Building a Bw-Tree Takes More Than Just Buzz Words
0x00 引言
Bw-Tree是Microsoft Research发明的一种lock-free(在数据库中应该叫做latch-free)的数据结构,被用在Microsoft的内存数据库产品中,在CMU的学术型数据库peloton中也采用了这种数据结构。这篇paper就是CMU对其在peloton中实现中,对Bwtree的一些更加详细的讨论。从paper中得出的结论来说,Bwtree是有复杂而且在不少方面表现却比一些更加简单的、非lock-free的数据结构要差。 关于 Bwtree的论文之前有两篇, 不过这篇是讲的最清晰的。
0x01 基本结构
先来看一张图:
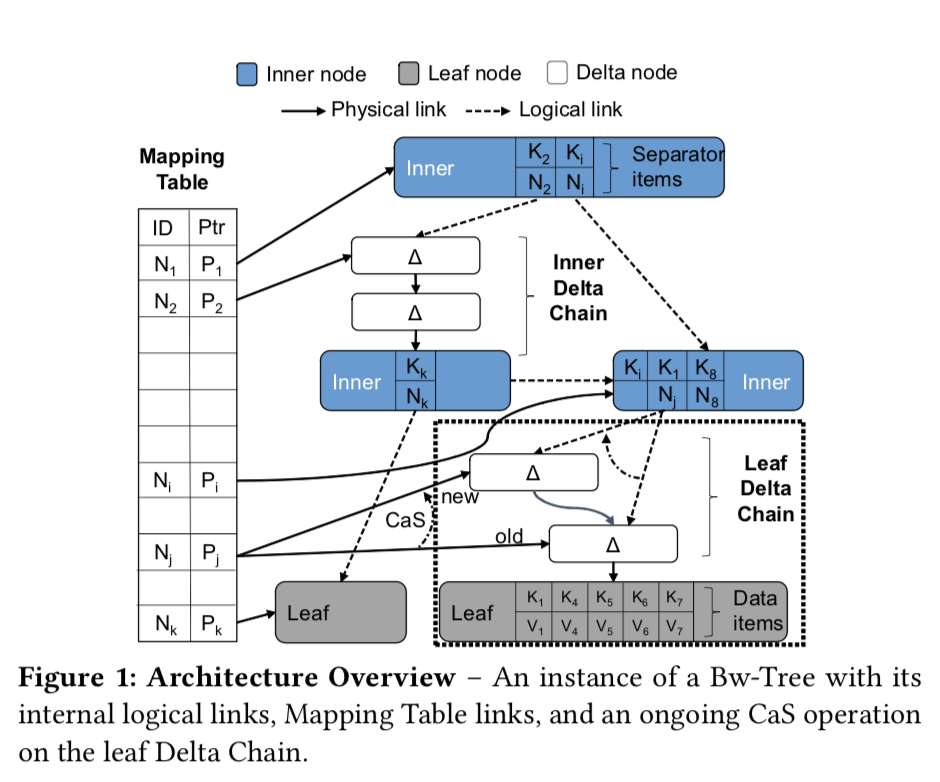
Bwtree的4个核心内容:
Base Nodes and Delta Chains
以目前的硬件,由于没有支持多CAS的(有软件的实现,之后在看看, ^_^)。所以直接修改B+tree的节点来实现lock free是不太行的通的。所以Bwtree使用了 Delta Chains的方法, Delta Chains实际上就是一个对节点修改的操作的链表。实现lock-free的链表相对来说简单多了。当这个 Delta Chains长度达到一定程度的时候,就利用这个 Delta Chains和原来的base node构造新的node,替换原来的node。这样通过一系列的操作转换,巧妙的将其转换为了lock free的结构。
Mapping Table
在原来的论文中,Mapping Table 的存在不仅仅是为了将更新node变为lock free的,还有为这个结构同时支持memory和SSD之类的多级存储的功能。在这篇文章中只在意在内存中(因为peloton是一个内存数据库).
The Bw-Tree’s centralized Mapping Table avoids these problems and allows a thread to update all references to a node in a single CaS instruction that is available on all modern CPUs.
...
