Cicada: Dependably Fast Multi-Core In-Memory Transactions
0x00 引言
这篇paper是关于一个内存数据库MVCC实现的文章。在读这篇paper之前,最好读一下[2]。这篇文章基本就是从[2]中提到方面进行设计的。Cicada是最近的一些关于MVCC在内存数据库中的优化的很全面的一篇了,Paper应用了很多种的优化方法,取得了比其它类似的一些系统明显的优势,
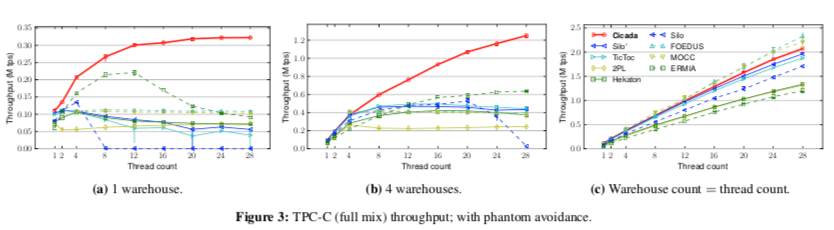
On the TPC-C and YCSB benchmarks, Cicada outperforms Silo, TicToc, FOEDUS, MOCC, two-phase locking, Hekaton, and ERMIA in most scenarios, achieving up to 3X higher throughput than the next fastest design. It handles up to 2.07 M TPC-C transactions per second and 56.5 M YCSB transactions per second, and scans up to 356 M records per second on a single 28-core machine.
0x01 基本思路
Cicada的 执行流程图:
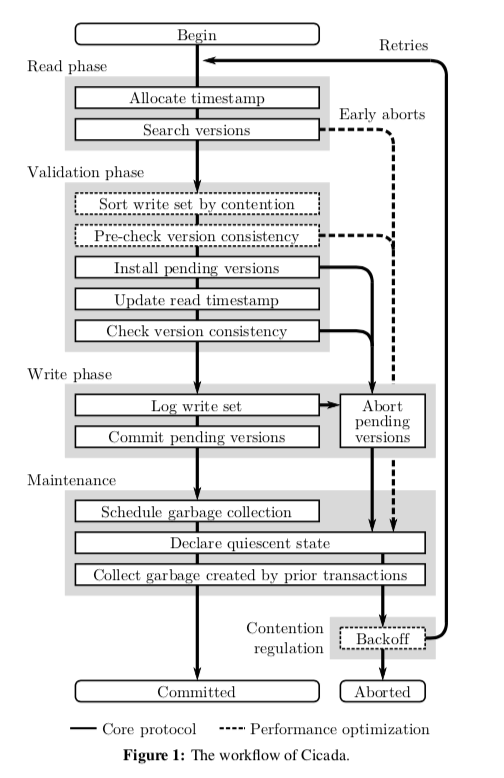
Cicada借鉴了很多OCC的执行方式,可以看作是带有OCC思想的一种MVCC的变体。接下来的部分基本就是按照上面的流程图来一一介绍Cicada使用的优化思路。
0x02 Multi-Clock Timestamp Allocation
在一个txn开始的时候,Cicada就会赋予这个txn一个timestamp(这里很多的OCC采用的方式就不同,它们分配时间戳的时间更加”靠后“,并非一开始就分配)。Txn用这个timestamp决定哪一个版本的数据是应该被使用的,以及用这个来确定txn的顺序。TicToc[3]里面就提到如何解决在txn处理速度非常高时timestamp分配对性能带来的影响。 由于在Ciacda中,事务操作的第一步如上面的流程所示就是分配一个时间戳,Cicada使用了Loosely Synchronized Software Locks的方式来解决在高并发执行事务的时候分配时间戳带来的Overhead。基本的思路是通过使用多个时钟,Cicada中的每一个工作线程会持有一个本地的64bit的时钟,在每一次分配时间戳的时候会增加这个值。Cicada使用硬件提供的Time Stamp Counter来测量在一个(CPU)核心上面流逝的时间,
- Cicada的一个时间戳由三个部分组成,一个是本地的时钟,一个是Clock Boost,另外一个是ThreadID。前两个值相加去低56bit 接上 8bit的ThreadID即一个事务使用的时间戳(这里的bit数量是可以调整的);
- 由于Cicada时间戳使用的是每一个核心的时间戳,时钟偏斜的现在难免会存在。Cicada使用周期地选择一个其它的线程里面读取时钟信息,如果另外线程的时钟走地更快,将本地时间更新为这个时钟的信息。Cicada使用的周期为100us,是一个比较短的时间。这种方式称之为 One-sided Synchronization(单向同步);
- Clock Boost也是一种解决时钟偏斜的临时性的方法。在一个事务因为数据冲突abort的时候,Cicada设置这个Clock Boost的值大于在单向同步之后可能出现的偏斜的值,在Cicada的实现中选择了1us。在这个事务提交之后这个值会被重新设置为0;
- 在Cicada中,每一个线程会保存两个时间戳的信息,一个是(thread.wts)是通过前面的时间戳生成方法生成的时间戳,(thread.rts)则是min_wts减去1。这里的min_wts是所有的线程里面(thread.wts)的最小值。min_rts则是所有线程里面(thread.rts)的最小值。一个读写事务会选择(thread.wts)作为这个事务执行的时间戳,而一个只读的事务选择(thread.rts)作为执行的时间戳;
