Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last
0x00 引言
和前面的一篇[2]一样(而且这篇Paper主要的一个对比对象也是[2]),这篇Paper讲的也是内存数据库的查询处理器框架。是CMU的Peloton的一部分。现在的很多数据库使用将SQL通过JIT编译为机器码执行的方式,包含MemSQL、HyPer等,PostgreSQl也有这样的功能。一些系统实现的时候都会避免将元组物化(Materialization),来减少这个操作带来的开销。但是在这篇Paper中则认为适当的物化操作可以实现更加好的性能。在Peloton中提出的方法就是Relaxed Operator Fusion(ROF),它会在查询计划重引入临时点(staging points),在这里将中间结果临时性地物化,使得系统可以通过缓存预取、SIMD等技术实现更加好的元组间的并行性,
... Our evaluation shows that our approach reduces the execution time of OLAP queries by up to 2.2x and achieves up to 1.8x better performance compared to other in-memory DBMSs.
0x01 背景
这里就是描述了关于ROF相关的三个部分:编译、向量化和预取。
编译
将DBMS的查询编译为机器码,现在的常用的方法有两个,一个是将查询先编译为C/C++代码,然后利用外部的编译器编译为机器码,另外一个就是使用LLVM。编译为机器码最直观的方式就是将每一个操作编译为一段机器码,作为一个routine。一个操作通过调用子操作的routine获取下面的输入数据。这样的一个缺点就是会导致很多的过程调用,降低性能,这里相当于拉取的模型。在前面看过的HyPer的相关论文中,它使用的是基于推送的模型,子操作产生的结果推送给父操作,这个推送元组的数据会被(尽量)保存在CPU寄存器中。优化器会将识别出执行计划中的pipeline breaker(显性将数据保存到内存中的点),被操作元组的数据会load到CPU寄存器中,由一个breaker验证流水线操作运行到下一个breaker,在这个时候将其物化。因此这里两个breaker之间的操作都在CPU寄存器中进行。
// P1
HashTable ht; // Join Hash-Table
// Scan Part table , P
for (auto &part : P.GetTuples()) {
ht.Insert(part);
}
// P2
// Running Aggregate
Aggregator agg;
// Scan LineItem table , L
for (auto &lineitem : L.GetTuples()) {
if (PassesPredicate1(lineitem)) {
auto &part = ht.Probe(lineitem);
if (PassesPredicate2(lineitem , part)) {
agg.Aggregate(lineitem, part);
}
}
}
// P3
return agg.GetRevenue();
上面的代码是执行的例子,在P2的循环中,从一个表获取符合谓词条件和聚合操作组合在一个循环中,这个就被称为operator fusion(操作融合)。
向量化
向量化就是同时对多个数据执行相同的操作。这样就要去一次处理多条数据,这个也是现在的一些系统优化的方式。上面的例子使用SIMD优化之后的处理方式,
// P1
HashTable ht; // Join Hash-Table
// Scan Part table, P, by vectors
for (auto &block : P.GetBlocks()) {
ht.Insert(block);
}
// P2
// Running Aggregate
Aggregator agg;
// Scan LineItem table , L
for (auto &block : L.GetBlocks()) {
auto &sel_1 = PassesPredicate1(block);
auto &result = ht.Probe(block, sel_1);
auto &part_block = Reconstruct(P, result.LeftMatches());
auto &sel_2 = PassesPredicate2(block, part_block, result );
agg.Aggregate(block, part_block, sel_2);
}
// P3
return agg.GetRevenue();
预取
在一些内存访问操作比较复杂又是内存密集型的应用下,缓存预取能够获得很好的效果。预取操作可以被硬件预取、也可以被软件预取,后者就是使用显式的缓存预取指令,而硬件预取一般适应的范围比较有限。在关于MICA这样一个KVS的一篇Paper[3]中,将了预取带来的明显的性能提升,不过预取也加大了对内存带宽的需求。现在的软件预取的一些研究如Group prefetching (GP),Software-pipelined prefetching(SPP)和Asynchronous memory-access chaining(AMAC),
... Group prefetching (GP) works by processing input tuples in groups of size G. Tuples in the same group proceed through code steps in lock-step, thereby ensuring at most G simultaneous independent in-flight memory accesses. Software-pipelined prefetching (SPP) works by processing different tuples in each code step, thereby creating a fluid pipeline. Asynchronous memory-access chaining (AMAC) works by having a window of tuples in different steps of processing, swapping out tuples as soon as they complete to enable early stopping.