Although this paper focuses only on in-memory behavior of the Bw-Tree, it is worth emphasizing that the mapping table also serves the purpose of supporting log-structured updates when deployed with SSD. Updates to tree nodes will otherwise propagate to all levels without the extra indirection provided by the Mapping Table.
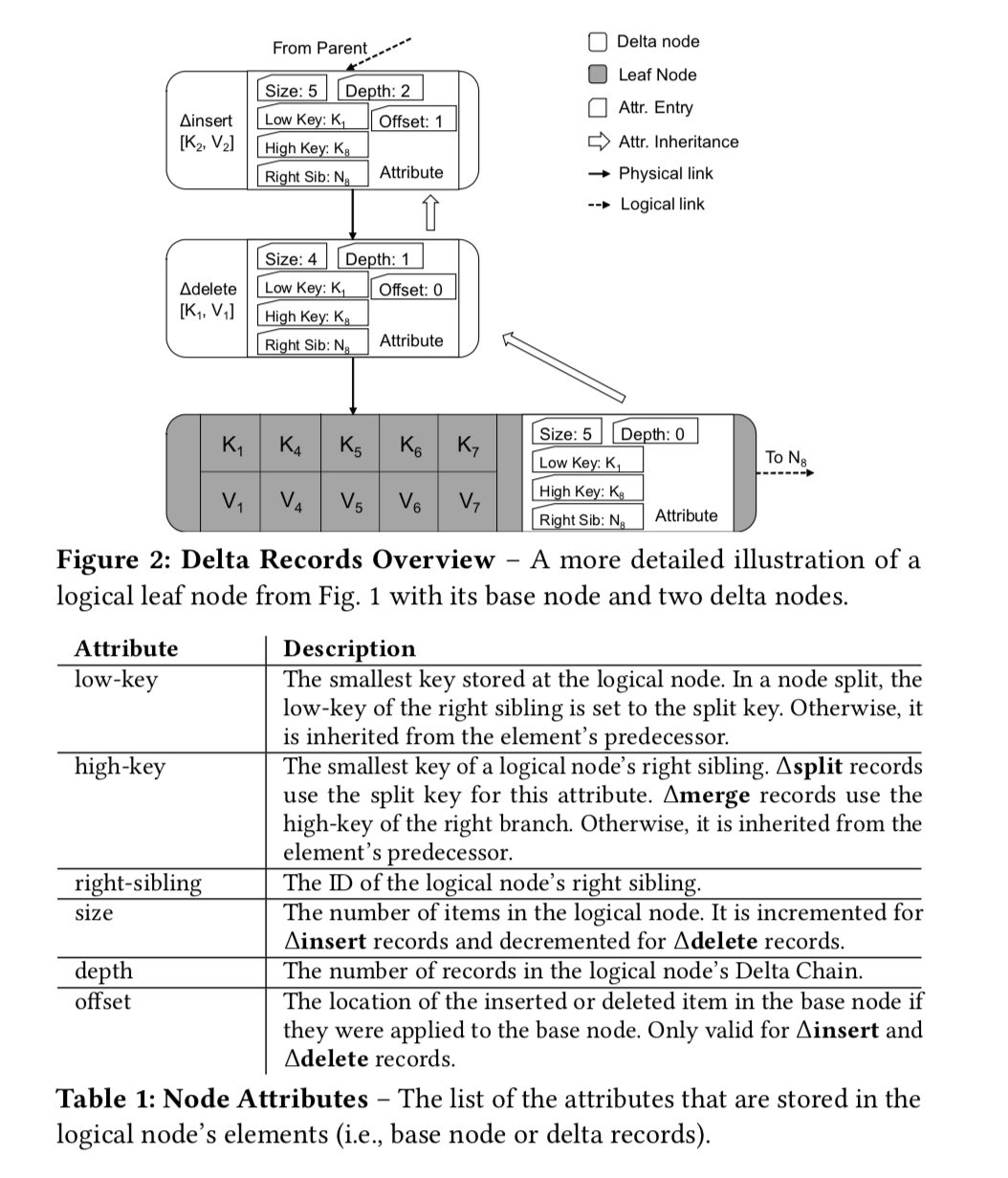
Consolidation and Garbage Collection
Delta Chains和Base Node构成了Bwtree中一个Node的数据,随着数据更新,这个Delta Chains的长度是不断增长的,这样就需要将Delta Chains和Base Node合并为一个新的Node,并回收不在使用的数据。
At the beginning of consolidation, the thread copies the logical node’s base node contents to its private memory and then applies the Delta Chain. It then updates the node’s logical link in the Mapping Table with the new base node.