- 在这样的一个增长的频率下面,64bit的时间戳在长时间运行的时候会有溢出的问题。Cicada的处理方式是在重新添加一个有很早时间戳的一条记录的版本,这个版本的数据和这条数据最新的版本的数据是一致的。这样的操作会是逐步进行的,避免给数据库带来大的开销。
- 在写入日志的时候,想要一个时间戳的全序的关系。Logger使用的是extended timestamps,这个还包含了一个era的信息,记录了时间戳回绕的次数;
- Cicada为了提交时间戳分配的效率,带来的一个问题就是不能保证外部一致性(external consistency)。这里和TicToc是一样的,时间戳代表的时间顺序并不能代表物理时间上面的顺序。如果想要保持外部一致性,Cicada可以通过使用推迟通知客户端一个事务已经成功提交,这个推迟的时间是等到min_wts大于这个已经提交的事务使用的时间戳(这样大概会增加100us的延迟),这样就可以保证后面执行的事务在物理意义上面的时间顺序晚于之前的事务。如果只是要求有因果一致性,则Cicada可以通过增加本地时间戳使之大于前面执行的事务的最大的时间戳;
0x03 Multi-Version Execution
Cicada使用2级的页(Page)的结构,每一个Page的大小为2MB(对应了x86平台上面一种大页的大小),一条使用record ID寻址。一个记录不同的版本被组织为一个单项链表。Cicada在这里使用Header Node Array,在这个Array里面的记录被称为Inline的数据。一般版本的数据处理数据本身之外还包含了: 1. wts表示创建这个版本数据的时间戳,2. rts表示已经提交的数据中(可能)读取这个版本的数据最大的时间戳,3. 提交状态信息(status)表示这个版本数据的有效性,4. 内存分配的信息,主要于NUMA上的优化相关。这里链表是按照wts从新到旧排序[2]。这些数据中除了rts和status字段外都是不会被更改的。一个版本的数据在验证阶段的时候被添加到这个链表中,初始的时候status字段的值为PENDING。在写入阶段,这个status会被置为COMMITTED or ABORTED(根据事务的提交的情况),UNUSED则表示这个版本的数据不会在被使用,删除一条记录的时候,通过添加一个数据长度为0、status标记为DELETED的数据表示这条记录被删除,后面会被GC机制回收。
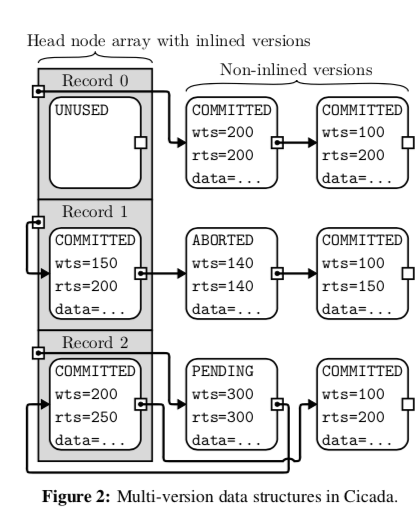
一个以tx.ts为时间戳的事务从新到旧访问一条记录的链表。在这个过程中会忽略v.wts > tx.ts、ABORTED的数据。如果status为COMMITED则为寻找的数据,如果为PENDING则直接自旋等待这个值变化(COMMITED or ABORTED)。另外,在发现要读取版本的数据有 v.rts > tx.ts的时候,Cicada的一种优化方式就是提前abort(early abort)。在read-modify-write (RMW),Cicada使用write-latest-version-only的规则,即如果这里存在另外一个版本的数据有 v′.wts > tx.ts,且status的值为COMMITTED or PENDING,当前的事务会abort。另外还使用了read-own-writes的优化方式,
... which serves existing thread-local versions when a transaction accesses the same records again . It provides consistency within a transaction by not losing earlier writes even if the application fails to reuse the pointer to the local version. Cicada finds earlier local writes using a lightweight thread-local hash table. ... If the application can ensure the reuse of local versions and/or no multiple accesses for the same record, it can instruct Cicada to bypass the duplicate access check.
