Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems
0x00 引言
这篇Paper讲的是Hyper内存数据库中MVCC的实现。和前面看过的一些内存中MVCC or OCC的实现相比,Hyper数据库突出了能够处理好OLTP的任务,也能处理好OLAP的任务,在Paper中特突出了实时分析的应用。因此Hyper数据库的MVCC的设计也为这样的设计目标做了优化,
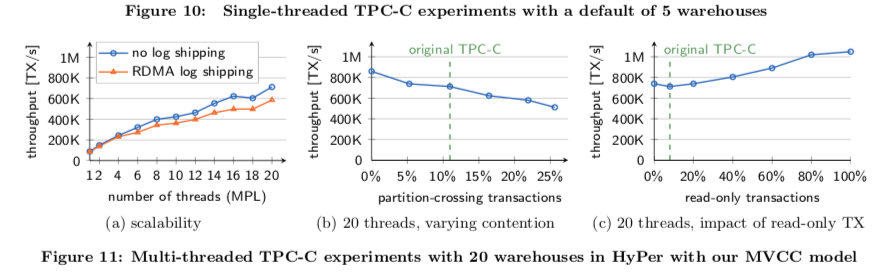
Compared to our single-version concurrency control implementation, our MVCC implementation costs around 20% of performance. Still, more than 100k transactions/s are processed. This is true for our column- and a row-based storage backends. We also compared these numbers to a 2PL implementation in HyPer and a MVCC model similar to Hekaton. 2PL is prohibitively expensive and achieves a ∼5× smaller throughput.
0x01 基本设计
Hyper的MVCC的设计没有采用每次创建一个新的版本的方法,而是使用delta链的方法。但是这里的delta链不同的地方在于不是记录向前的更新的delta,而是要访问后面的数据的时候undo的delta。Hyper的MVCC使用的是就地更新的方式,这样的方法对于一些场景特别是表扫描这样的OLAP任务特别有利。在事务提交的时候,这些delta的信息会被重新标记时间戳的信息用于确定存活的时间区间。另外Hyper通过将一个事务相关的delta数据保存在它的Undo Buffer来加快数据处理,也可以利用其来减少存储空间的使用。另外,对于一条记录的Delta的信息在数据库中使用VersionVector指明,这些信息从新到旧排序。下面的图是一个事务执行的例子,
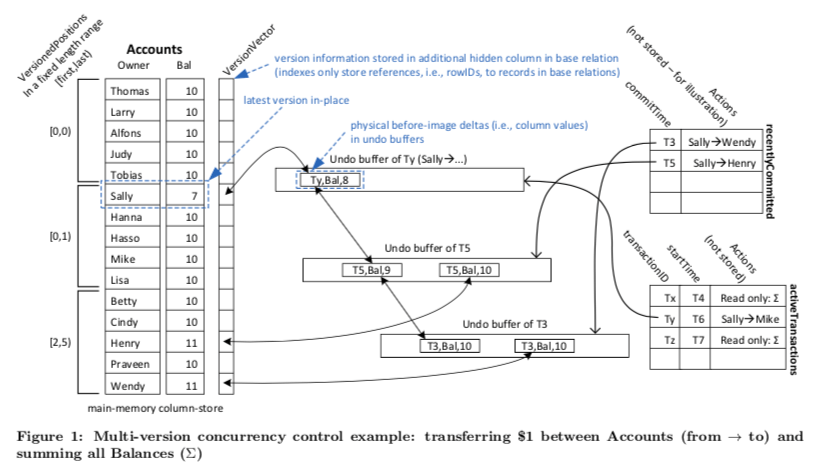
数据库中只有一小部分的数据是存在多个版本的,旧的不会再使用的版本会被垃圾回收。这里判断一个版本的数据以及过时的方式和一般的MVCC实现中使用的方式没有多大的区别。在Hyper中,一个事务的执行过程中会分三个时间戳。事务开始的时候分配一个transactionID 和 一个 startTime,在提交的时候分配一个commitTime。这里要保证transaction ID要大于startTime,而commitTime和startTime要是同一个时钟分配的。另外这些ID or 时间戳的作用也和一般MVCC中的作用系统。这里Paper中没有讨论时间戳分配的优化和溢出的问题,这个问题在前面的Cicada中说的比较多。基本设计中另外的几点,
-
一个事务为了访问一个可见版本的数据,事务首先读取in-place的记录,在需要的时候根据delta链来去掉一个版本上面的更新操作。知道第一个满足下面条件的版本, \(\\ v.pred = null \ \vee \ v.pred.TS = T \ \vee \ v.pred.TS < T.startTime. \\ \text{pred points to the predecessor; TS denotes the associated timestamp}\) 在找到之后,对应版本的数据也通过delta链undo构造出来了。
-
在一个事务提交的时候,系统就会测试垃圾回收。一次事务提交之后,系统会决定最后可见的时间戳。对一之后的事务不会在访问的数据,这些undo buffer里面的信息会被原子地从版本链中移除,暂时标记为墓碑。在后面合适的时候才会被实际回收,
Note that it is not possible to immediately reuse the memory of a marked undo buffer, as other transactions can still have references to this buffer; although the buffer is definitely not relevant for these transactions, it may still be needed to terminate version chain traversals. It is safe to reuse a marked undo buffer as soon as the oldest active transaction has started after the undo buffer had been marked. -