问题
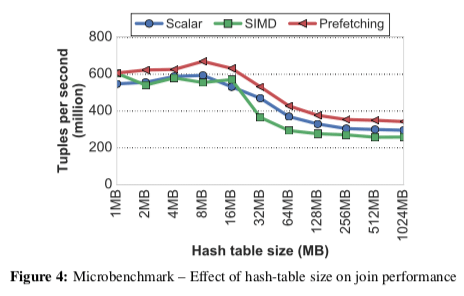
Paper中测试一一个32bit数据使用Hash Join的例子。测试了三种实现方案:(1) a scalar tuple-at-a-time join, (2) a SIMD join using the vertical vectorization technique, 和 (3) a tuple-at-a-time join modified to use group-prefetching。发现使用SIMD的实现性能没有更好,这个与实现相关,Paper中认为这个与Hash冲突的时候向量化的处理需要重新计算Hash值相关。另外,下面的图中可以看出,到Hash表大小超过LLC之后性能有一个明显下降的过程。
0x02 Relaxed Operator Fusion
操作融合的目的是减少数据物化,而每次处理一个元组的方式很难利用元组间的并行性。ROF通过放宽一个流水线内可以一次执行的操作的要求,来实现将一个流水线拆分为一个个的stage。一个stage就是流水线的一段,运算操作都融合在一起。一个流水线内的stage之间通过驻留在缓存中的元组ID的向量通信,在一个stage内,元组都是顺序处理,如果在做一个stage处理之后,元组仍然有效,其ID会添加到这一stage的输出之中。一个stage的输出向量会在满了的时候转移到流水线的下一个stage,成为下一个stage的输入。在ROF中,流水线处理过程中会一个时间点会只有一个活动的stage,就很好地保存处理的数据驻留在缓存中。ROF可以同时实现每次处理一个元组的方式和向量化的处理,前者通过将一个流水线实现为一个stage实现,而向量化处理可以通过将每一个操作分为一个stage实现。
ROF就是一种每次处理一个元组和完全向量化处理的一个混合方法,ROF与一般向量化的处理方法存在两个明显的区别,一个是ROF处理最后一次外每次都处理一个完整的向量,而一般向量化的处理方法可以限制输入向量,另外一个就是ROF支持跨越多个连续的有关联操作的向量化,而一般向量化的处理方法只能处理一个操作或者是在一些有关联的操作之内。前面这里都是很抽象晦涩的描述,另外Paper给出了前面的代码的Relaxed Operator Fusion版本,比较好地体现出Relaxed Operator Fusion相比于前面两种方式的不同,
#define VECTOR_SIZE 256
HashTable join_table; // Join Operator Table
Aggregator aggregator; // Running Aggregator
int buf[VECTOR_SIZE] = {0}; // Stage Vector
int buf_idx = 0; // Stage Vector Offset
oid tid=0;//TupleID
while (tid < L.GetNumTuples()) {
// Stage #1: Scan LineItem , L
for (buf_idx = 0; tid < L.GetNumTuples(); tid++) {
auto &lineitem = L.GetTuple(tid);
if (PassesPredicate1(lineitem)) {
buf[buf_idx++] = tid;
if (buf_idx == VECTOR_SIZE) break
}
}
// Stage #2: Probe , filter , aggregate
for (int read_idx = 0; read_idx < buf_idx; read_idx++) {
auto &lineitem = L.GetTuple(buf[read_idx]));
auto &part = join_table.Probe(lineitem);
if (PassesPredicate2(lineitem , part)) {
aggregator.Aggregate(lineitem , part);
}
}
}
/*
ROF Staged Pipeline Code Routine – The example of the pseudo- code generated for pipeline P2 in the query plan shown in Fig. 2b. In the first stage, the code fills the stage buffer with tuples from table LineItem that satisfy the scan predicate. Then in the second stage, the routine probes the join table, filters the results of the join, and aggregates the filtered results.
