High-Performance Concurrency Control Mechanisms for Main-Memory Databases
0x00 引言
Hekaton是微软SQL Server中内存数据库的一个部分。之后微软在这个方面发了很多的文章。这篇主要讲的是内存数据库的并发控制机制。这篇Paper中同时说明了一个多版本和单版本的实现,它们有着各自适应的环境,
... We also implemented a main-memory optimized version of single-version locking. Experimental results show that while single-version locking works well when transactions are short and contention is low performance degrades under more demanding conditions. The multiversion schemes have higher overhead but are much less sensitive to hotspots and the presence of long-running transactions.
0x01 多版本存储引擎
Paper这部分讲的多版本存储引擎的实现。 在MVCC的并发控制中,最方便实现和最常用隔离级别是SI。但是SI并不完全满足Serializability的隔离级别。为了可以支持Serializability的隔离级别,下面的两点必须要满足,1. Read stability,一个事务T在事务执行中读取的数据的版本在数据提交的时候,对这个事务可见的版本还是原来的版本;2. Phantom Avoidance,不能返回额外的新的版本的数据。对于比这个低的隔离级别旧容易实现了,
Lower isolation levels are easier to support.
1. For repeatable read, we only need to guarantee read stability.
2. For read committed, no locking or validation is required; always read the latest committed version.
3. For snapshot isolation, no locking or validation is required; always read as of the beginning of the transaction.
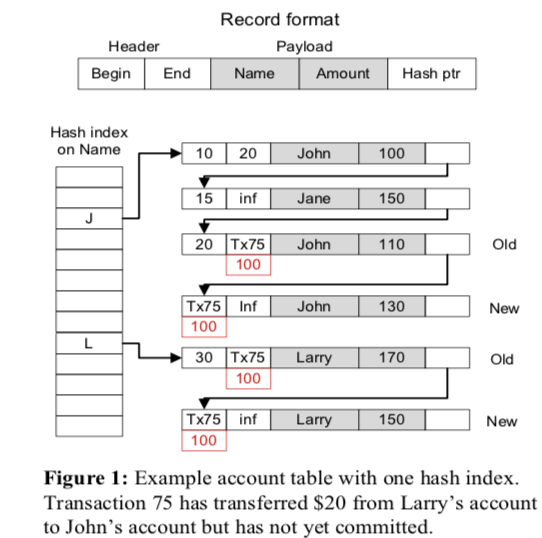
在这篇Paper中描写的多版本存储引擎的实现中,还只支持Hash索引,后面微软有发表了关于BwTree的论文,增加了支持范围查找的索引。在这个prototype中,使用了一个Lock-free的Hash Table。和常见的内存中的MVCC实现一样(这个时候还早一些),它的多版本的数据组织为一个链表。一个表可以存在多个索引,这里访问一条记录只能通过索引来访问。如果需要扫描表,可以通过扫描索引的方式。如下面的图表示的一样,与MVCC相关的三个字段为Begin、End和Hash Ptr,含义和一般的MVCC实现中的含义相同。对于一条记录的更新,总是添加一个新版本的数据。这里的版本链表中,是旧的版本在前面,而新的版本在后面。一个事务会处于4中状态中的1个:Active, Preparing, Committed, or Aborted。一个事务的执行,
- 一个事务在被创建之后,会被赋予一个开始时间戳(Begin Timestamp),这个时候状态为Active;