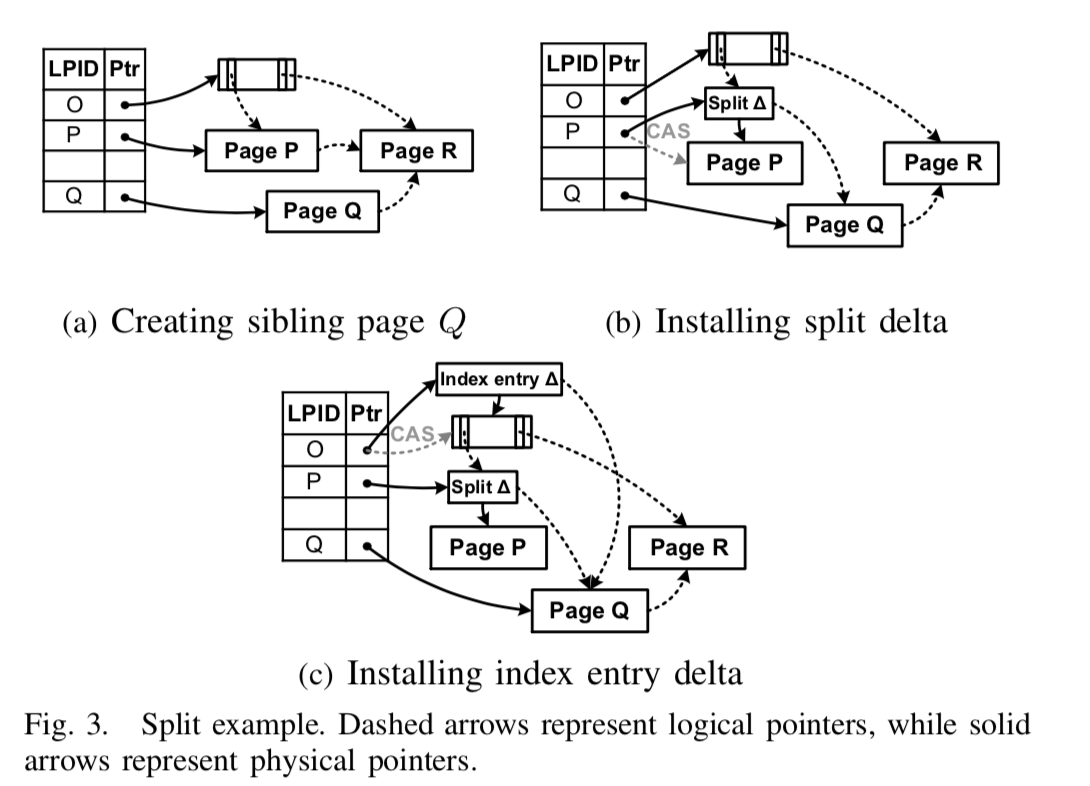
Structural Modification(SMO)
为了使Bwtree是lock free的,SMO的操作被分为了几个步骤:
- 在 Delta Chains中插入一个特殊的 Delta表明这个Node在进行SMO操作,其它线程就将更新的操作insert到一个虚拟的节点。
-
下一步就是一个线程(不一定是第一步中的线程),完成node的SMO操作之后,使用CaS将虚拟节点更新为新节点。
给一幅[2]中的图,看着就不是很好玩:
0x03 MISSING COMPONENTS
原bwtree paper将的也确实很含糊,缺少了不少东西,这篇论文补齐了不少,主要包含了一下几点:
- Non-unique Key Support
- Iteration
- Mapping Table Expansion 。具体的讨论可以查看[1].
0x04 优化
实现上的优化对性能的影响也是很大的:
We present our optimizations for the OpenBw-Tree’s key components to im- prove its performance and scalability. As we show in Section 5, these optimizations increase the index’s throughput by 1.1–2.5× for multi-threaded environments.
