million requests per second (MRPS) while delivering an efficiency of 62 thousand RPS per Watt (KRPS/W) on a high-performance GPU and 84.8 KRPS/W on a low-power GPU.
GNoM旨在让利用UDP的应用高效地运行在GPU上面。这里使用的就是Memcached。
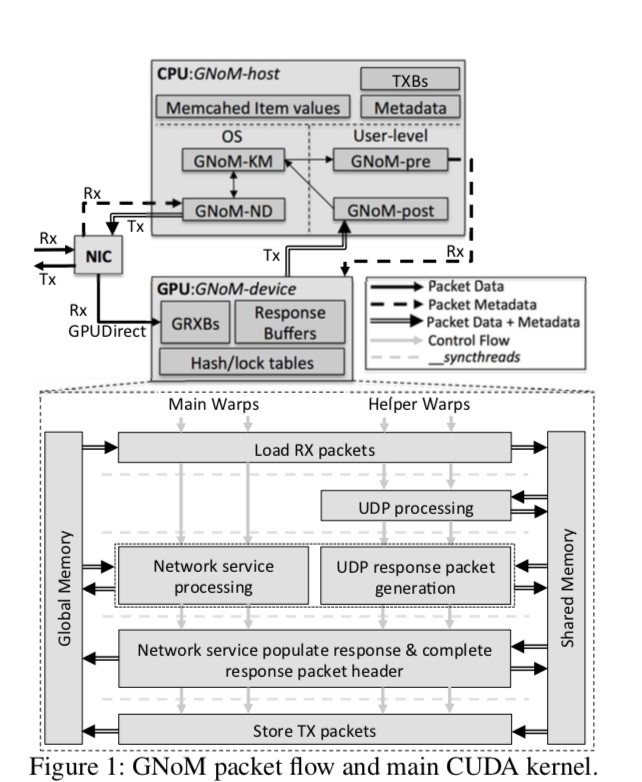
上面的图表示GNoM包处理的流程图。上面中值得一看的是Rx GPUDriect的路径。在传统的数据包的处理中,要先经过GPU,将数据先放到内存中然后在传输到GPU上面处理,这样的缺点是显而易见的。这里的处理最大的一个特点就就是将接收的数据包直接传输到GPU来处理。不够在Paper中也指出,这个GPUDirect只支持部分的显卡,
GPUDirect is currently only supported on the high-performance NVIDIA Tesla and Quadro GPUs. To evaluate MemcachedGPU on lower power, lower cost GPUs, we also implemented a non-GPUDirect (NGD) framework. NGD uses PF_RING to receive and batch Memcached packets in host memory before copying the request batches to the GPU.
为了处理和GPU交互的overhead比较大的问题,使用的最常见的方法就是批处理的调度,这里也不例外。与前面的Mega-KV相比,这里在网络传输的处理上做出了更多的工作。另外在KVS主要的数据结构的设计上,这里也使用的cuckoo hash table。这里在GPU上面保存的只是key和index结构,value部分的数据还是保存在内存之中。GET的流程和SET的流程差异比较大。
- GET操作,MemcachedGPU将大部分的GET操作放在了GPU上面,包括解析GET请求、提取出key、hash这个key,然后查找hash table获取到value的pointer。然后相关的数据交给CPU处理,回复客户端。MemcachedGPU这里的GET操作是使用的GPU,这个也是Memcached本来就支持的方法。
- SET操作就使用TCP,走的路线也和传统的比较相似,当然最后的index的信息会是保存在GPU保存。
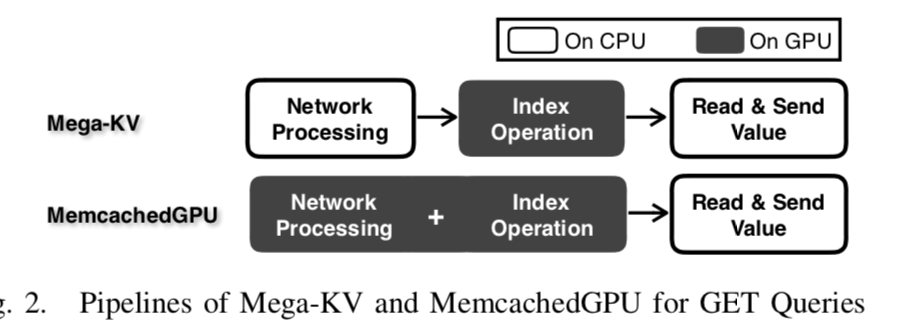
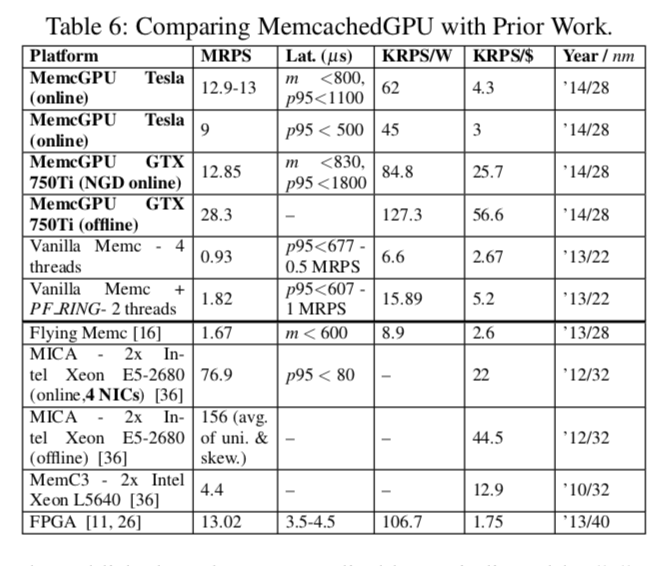
下面图比较简单的表现了mega-kv和memcachedGPU的不同点:
一些性能信息:
DIDO – Dynamic Pipelines for In-Memory Key-Value Stores on Coupled CPU-GPU Architectures
与前面的两个不同,这里的DIDO强调的是CPU-GPU的联合处理。DIDO主要有三个部分:
-
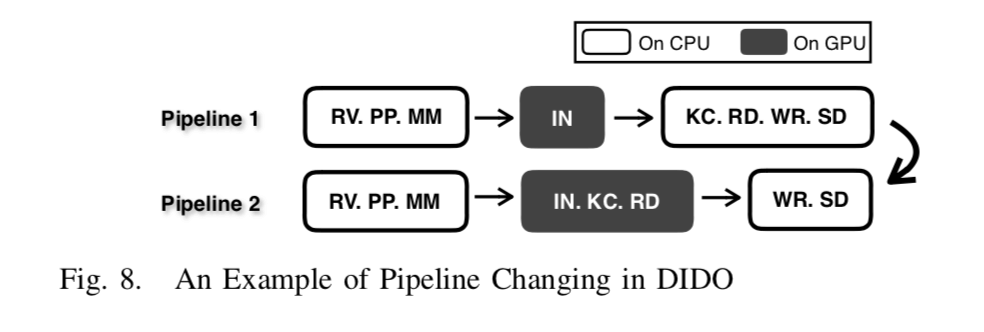
Query Processing Pipeline,流水线化的主要好处之一就是灵活性的提高。和前面的两个系统是固定部分的在GPU上面处理不同,这里可以根据面前的运行情况决定这个流水线的有那几个stage在GPU上面运行。这里一个的流水线被分为了8个部分:
(1) RV: receive packets from network; (2) PP: packet processing, including TCP/IP processing and query parsing; (3) MM: memory management, including memory allocation and eviction; (4) IN: index operations, including Search, Insert, and Delete; (5) KC: key comparison; (6) RD: read key-value object in the memory; (7) WR: write response packet; and (8) SD: send responses to clients.
下面的图就表示出了流水线不同部分在GPU上面运行的例子:
- Workload Profiler,这里就是发现系统当前的负载的特点,为后面的“动态”处理提供一些统计信息。
- APU-Aware Cost Model,Paper中测试的环境使用的是AMD的APU。如前面所言,动态的流行先为的就是提供系统的整体性能。那么如何安排流行才能使得系统性能最好呢?这里使用的就是Cost Model的方法,通过对操作进行成本估计,选择成本最低的方法,这里具体的计算模型可以参考[2]。
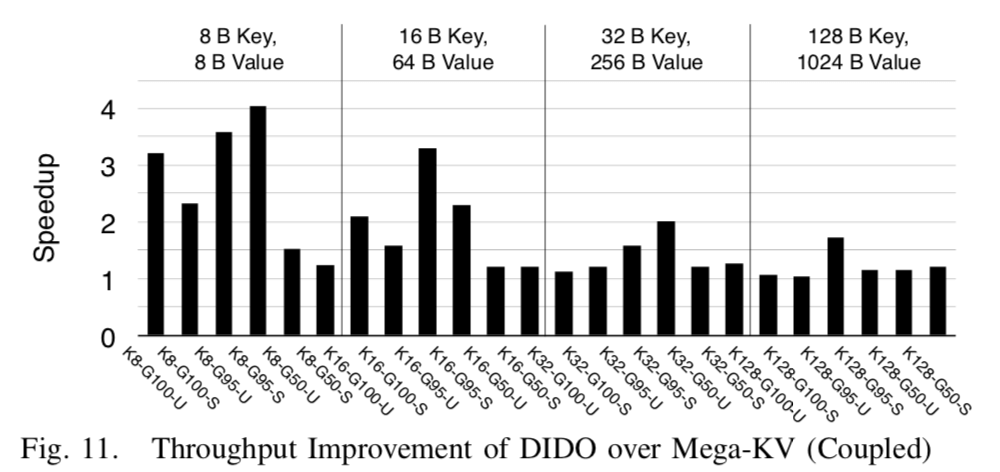
下面是一些性能信息:
参考
- Mega-KV: A Case for GPUs to Maximize the Throughput of In-Memory Key-Value Stores, VLDB 2015.
- DIDO: Dynamic Pipelines for In-Memory Key-Value Stores on Coupled CPU-GPU Architectures, ICDE 2017.
- MemcachedGPU: Scaling-up Scale-out Key-value Stores, SoCC’15.
