Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization
0x00 引言
Andromeda是Google的云平台的网络虚拟栈,是Google网络技术方面的几个创新之一。这篇Paper发表在NSDI‘18。刚好NSDI’18上面也有微软关于云平台上面网络栈的一篇Paper。这两篇体现出来的是完全不同的思路。前面看过的微软的论文[2]重点是利用一些新型的硬件如FPGA,而Google强调的是基于软件的架构。
... We describe the design of Andromeda and our experience evolving it over five years. Taken together, we have improved throughput by 19x, CPU efficiency by 16x, latency by 7x, and maximum network size by 50x, relative to our own initial production deployment.
这篇Paper整体看下来还是不少雾水,emmmmmmm。
0x01 概述
一些Andromeda的设计目标,
- 必须就像一个完整的隔离的环境一样;
- 必须可以进持续的功能升级,支持这样一些功能:账单, DoS保护, tracing, 性能监控, 和 防火墙等;
- 能够快速定位错误,满足可用性的指标;
- 可操作性,比如支持虚拟机迁移这样的功能;
-
量化的control plane可拓展性,满足快速增长的需要;
Andromeda的基本架构如下图。数据面和控制面的设计都采用层次化的设计,控制面会保存这个网络中的每一个VM的信息和其他的一些高层次的信息,比如防火墙,负载均衡器和路由策略等的信息。控制面的设计围绕着一个全局的层级和一个总体的云集群管理层。数据面有一组用户空间的包处理路径组成,VM host Fast Path是数据面层级结构的第一的路径,它的目标就是在保持灵活性的基础上实现原始的性能。The Fast Path要求300ns处理一个数据包,这样久要求The Fast Path的复杂度要低,处理的事情也不能太多,这样就只能处理要求高性能、低延迟的流,对于其它的流,Andromeda会转发给 Hoverboards 或者是 Coprocessors做其它的处理,
On-host software Coprocessors running in per-VM floating threads perform per-packet work that is CPU-intensive or without strict latency targets. Coprocessors decouple feature growth from Fast Path performance, providing isolation, ease of programming, and scalability.
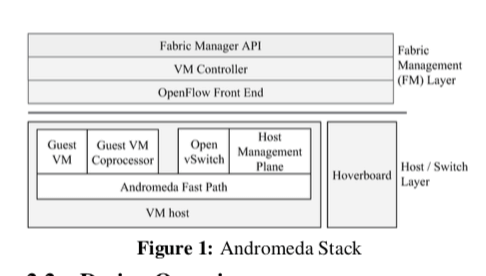
0x02 控制面(Control Plane)
Andromeda的控制面主要有3部分组成,Cluster Management (CM) Layer,Fabric Management (FM) Layer以及Switch Layer,
-
CM Layer,代表了用户的存储、网络和计算的资源,这篇Paper不会设计到这个部分,emmmm;
-
FM Layer,暴露一个high-level的API给 CM Layer,当CM连接到FM控制器时, FM的配置有CM发送,FM配置由一组具有已知类型、唯一名称和定义实体属性的参数的实体组成,下面是一些例子。
Network: QoS, firewall rules, . . . VM: Private IP, external IPs, tags, . . . Subnetwork: IP prefix Route: IP prefix, priority, next hop, . . .FM API 有一组不同的控制器组成,不同的控制器负责不同的功能。这里 VM Controllers (VMCs)控制VM hosts和Hoverboards,而负载均衡控制器控制负载均衡。VMCs使用OpenFlow和其的一些功能拓展来编程VM host交换机,VMCs发送的OpenFlow请求是通过OpenFlow Front Ends (OFEs) 代理完成的,这样做是为了将控制器的架构和OpenFlow的协议分离。另外,OFEs会将交换机的事件发送给VMC由它来处理。每个集群中有多个的VMC分区,通过一致性hash的方式来决定负责这个集群中主机的一部分。
-
Switch Layer,VM hosts和Hoverboards的路由处理有Switch处理,Andromeda使用一个基于修改的Open vSwitch。
对于Andromeda这类的系统而言,处理数据转发的问题是一个核心。在处理转发的模型上面,Andromeda讨论了几种模型,1. Preprogrammed Model,使用预定义的规则,这种方式的好处就是性能比较好,表现也很稳定,但是这种方式的缺点就是拓展性比较差,另外就是灵活性比较差。2. On Demand Model,这里使用一个额外的Controller来定义规则,在一个流的第一个包达到的时候,Andromeda向Controller询问转发规则。这样的好处就是灵活性很好,缺点就是第一个包会有很多的延迟。3. Gateway Model,将某些特殊类型的包发送给一个Gateway Service,这个设备专门为高速的包处理设计,缺点就是Gateway需要的书随着网络利用率增长而增长,这样就需要保留能够满足最高带宽要求的Gateway(具体是个什么情况不是很清楚,emmmm)。 开始的时候,Andromeda的时候使用的是Preprogrammed模型。之后为了解决Preprogrammed模型存在的问题,Andromeda引入了Hoverboard模型。Hoverboard模型是一种结合了On Demand Model和Gateway Model的模型。模型的情况下,使用一个Hoverboard来转发这些数据包,如果Andromeda发现一个流的使用指标超过来一个阈值的时候,就使用直接转发的方式,
The Andromeda VM host stack sends all packets for which it does not have a route to Hoverboard gateways, which have forwarding information for all virtual networks. ... the control plane dynamically detects flows that exceed a specified usage threshold and programs offload flows, which are direct host-to-host flows that bypass the Hoverboards.