Delta Record Pre-allocation
Delta Chain 是Bwtree设计的一个核心,原论文的设计使用一个链表,而这里的优化是直接使用一个大的chunk,提前给Delta Record 分配空间。带来的好处减少了对象的分配,另外可以将这些数据放在一块就更加缓存友好,缺点是增加的内存的使用。
Each chain also maintains an allocation marker that points to the last delta record or the base node. When a worker thread claims a slot, it decrements this marker by the number of bytes for the new delta record using an atomic subtraction. If the pre-allocated area is full, then this triggers a node consolidation.
Garbage Collection
在最近大的一些类似的数据结构 or 数据库 or key-value的设计中,epoch-based GC scheme 可以说是非常常见了。关于这个算法,想了解的话看一看[2]也是很不错的。 先看一幅图:
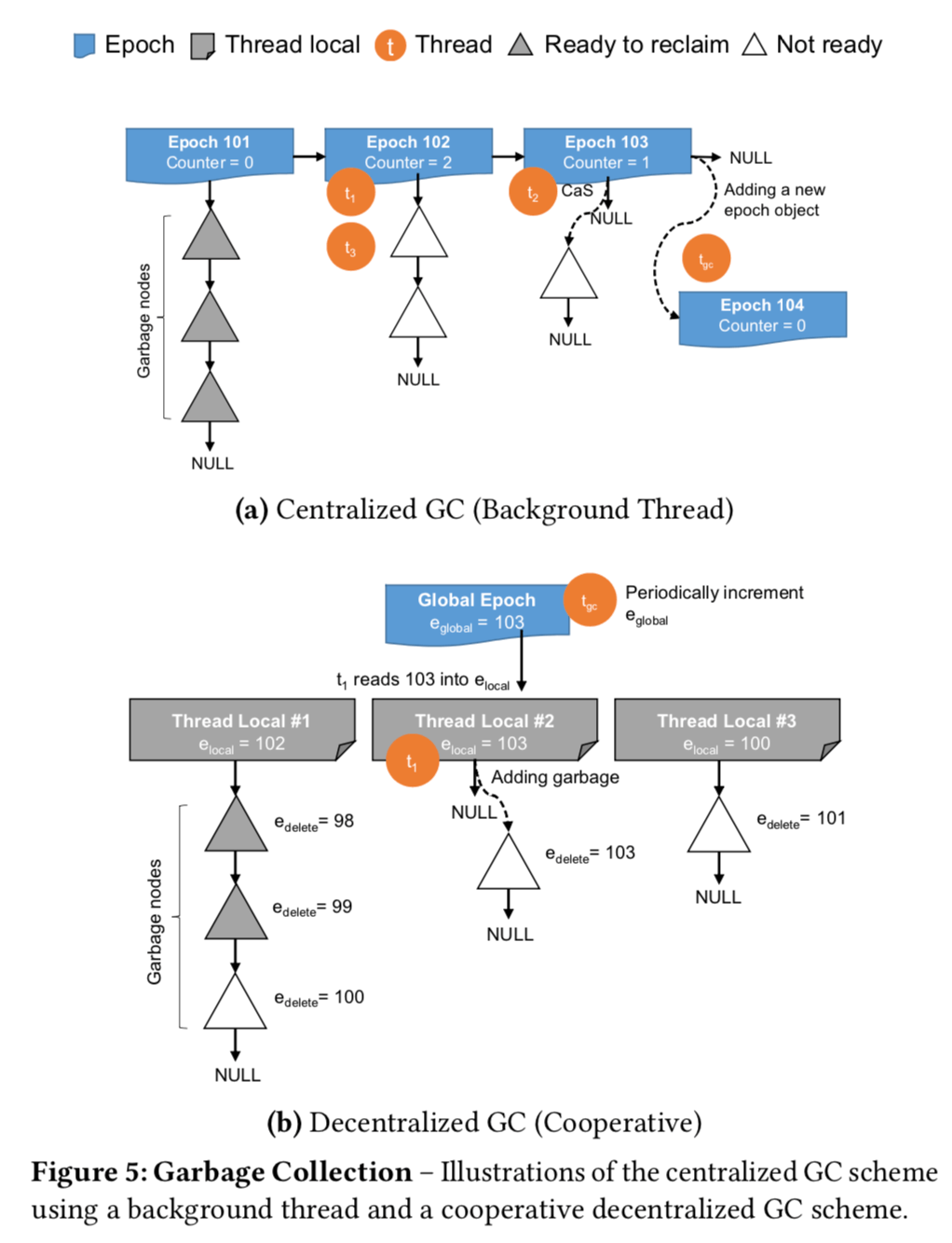
在这个方法中,index保存了一个全局的epoch objects 的list,每隔一个固定的时间间隔,比如40ms,在这个list后面添加一个新的epoch object。线程进行操作的时候,必须在当前的epoch object注册,当操作完成的时候,要把自己从的注册消除。这样,GC线程就知道什么时候可以安全的回收某一块内存了。
Centralized GC 的模式会造成一些访问冲突,为了解决这个问题,这里使用了decentralized GC 的方式,避免写全局的内存。具体的方法是依然有一个a global epoch (e-global) 。此外,每个线程保存了a private epoch (e-local) 和一个保存了指向已经删除对象指针的list。一个线程产生垃圾的时候,添加一个指向这个垃圾的指针,同时用e-global 标示e-local,当操作完成的时候,再执行这个步骤,如何开始GC。这个线程取回从其它线程所有的e-local,然后在在自己的list中找到这样的objects,这些的对象的l-local 标志的epoch比最小的e-local还要小,这些objects就是可以安全回收的。