Hyper的MVCC的实现中,对于索引结构的修改采用了一种看上去很¯_(ツ)_/¯。如果一个更新没有涉及到索引字段,那么执行正常修改即可。如果设计到索引的字段,这里采用的方式就是删除,在添加更新之后的数据。
-
扫描的优化是Hyper数据对于OLAP场景下面的优化。Hyper使用LLVM来实现SQL的jit,以便于更加高效处理扫描之类的任务。另外还有一堆的优化方法[1].
0x02 Serializability验证
为了在SI隔离级别基础上实现Serializable的隔离级别,都会使用额外的机制。在前面的一些系统的实现上面,如 Microsoft’s Hekaton 和 PostgreSQL,都使用了read-set的方式来追踪一个事务要读取和要重新验证的记录。由于Hyper要能够很好地处理OLAP的场景。在OLAP的场景下面,读取的集合可能会非常地打,再采用这样的方式就可能导致比较大Overhead。Hyper中改用了使用undo-buffers的方法。另外Hyper还使用了一种很老的技术叫做Precision Locking来限制需要验证的对象的数量,
Thereby, we limit the validation to the number of recently changed and committed data objects, no matter how large the read set of the transaction was. For this purpose, we adapt an old technique called Precision Locking that eliminates the inherent satisfiability test problem of predicate locking. Our variation of precision locking tests discrete writes of recently committed transactions against predicate-oriented reads of the transaction that is being validated. Thus, a validation fails if such an extensional write intersects with the intensional reads of the transaction under validation
为了追踪在事务T的执行过程中被提起事务提交的extensional writes,系统中会维持一个recentlyCommitted事务的列表。这里面会有指针指向对应的undo buffers。系统会根据这里面的undo buffers信息从旧到新开始验证(在事务T startTime之后提交的事务):对于每一个undo buffer,对于每一个新创建的版本,测试是否满足事务T的谓词条件,如果存在满足条件的版本记录,则事务的读取集合中出现了不一致,所以这个事务T必须abort。对于删除的对象,检查这个对象是否在事务T的读取集合中,如果在,T同样地abort。在验证为成功之后,事务T通过写入redo-log来表示提交,然后设置commitTime时间戳。在事务abort之后,需要回滚添加进去的版本的数据。这个验证阶段是可以对个并发进行的,这些事务的序列化的顺序是通过提交时间戳来确定的。
此外,在Hyper不会实际保存读取集,而是记录谓词(predicates)的方式。另外由于Hyper不仅仅通过索引访问数据,也会通过表扫描访问数据,这个谓词的设计就要考虑到这些情况。Hyper还有的一个优化就是从检查serializability冲突的粒度上面优化,一般的实现都是在记录的粒度上面检查,但是实际上不同事务的写入可能涉及到的是不同的字段,并不会导致实际的serializability冲突。为了消除这些假性的serializability冲突,Hyper使用的粒度是字段(属性)级别的粒度。在这里保证serializability在Paper中有具体的证明[1]。
0x03 评估
这里的详细信息可以参看[1],
参考
- Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems, SIGMOD’15.