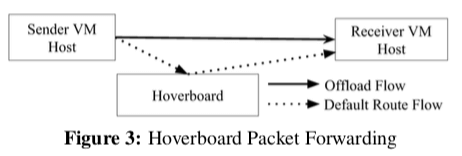
Andromeda基于软件的方式可以实现比SR-IOV更高的灵活性。一个例子就是透明的动态迁移。Andromeda这里只是简单的说了一句基本的思路,就是在迁移的时候使用流“分叉”的方式,
... The migration source will hairpin any ingress packets intended for the migrating VM by forwarding the packets to the migration destination. After blackout ends, other VM hosts and Hoverboards are updated to send packets destined for the migrated VM to the migration destination host directly.
0x03 VM Host Dataplane
Andromeda另外一个主要的部分就是数据面了。Andromeda这里使用了两种处理路径:一个是Fast Path,用于实现数据包的快速处理,一般只负责封装包和根据Flow Table来转发这类的工作。另外一个是Coprocessor Path,这个Path可能还要进行加密之类的操作,一般用于负责处理CPU密集型、对延迟不敏感的任务。
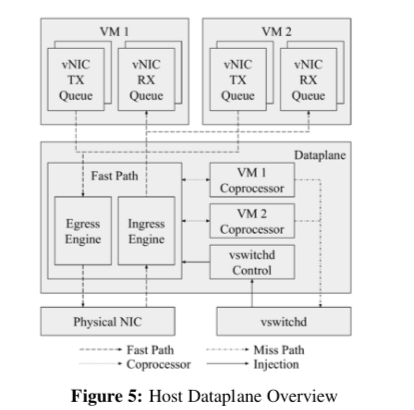
Fast Path
Fast Path的追求就是高性能。Andromeda在这里使用了几个原则。一个如前文所言,让Fast Path尽可能地处理少的任务。另外一个就是利用一些硬件提供的功能,把一些操作下放到这些硬件上完成,比如利用Intel QuickData DMA Engines技术。在Fast Path实现的时候采用的一些优化策略,
... avoid locks and costly synchronization, optimize memory locality, use hugepages, avoid thread handoffs, end-to-end batching, and avoid system calls. For example, the Fast Path only uses system calls for Coprocessor thread wakeups and virtual interrupts.
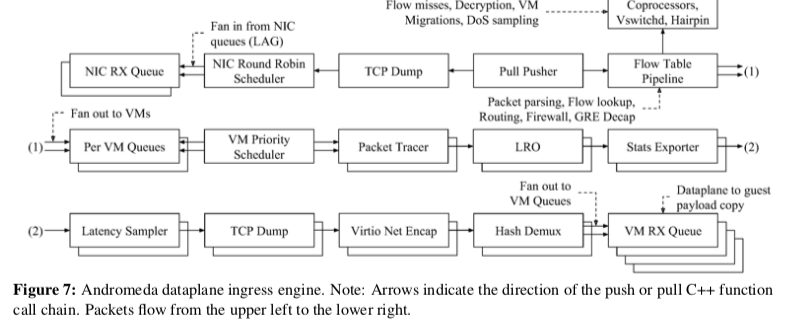
Fast Path的架构类似于Click一样,有一些可重用的Elements组成。这里也利用了批量处理这种很常用的方法。这些Elements可以采用Pull或者是Push的方式。Fast Path分为egress 和 ingress两个Engine,下图是ingress的一个示例图。
Coprocessor Path
Coprocessor Path则用于处理一些“脏活累活”,也是Fast Paht能够实现minimizing Fast Path features的一个关键。对于不断往Andromeda中添加的性能,为例避免这些不断增长的功能影响到了Fast Path的性能。Coprocessor Path将这些复杂的功能和Fast Path解耦开来。
0x04 评估
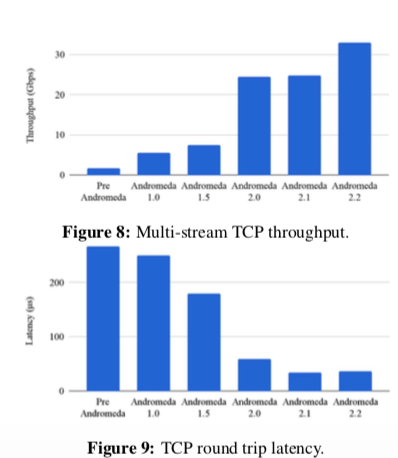
这里具体的信息可以参看[1]。Andromeda在这些版本中添加的优化手段,
Andromeda 2.0 consolidated prior VMM and host kernel packet processing into a new OS-bypass busy-polling userspace dataplane... The VMM exchanged packets with the dataplane via SPSC shared memory rings. The dataplane maps in all VM memory, and directly copies packet to/from VM memory.
Andromeda 2.2 uses Intel QuickData DMA Engines to offload larger packet copies, improving throughput. DMA engines use an IOMMU for safety and are directly accessed by the dataplane via OS bypass. Tracking async packet copies and maintaining order caused a slight latency increase over Andromeda 2.1 for small packets.
参考
- Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization, NSDI’18.
- Azure Accelerated Networking: SmartNICs in the Public Cloud, NSDI’18.
