Azure Accelerated Networking: SmartNICs in the Public Cloud
0x00 引言
Azure Accelerated Networking (AccelNet)是微软的一个基于FPGA的网络栈(host SDN stack)的一个解决方案,
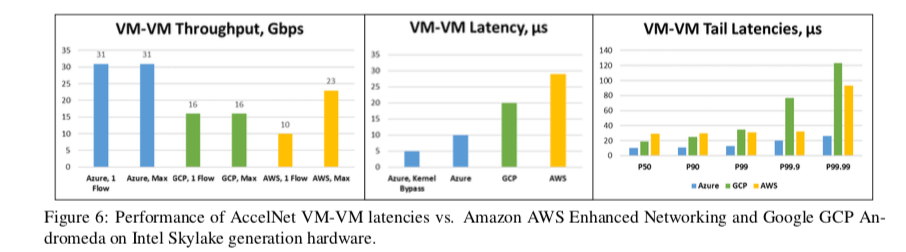
The AccelNet service has been available for Azure customers since 2016, providing consistent < 15μs VM-VM TCP latencies and 32Gbps throughput, which we believe represents the fastest network available to customers in the public cloud.
看这篇Paper要先看看其他的一些Paper,卒。
0x01 设计目标与原因
微软在设计它的host SDN的时候主要一下的一些考虑和目标:
- Don’t burn host CPU cores,不能消耗太多的主机的CPU核心。云平台的IaaS服务直接出售VMs给用户,消耗的CPU核心就是这篇网络栈的成本;
- Maintain host SDN programmability of VFP,Virtual Filtering Platform (VFP)是微软在它的云平台中使用的一个可编程的vSwitch,可以提供可拓展的SDN策略。可编程性使得器可以灵活的运用路由规则;
- Achieve the latency, throughput, and utilization of SR-IOV hardware,使用SR-IOV的硬件虚拟化方式的技术实现低延时、高吞吐和高效利用的一个重要方式;
- Support new SDN workloads and primitives over time,能不断地适应性的需求和变化;
- Rollout new functionality to the entire fleet,和前面的一些要求有联系。既然要能适应不断的变化,也就不能只能在一部分的硬件上面使用,比如只能在最新的硬件。这个是对用户很不友好的一种方式。
- Provide high single-connection performance,在一般的基于软件的SDN,单个CPU核心处理的带宽很难超过40Gb,而AccelNet要求能够处理这样基本的带宽;
- Have a path to scale to 100GbE+, 要有能力区去实现超过100GbE+的处理能力;
- Retain Serviceability,可以理解为要用起来要方便舒服,不能台难用;
0x02 SmartNIC的硬件设计
基于上面的要求,在比较了多种的硬件之后,微软选择了使用FPGA来实现它们的一些功能。微软在FPGA上面已经进行了很多的研究。Paper中有一大段的关于FPGA是如何适合处理这些问题[1],这里就不Care这些了。
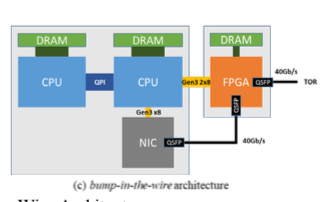
微软的SmartNIC的一个基本的架构如上面的图。微软选用的方式是使用FPGA作为现有的NIC的一个功能的增强。如上面的图所示,这里NIC和FPGA是在不同的板子上面的NIC通过FPGA和ToR交换机相连,另外FPGA本身页通过PCIe和CPU相连,
The FPGA is also connected by 2 Gen3x8 PCIe connections to the CPUs, useful for accelerator workloads like AI and web search. When used as an accelerator, the network connection (along with an RDMA-like lossless transport layer using DCQCN) allows scaling to workloads such as large DNN models that don’t fit on one chip.
上面的方式是第一代的做法,在第二代上面处理速度的加快之外,由SR-IOV功能的NIC和FPGA集成到了一块的板子上面,消除了额外NIC的板子和一些连线。
0x03 AccelNet系统设计
AccelNet控制面的设计基本上就是采用了VFP的设计,VFP的详细信息在论文[2]中。对于数据面的设计,会被加载到FPGA SmartNIC上,NIC的驱动添加了一个filter driver叫做GFT(Generic Flow Tables (GFT)) Lightweight Filter (LWF),用于使得NIC/FPGA的组合硬件看起来就是一个单一的NIC一样。
软件设计
大部分的包处理的工作在SmartNIC中都会交给FGPA硬件来处理,软件的部分复杂一些控制性的操作,比如流的建立与拆除、健康监控、serviceability等内容。一个基本的结构图如下,
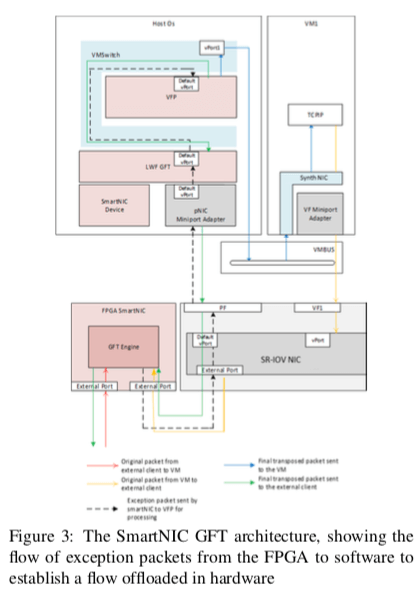
SmartNIC的另外的一些设计:
- FGPA流水线的设计,GFT在FPGA上面的实现分为两条数据流向相反的流水线,每条的结构是一样的。分为4个阶段:1. 一个存储转发的buffer,2. 一个parser,3. 流查找和匹配单元,4. 流动作。Parser解析包中的header的信息,决定采取的一些动作,这个同时支持L2/L3/L4 headers的处理(9 headers total, and 310 possible combinatons),Match是处理的第三个阶段,通过查找前一阶段回去的信息查找匹配的规则,
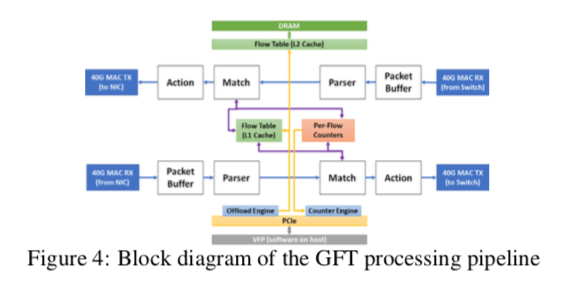
- …[1]
0x04 经验
AccelNet对于前面的一些目标的一些实现:
1. We stopped burning CPU cores to run the network datapath for AccelNet VMs. Host cores show less than 1% utilization used for exception processing.
2. SDN controllers have continued to add and program new policy in VFP, agnostic of the hardware offload now underneath.
3. We measured the overhead of the FPGA on latency as <1μs vs our SR-IOV NIC alone, and achieve line rate. This is much better than CPU cores alone.
4. We’vecontinuedtoaddnewactionsandprimitivesto GFT on the FPGA to support new workloads, as well as new QoS primitives and more.
5. Changes have been rolled out across multiple types of servers and SmartNIC hardware.
6. We can achieve line rate on a single connection.
7. We believe our design scales well to 100Gb+.
8. We have done production servicing of our FPGA image and drivers regularly for years, without negatively impacting VMs or applications.
0x05 性能表现
这里具体的信息可以参看[1].
参考
- Azure Accelerated Networking: SmartNICs in the Public Cloud, NSDI’18.
- VFP: A virtual switch platform for host SDN in the public cloud, NSDI‘17.