- 降下来就是正常处理的阶段,在这个阶段事务不会被阻塞。对于更新操作,事务会将它的TxnID设置到新版本的Begin字段中,也会设置到之前的旧版本(or 删除的版本)的End字段中。如果在这个步骤中事务abort了,进入步骤4处理。如果执行完毕准备提交,事务会请求一个End Timestamp,并进入Preparing状态;
- Preparation Phrase,准备阶段,这个阶段决定是否是提交还是abort。
- Postprocessing 阶段,如果一个事务以及提交来,则将之前设置为Begin Timestamp的字段设置为End Timestamp。如果abort了,则将两个时间戳字段都设置为无穷大,变得对事务“不可见”。在后面的操作中会被垃圾回收;
- 事务完成;
可见版本
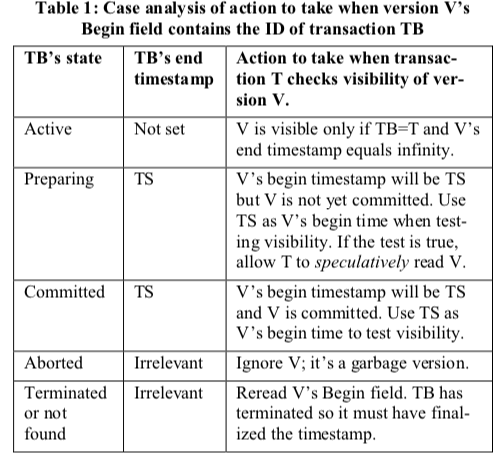
一个事务去更新一个版本数据的Version信息的时候,只有当这个版本为最新的版本的时候,才可以去更新。这里的判断方式就是这个版本的End字段为无穷大或者是对应的事务的为Abort。如果对应的事务是Active or Preparing状态,则是有写写的冲突,这里采用的是first-writer-wins的策略,另外一个事务得abort。在Begin字段和End字段包含的都是一个时间戳的时候,判断的方式很简单,就是看事务T读取的逻辑时间是不是在这个Begin和End的时间戳范围内。如果Begin字段为一个事务的ID,则判断起来麻烦一点,
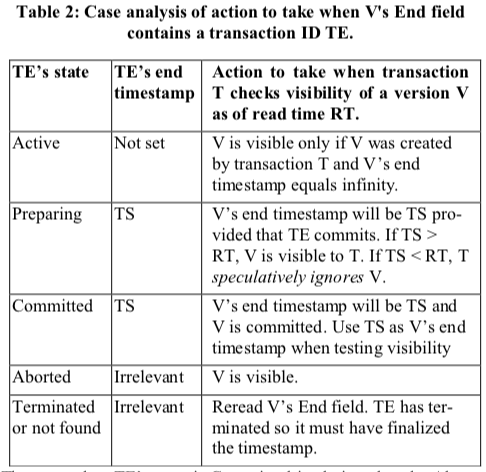
另外当End字段包含的也是事务的ID的时候也会有对应的判断方法,
这里事务提交的时候,还要处理提交依赖的问题。一个事务依赖的事务abort的时候,这个事务也必须得abort。这里使用的是register-and-report的方法,依赖于事务T2的事务T1向T2注册依赖关系,当T2提交or abort的时候会通知T1。每一个事务包含一个CommitDepCounter的计数器,统计它还有多少没解决的依赖的事务。只有当这个计数器为0的时候这个事务才可以提交。
0x02 乐观事务
乐观事务使用的是验证的方式来确保实现Serializability。这里没有采用对于其它事务的写集来验证这个事务T的读集,而是采用检查在事务要结束的时候对这个事务T可见的版本没有变化。事务T将自己的状态改为Commited就可以使得它的更新对其它的事务可见,不需要一个额外的写入操作。一个Serializab乐观事务会维持三个对象的集合,
1. ReadSet contains pointers to every version read;
2. ScanSet stores information needed to repeat every scan;
3. WriteSet contains pointers to versions updated (old and new), versions deleted (old) and versions inserted (new).
在乐观事务的Preparation阶段,这个事务要主要要做3件事情,
- 读取验证(read validation),这里主要就是检查前面要求满足的两个条件。事务T会检查ReadSet里面的对象,确保可见的版本没有变化。检查Phantoms则通过ScanSet再次扫描查找。
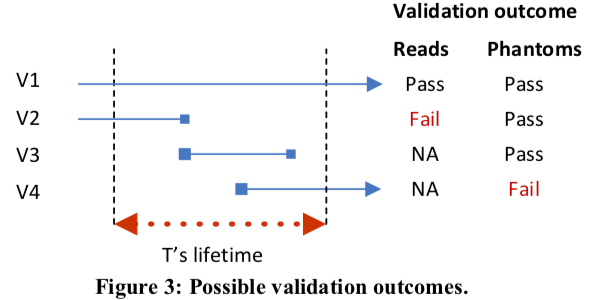
- 等待依赖的事务提交,前面阶段成功之后等待事务T依赖的事务提交or abort。
- 写日志,为了完成提交,事务T必须将WriteSet里面的信息写入持久化的Log中。
对于更低的隔离级别,实现的方式就会更简单一些:RR情况下只要验证ReadSet即可,RC则前面两个的验证都不需要,SI则这里的MVCC本来就是实现了SI,另外对于Read-only事务,可以根据情况使用SI和RC。
