The Design and Implementation of Open vSwitch
0x00 引言
虚拟化对数据中心网络的产生了很大的影响。现在的很多的网络接入层的端口都是虚拟化的而不是物理的。现在的网络的第一条的交换机越来越是hypervisor,而不是用来的数据中心网络中的ToR交换机。已有解决方案的不足导致了网络虚拟化的出现,在这样的网络中,虚拟交换机变成了一个重要的组成部分,虚拟的交换机在数据中心网络和hypervisor之间传输IP隧道数据包,它可以使得虚拟网络和和物理网络分离。Open vSwitch为解决这些问题和客服现有一些解决方案的局限性而出现,
Today, on Linux, its original platform, Open vSwitch works with most hypervisors and container systems, including Xen, KVM, and Docker. Open vSwitch also works “out of the box” on the FreeBSD and NetBSD operating systems and ports to the VMware ESXi and Microsoft Hyper-V hypervisors are underway.
虚拟交换机的操作环境和通常的交换机的运行环境是完全不同的。这样也就导致了虚拟交换机会有一些设计上的取舍和约束,下面是它的设计约束及其原因,
- 资源共享,独立的交换机它的计算资源是独立占有的,它就可以只用考虑如何发挥出这些硬件资源的性能即可。但是虚拟交换机和其它的部分共享资源,这就要求它能够尽可能地节约资源的使用。虚拟交换机也就很难去优化各种各样的情况,而是只能去优化最常见的情况。这个情况导致了Open vSwitch的实现中大量了使用各种的缓存机制来降低CPU的使用率和提供转发的速率;
- 安放位置,虚拟交换机处于网络的边缘位置,消除了很多存在的网络问题。但是这里要处理的一个问题就是一个hypervisor上面运行上千台的虚拟机情况并不罕见,虚拟机的状态变化也要求虚拟交换机进行相应的状态更新。这个就要求Open vSwitch能够处理这样的情况。这也影响了Open vSwitch的O(1)的分类算法的设计。
- SDN, use cases, and ecosystem,另外还有3个原因影响了Open vSwitch的设计,1. 它一开始就是一个OpenFlow交换机;2. OpenFlow开始很注重灵活性,但也导致了在一些环境下面的处理的线路太长,造成了不小的负载,这个是的它必须使用流缓存;3. Open vSwitch要能使用不同的环境,这个是的它注重模块化和可移植性。
0x01 设计
概览
Open vSwitch的基本架构设计:
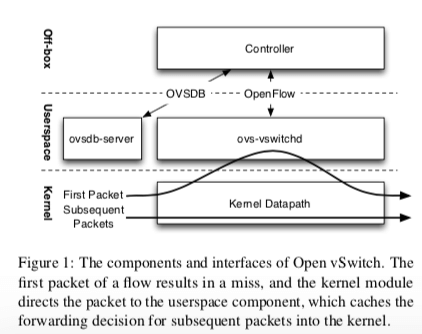
Open vSwitch中有两个模块用于数据包的转发,较大的ovs-vswitchd是用户空间的一个守护进程,而且在不同的操作系统上面这个组件是基本相同的。另外一个是datapath kernel module,运行在内核中,主要是为了提高速度,因为运行在内核中,所以不同的环境会存在不小的差别。关于Open vSwitch工作方式的几点:
-
两个OVS组件组合工作转发数据包的方式:kernel中的datapath模块首先从物理or虚拟的网卡中接受数据包。在ovs-vswitchd已经告诉它如何处理某种类型的包的时候,datapath模块直接就可以根据actions指令进行处理。这些actions一般是告诉台向那些端口or隧道发送这种类型的数据包,也可以对数据包进行修改、采样或者是丢弃等的行为。在没有给出处理方式的时候,则这个包会被传送给ovs-vswitchd,ovs-vswitchd会根据数据包的内容决定如何处理,然后会将包和包的处理方法传回给datapath,也可以告诉datapth缓存这些actions,下次就可以直接处理了;
-
Open vSwitch一般作为一个SDN交换机,使用OpenFlow的控制转发方式,
In Open vSwitch, ovs-vswitchd receives OpenFlow flow tables from an SDN controller, matches any packets received from the datapath module against these OpenFlow tables, gathers the actions applied, and finally caches the result in the kernel datapath. -
包分类器,不如在专用的交换机处理器上,在通用的处理器上实现包分类算法相对来说是一种昂贵的操作,这个在OpenFlow体现地更加的突出,它可能测试下面的任意的组合:IPv4 和 IPv6 地址,TCP 和 UDP端口, 其他的一些如交换机入端口等的元数据。Ooen vSwitch使用tuple space search分类器,它可能不是目前理论上最好的,但是在实际的应用中表现很好。一个基本的工作方式的例子:在开始匹配的时候值匹配源和目的的以太网地址,这样Flow Table就会是单个的hash table。当又创建了不同的批评规则的时候,会添加一个新的依照新的规则的hash table。在匹配操作的时候,如果只有一个hash table存在匹配的那么久应用对应的规则,如果没有匹配的那么就是没有对应的规则,如果存在多个匹配的,应用优先级最高的。采用这个算法有以下的原因,