0x04 Best-Effort Inlining
如前面所言,Cicada中的Inline就是将数据保存在Head Node中。这样可以避免一些间接访问带来的开销。这里的空间是预先分配的。这里对Inline的数据是有大小的要求的,在Cicada的实现中这个数据要小于216 bytes。Best-Effort Inlining的操作可能会将一个不是Inline的数据转化为Inlin的数据:当一个事务读取读取一个可见的非Inline的数据的时候,如果这个版本的数据足够早,有v.wts < min_rts且目前没有Inline的数据,Cicada会将其转移到Head Node中变为Inline的数据,不过这个操作也可以因为并发的操作而失败。这里Cicada的一个优化就是只尝试内联不频繁访问的记录,
... To avoid creating a contention point at the inlined version, promotion only optimizes infrequently- or never-changing read-intensive records. If a record is frequently written, promoting a version of such a record will incur unnecessary write overhead. If the record is never read, promotion does not provide a performance benefit;
0x05 Serializable Multi-Version Validation and Optimizations
Cicada的验证的步骤协议确保已提交的事务的执行是以事务使用的时间戳原子方式执行的。由此在Cicada中提交的事务旧等价于以事务时间戳排序的串行的计划。这个PENDING版本数据添加的步骤会阻塞使用听一个可见版本的且有更大的时间戳的事务,有更小时间戳的事务可以abort本事务or并发的使用同一个可见版本的数据的事务。同样地,如果不满足(v.rts) ≤ (tx.ts),这个事务会abort。这个步骤有3个步骤,
- Pending version installation,就是将写入集合中的数据添加到对应记录的版本链表中,这些数据的状态值为PENDING;
- Read timestamp update,在需要的时候更新数据的rts,用来确保(v.rts) ≥ (tx.ts)。
- Version consistency check,这里主要就是验证之前在读取集合中的可见版本在目前还是可见的,还有就是在写集合记录的数据版本满足(v.rts) ≤ (tx.ts)。这个步骤可以确保:1. 没有另外的一个事务写入了一个新的数据版本,从而改变这条记录可见的版本(一个事务获取时间戳的大小和在一个版本数据上执行的时间先后没有必然的关系);2. 这个事务不会提交地太早,以致于违法了依赖于对于一条记录指定版本稳定的可见效的事务执行的一致性。
在Cicada中提交一个版本的数据就是将stauts字段的值由PENDING改为COMMITTED。在abort的时候,事务会修改意见添加到版本链表中的数据的status字段的值为ABORTED。另外Cicada对这个步骤做了不少的优化,
-
Sorting the write set by contention,Cicada认为在写集合中,最新版本数据的wts越大,产生冲突的可能性越大,所以这里使用wts排序的方式,尽早暴露“冲突”。这个优化在冲突比较高的时候比较有效,冲突比较低的时候会增加额外的开销;
-
Early version consistency check,这个优化也是在冲突比较高的时候比较有效。这个优化在排序写入集合之后就进行检查,方法和核心的验证方法是一样的。这个可以避免大部分添加进去的数据成为”垃圾“。
-
Incremental version search,避免重复的版本的搜索,
... To reduce the cost of repeated search, the initial version search in the read phase remembers later_version whose wts is immediately later than (tx.ts). later_version is updated whenever a new version qualified as later_version is discovered during subsequent version search.