Fast Consolidation
前面提到的node consolidation scheme模式在write-heavy workloads 的case下成本会很昂贵。 faster consolidation algorithm 这要是减少了sort的overhead。 基本的想法是不使用sort,而是使用merge的方式,这样的话一次归并的操作就可以了。避免了一些可能比较昂贵的操作。此外还加上利用具体的细节还是挺多的:
a two-way merge combines ∆insert records and segments from the old base node into the new base node.
根据Delta Chain对base node数据造成的更改,可以将base node分为一些segments,这些segments里面没有insert or delete的操作。Delta Chain中insert的数据和这些segment就可以看作是两个部分的归并操作了。
• Rule #1: For an inserted item, an existing segment [s ,e ) is broken into the segments [s ,offset) and [offset,e ).
• Rule#2: For a deleted item,an existing segment[s,e)is broken into the segments [s, offset) and [offset +1, e).
• Rule #3: However, if a delete delta removes an item that does not exist in the base node (i.e., deleting an item that is newly inserted by an earlier delta), the thread ignores this deletion.
Node Search Shortcuts
这里使用了micro-indexing 的方法来优化,一个thread traverses a Delta Chain 的时候,先初始化一个一个二分查找的访问[min, max], 当这个thread 发现 ∆insert or ∆delete record, key为 K ′,如果K = K‘,这个range就立即被设施为[offset, offset ],这里的offset是K‘这条的记录中保存的offset(offset的具体含义参考前面的table 1),如果offset > min, K > K’, 则 min = offset, 如果offset < max, K < K’,则max = offset。不够要注意的是,non-unique的结构里面的话可能存在一些Key为K的数据,这样的情况下,会忽略offset属性。