*/
ROF的另外的几点的信息,
- 向量化,Paper举例了一个比较的例子(attr_A < 44),如果高效地选择出满足谓词条件的元组。这里其实就是充分利用SSE/AVX中的一些指令。如果对SSE/AVX中的Compre、Permute和Mask相关的一些操作就很容易理解它大概是一些怎么样的流程。这里是一个很好的参考:https://software.intel.com/sites/landingpage/IntrinsicsGuide/。
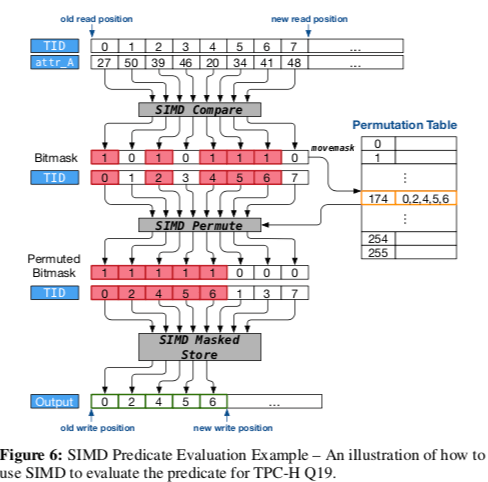
-
预取,缓存预取会增加内存带宽的需求,不合适的预取也会降低性能。ROF通过在输入中添加stage boundary实现更加好的效果,
Our ROF model avoids all of these problems. The DBMS installs a stage boundary at the input to any operator that requires random access to data structures that are larger than the cache. This ensures that prefetch-enabled operators receive a full vector of input tuples, enabling it to overlap computation and memory accesses since these tuples can be processed independently.另外,一般认为内存数据库的连接和聚合操作都使用基于Hash的方法,Paper也讨论了Hash Table的优化设计,而对于预取使用了Group prefetching (GP),实现更加简单。
0x03 评估
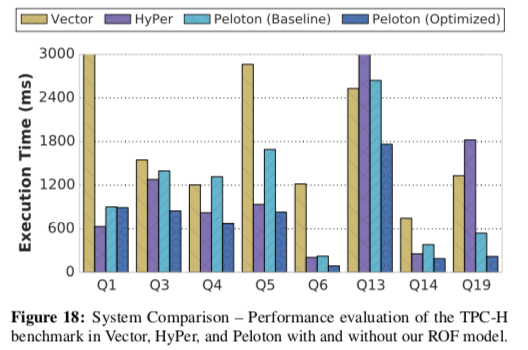
这里的具体的信息可以参看[1],
参考
- Prashanth Menon, Todd C. Mowry, Andrew Pavlo. Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last. PVLDB, 11(1): 1 - 13, 2017. DOI: https://doi.org/10.14778/3136610.3136611.
- Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age, SIGMOD’14.
- Sheng Li, Hyeontaek Lim, Victor W. Lee, Jung Ho Ahn, Anuj Kalia, Michael Kaminsky, David G. Andersen, Seongil O, Sukhan Lee, and Pradeep Dubey. 2016. Full-stack architecting to achieve a billion-requests-per- second-throughput on a single key-value store server platform. ACM Trans. Comput. Syst. 34, 2, Article 5 (April 2016), 30 pages. DOI: http://dx.doi.org/10.1145/2897393.