0x03 悲观事务
悲观事务相对于乐观事务的区别就是lock的使用,在一个事务维持的对象集合上面有一些变化,
1. ReadSet contains pointers to versions read locked by the transaction;
2. BucketLockSet contains pointers to hash buckets visited and locked by the transaction;
3. WriteSet contains references to versions updated (old and new), versions deleted (old) and versions inserted (new).
这里主要使用了两种类型的锁。RecordLocks用于实现read stability,BucketLocks(RangeLocks)用于避免Phantoms。和一般的内存数据实现的一样,这里也是没有把锁保存额外的地方,而是直接集成到了记录上面,
... the End field of a version is 64 bits. As described earlier, this field stores either a timestamp or a transaction ID with one bit indicating what the field contains. We change how we use this field to make room for a record lock.
1. ContentType (1 bit): indicates the content type of the remain- ing 63 bits
2. Timestamp (63 bits): when ContentType is zero.
3. RecordLock (63 bits): when ContentType is one.
3.1. NoMoreReadLocks (1 bit): a flag set when no further read locks are accepted. Used to prevent starvation.
3.2. ReadLockCount (8 bits): number of read locks.
3.3. WriteLock (54 bits): ID of the transaction holding a write lock on this version or infinity (max value).
事务通过ReadSet知道它对那些记录加了锁。通过递增ReadLockCount获取一条记录的读锁,这个值最大值限制为255。加写锁的分会死是设置事务T自己的ID到WriteLock中。BucketLock用锁住Hash Bucket,是一种范围锁的实现。这里还使用了一个EagerUpdate的方式,为了缓解部分由锁使用带来的开销。一个更新事务TU可以去更新一个上了读锁的记录,但是在这些锁释放之前不能提交。对于BucketLock也可以使用同样的优化的思路。
另外,使用锁的方法要处理的一个问题就是死锁,这里使用构建wait-for图的方式来分析。由于wait-for的依赖关系可能随着事务运行发生改变,这里的图可以不是完全精确的,这样可能导致检测到一些假的死锁。上面的悲观事务和乐观事务是可以同时存在的,
... Making an optimistic transaction T honor read locks and bucket locks requires the following changes:
1. When T write locks a version V, it uses only a 54-bit transaction ID and doesn’t overwrite read locks.
2. When T updates or deletes a version V that is read locked, it takes a wait-for dependency on V.
3. When T inserts a new version into a bucket B, it checks for bucket locks and takes out wait-for dependencies as needed.
0x04 评估
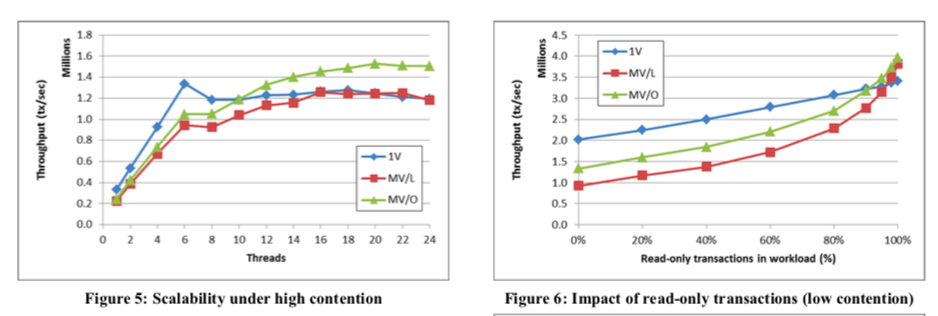
这里的具体信息可以参看[1],
参考
- High-Performance Concurrency Control Mechanisms for Main-Memory Databases, VLDB’11.