0x05 评估
论文对各个方面的评估很详细,这里只给出一个最综合的一个:
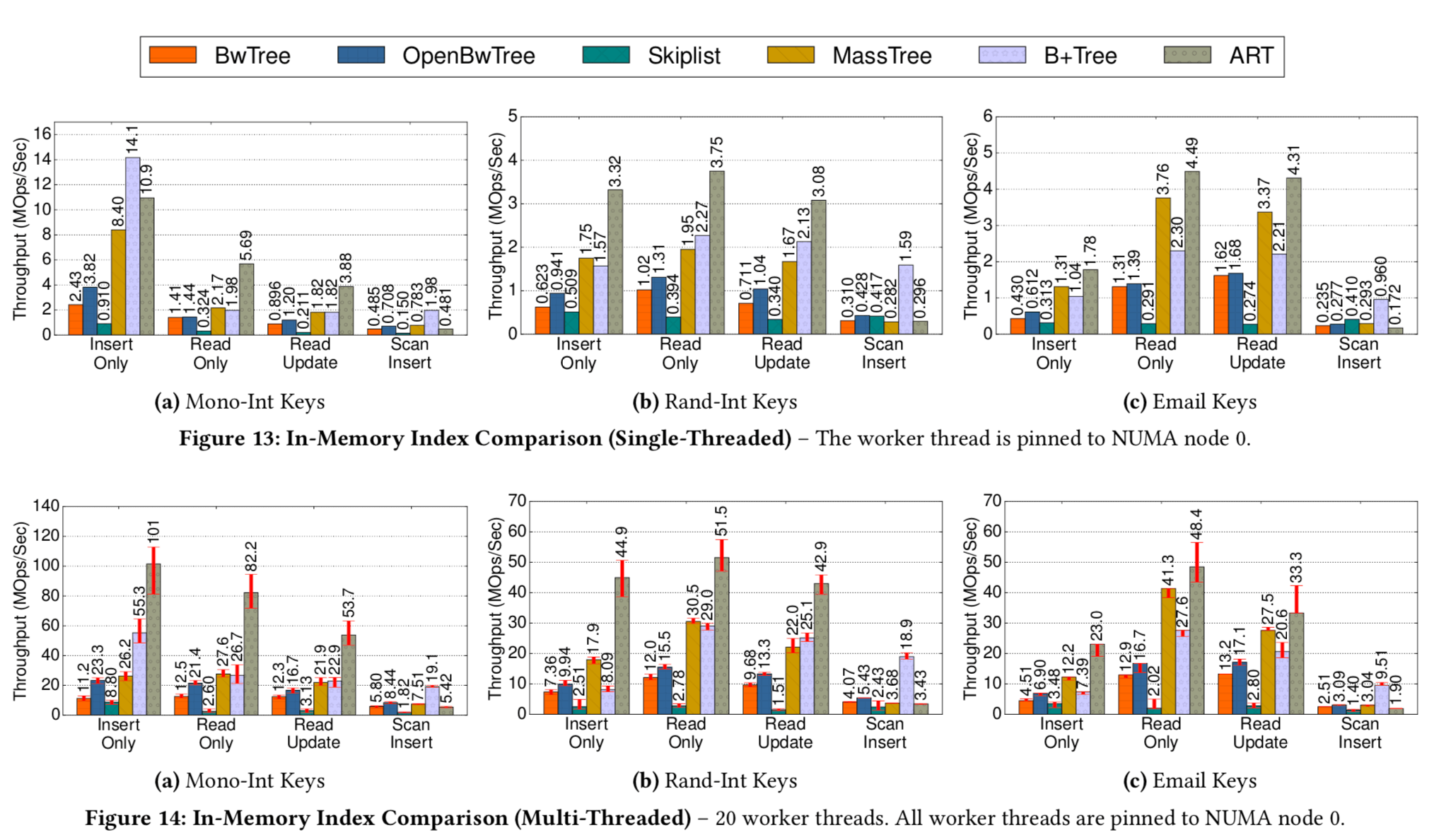
Emmmm,看上去不是很好看。Bwtree以很高的操作复杂程度(不是复杂度),确得到了一个不怎样的结果。费力不讨好,根据为了做到lock free把结构搞得很恶心:
Nevertheless, even our optimized OpenBw-Tree, is still considerably slower than other state-of-the-art in-memory index structures like SkipList, Masstree and ART. OpenBw-Tree is also slower than a B+Tree that uses optimistic lock coupling, which indicates that lock-freedom does not always pay off in comparison with modern lock-based synchronization techniques.
参考
-
Ziqi Wang, Andrew Pavlo, Hyeontaek Lim, Viktor Leis, Huanchen Zhang, Michael Kaminsky, and David G. Andersen. 2018. Building a Bw-Tree Takes More Than Just Buzz Words. In Proceedings of 2018 International Conference on Management of Data (SIGMOD’18). ACM, New York, NY, USA, 16 pages. https://doi.org/10.1145/3183713.3196895 .
-
Comparative Performance of Memory Reclamation Strategies for Lock-free and Concurrently-readable Data Structures,2005。
-
The Bw-Tree: A B-tree for New Hardware Platforms, ICDE 2013.