0x06 Indexing
在索引的设计上面Cicada使用的是索引和主存储分开的方式。所有的索引,包好Primary索引在内,都是一个单独的数据结构。这个和很多的数据按照Primary组织为索引结构、次级索引以主键为Value的方式有所不同。Cicada中所有的索引都是保存一个64bit的record ID。这里主要要解决两个问题,
-
Avoiding phantoms,这里主要就是在serializability的隔离级别下面的要求。这里Cicada使用在索引节点中页保存wts和rts的方式;
-
Low index contention,Cicada会推迟索引更新直到验证这个事务。这里同样利用了Cicada的read-own-writes机制。会abort的事务不会去修改全局的索引结构,
Low index contention is one of the beneficial side effects of unifying Cicada’s transaction processing and index validation. Unlike many modern OCC designs that modify index data structures during the read phase of the transaction, Cicada’s multi-version indexes defer index updates until validating the transaction by keeping index node writes in thread-local memory;Cicada同样保留了single-version indexes的支持(估计是直接使用指针,Paper中没有说明)。可以减少内存范围的次数,但是可能会增加冲突。
0x07 Durability and Recovery
Cicada使用的Log的方法和在SiloR中使用的方法是很类似的。Log也是使用大量的硬件来实现快速的Log和恢复。写入Log也是日志线程完成的,为例平摊每一个事务日志写入的Overhead,也可以使用组提交的方式。如果直接使用非易失性内存之类的存储介质,则可以直接写入日志而不用使用组提交的方式,因为这个会增加延迟。Checkpoints的设计也和SiloR的类似,通过Checkpointer线程完成,
Checkpointing virtually partitions each table. For each record in a partition, checkpointers store the latest committed version in per-thread checkpoint files. This process happens asynchronously without taking locks. For safe memory access, checkpointers participate in maintaining min_rts; they frequently update (thread.rts) to avoid hindering min_rts increments.
另外的,Cicada也可以支持一些transaction-consistent checkpointing的方式,这里主要就是直接参看之前早SIGMOD上面的两篇论文[4,5]。
0x08 Rapid Garbage Collection
Cicada使用更加频繁的垃圾回收策略,以此来避免较长时间间隔的垃圾回收周期带来的内存消耗。Cicada使用一种epoch-based reclamation (EBR)和quiescent-state-based reclamation (QSBR)的变体来进行频繁的垃圾回收。工作线程会记录最近一次事务提交的新版本数据的元数据。新版本的数据意味着有旧版本的数据会变成垃圾。对于这里面的每一个版本v,这个线程会保存指向这个版本的指针和wts。线程会每隔一段时间声明一个quiescent state(Cicada使用了10us的间隔,和其它的一些类似的系统相比这个是一个很短的时间了)。一个leader线程看到了所有的线程都声明了之后单调地更新 min_wts 和 min_rts。之后,工作线程基础本地保存的信息,如果有一个版本的数据满足v.wts <min_rts,则可以进行回收操作。 另外Cicada支持多个线程并发回收,由于多个线程可能回收相同的数据,这里要处理并发的问题,
... Cicada maintains a small per-record data structure containing a garbage collection lock and the minimum write timestamp (record.min_wts), separate from the main record metadata (the head), which is prefetched while creating a new garbage collection item for the record. The thread performs garbage collection for a committed version v if (a) acquiring the garbage collection lock succeeds and (b) (v.wts) > (record.min_wts).
0x09 Contention Regulation
这里主要就是cicada的减少冲突的优化。Cicada采用了Backoff的方法,为了避免每个线程根据局部的信息作出回退时间的非最优化的决定。Cicada使用全局协调的方式。一个Leader线程使用爬山法来寻址最佳的最大的回退时间,根据在一个时间段内事务吞吐量的变化不断调整(Cicada使用5ms的间隔)。最终达到一个动态的优化的值,
... It then calculates the changes of the throughput and the maximum backoff time between the second-to-last period and the last period. If the gradient (the throughput change divided by the maximum backoff time change) is positive, it increases the maximum backoff time by a fixed amount (0.5 μs in our implementation); if the gradient is negative, it decreases the maximum backoff time by the same amount. If the gradient is zero or undefined (no change in the maximum backoff time), it chooses a direction at random.
0x0A 评估
Paper中有Cicada对比其它多个类似系统的数据,这里的详细信息可以参看[1],
参考
- Cicada: Dependably Fast Multi-Core In-Memory Transactions, SIGMOD 2017.
- An Empirical Evaluation of In-Memory Multi-Version Concurrency Control, VLDB 2017.
- TicToc: Time Traveling Optimistic Concurrency Control, SIGMOD 2016.
- Low-Overhead Asynchronous Checkpointing in Main-Memory Database Systems, SIGMOD’16.
- Fast Checkpoint Recovery Algorithms for Frequently Consistent Applications, SIGMOD’11.