First, it supports efficient constant-time updates (an update translates to a single hash table operation), which makes it suitable for use with virtualized environments where a centralized controller may add and remove flows often, sometimes multiple times per second per hypervisor, in response to changes in the whole datacenter. Second, tuple space search generalizes to an arbitrary number of packet header fields, without any algorithmic change. Finally, tuple space search uses memory linear in the number of flows. -
使用OpenFlow作为编程模型,Open vSwitch使用 proactive flow programming的方法。具体[1].
0x02 Flow Cache的设计与Cache失效
Open vSwitch的流缓存设计:
-
Microflow Caching,开始的时候为了实现更加好的性能,转发的逻辑都实现在内核里面,都是对内核模块进行更新是很麻烦的。所以这里就讲内核模块重新实现为一个microflow cache,也就是说具体的逻辑还是会是现在一个普通的进程之中,
This allowed radical simplification, by implementing the kernel module as a simple hash table rather than as a complicated, generic packet classifier, supporting arbitrary fields and masking.另外通过多种的优化手段,减少microflow cache机制下的流建立的时间,例如批建立、使用线程等。
-
Megaflow Caching,上面的方法在很多的情况下都很不错,但是在大量的短连接的情况下,这个性能就下降明显。为了解决这个问题提出的新方案就是Megaflow Caching,
The megaflow cache is a single flow lookup table that supports generic matching, i.e., it supports caching forwarding decisions for larger aggregates of traffic than connections.
Cache失效
在一些情况下,Open vSwitch需要对缓存的内容进行更新。在一些情况下,处理可能的改变也是一件很复杂的事情,这Paper中有一大段论述了这些情况[1].
0x03 Cache敏感的包分类器
这里的就是对前面描述的基本的分类的算法的在流缓存的情况的优化,另外在Open vSwitch的匹配中为了避免一些错误,Open vSwitch倾向于匹配超过需要的字段:
-
元组优先级排序;这是一种试图提前终止匹配操作的方法,通过对一个元组中存在最高优先级的T.pri_max来排序。
function PRIORITYSORTEDTUPLESEARCH(H) B ← NULL /* Best flow match so far. */ for tuple T in descending order of T.pri max do if B z1= NULL and B.pri ≥ T.pri max then return B if T contains a flow F matching H then if B = NULL or F.pri > B.pri then B←F return B -
Staged Lookup,分阶段查找。由于匹配的操作必须是匹配使用的为,这里通过讲匹配操作分阶段来减少查找的空间,
... statically divides fields into four groups, in decreasing order of traffic granularity: metadata (e.g., the switch ingress port), L2, L3, and L4. We changed each tuple from a single hash table to an array of four hash tables, called stages: one over metadata fields only, one over metadata and L2 fields, one over metadata, L2, and L3 fields, and one over all fields. (The latter is the same as the single hash table in the previous implementation.) -
Prefix Tracking,…..[1]
-
Classifier Partitioning,基本的思路就是跳过不需要的匹配。
0x04 评估
这里的具体信息可以参看[1]。
参考
- The Design and Implementation of Open vSwitch, NSDI’15.
